
简历
给些建议,望加油:
\1. 写简历不能只站在自己角度思考,需要站在 HR 和面试官角度多多思考,这是他们需要的候选人么?如果自己是面试官,看到这份简历,自己会满意么?
\2. 如果你能理解我第一个问题,你就会意识到简历不能只有一份
\3. 简历太多 general words,如”负责处理用户使用过程中遇到的问题,数据不一致, 代码行数统计错误相关“这条,我很难看出你到底用了什么解决方案解决了这个问题,另这个问题是大问题么?可能就是个小 bug ?这些疑问过多,让我难以判断你的价值
小老弟 性格有点意思 我就说几句 你简历的问题吧
英语六级 是我觉得简历的最大亮点
学校太一般。
外包确实不好,但是你的简历呈现出外包的水准是你的问题,不是面试官的问题!
用熟悉 理解 了解 ,对个人技能 比如消息队列 多线程 并发 GC 进行描述
不要出现工具 IDEA Eclipse svn
最多写个人开发工具比如 iterm+idea+git
中间件 redis rabbitmq kafka es 等 会的写上去 ,最好要看过这些中间件特点的核心源码。不然就只能写 liaojie
springboot 这个要源码级别了解 对于你这样工作经验少的人来说,
项目描述上 用 什么样的技术方案实现什么业务场景,用什么技术,或者技术选型解决特定场景问题,诸如性能问题,查询吞吐量提升。是 star 法则的描述。
简历不要写得太八婆
简历可以用 QQ 邮箱简历模块,然后网页选择打印 就可以以 pdf 形式出来了
不聊外包是不是低下,学历会不会被筛,楼主心态够不够好,错别字是不是太多这些废话。我就说下简历怎么改会更好一些。
我认为简历应该是一个引子,是一个提纲,甚至像一个预告片,用最短的句子介绍你的工作经验,告诉面试官你具备解决哪些业务问题的能力。让面试官看完简历以后对你的能力有一个感知上的预期:
“这个人应该是知道怎么做视频直播”
“这个人对 web 富文本编辑器的经验好像还 OK”
“这个人对状态管理有自己的经验”
“这个人能把自动化测试、构建效率提升起来”
这样才产生“这个人值得一面的想法”。
不管个人能力如何,突出这些重点的简历,才算是到达了目的的简历。下面逐条说明你简历里的问题:
\1. 项目描述应该精简地说这个项目干了什么。你的表述废话太多,例如:
“产出看板项目主要是对公司个人产出的一个度量,该项目从其他各个系统采集数据,主要包括项目管理,开发,测试,设计等四个岗位人员各个指标的数据。以个人维度和部门维度来展示个人或者部门某天或者某几个月的产出活动和所作的贡献。”107 个字。
改为:“展示每个员工各项量化工作数据的考评面板。通过接入不同岗位的数据库完成数据的采集。”40 个字。
一句话讲清楚这个系统就是一个用来展示量化后的工作产出的面板。
那么这个系统的核心就是量化的工作数据,自然看简历的人就会有疑问,这些数据是哪里来的?是需要主动录入到你这个系统,还是你这个系统从别的地方采集的?因为这决定了这个项目的复杂度。
那么第二句话就解释了这个可能的疑问:是从其他系统采集来的。
这样面试官就能获得一个信息“这个人是知道不同的后台业务系统之间是怎么通信的”。
再回过头看那 107 个字的原表述,有两句废话,分别可以归纳为“杂余信息”和“复读常识”两点。
1.1 杂余信息
比如“要包括项目管理,开发,测试,设计等四个岗位人员各个指标的数据”,就是不重要的杂余细节,面试官不关心你们公司到底有多少种不同的岗位。当然,如果在处理“接入不同岗位的数据库”这件事时,因为岗位不同而作了一些兼容逻辑并且做的也不错的话,可以在面试的时候详细展开。这是值得讲的。
1.2 复读常识
比如“以个人维度和部门维度来展示个人或者部门某天或者某几个月的产出活动和所作的贡献.”,这就是一句话废话。这不就是“工作产出”吗?
我知道你想说这个面板可以以月 /日、人 /部门等不同纬度去查看工作产出,可这难道不是一个考评面板本该有的基本能力吗?房产中介会跟你提房子的采光、通风、学区,但他不会和你强调“这个房子是有厕所的”。
再比如“畜牧专家电商平台”这个项目,原表述是 122 个字,可以改为“兽药商城、问答社区、咨询阅读”。
那么面试官大致就会知道,这个人做过商城、问答、文章阅读这些业务,也就对你会掌握的一些能力有一个大致的预期。
(虽然我觉得你这个项目应该水分很大,商城和问答都是很重的业务,怎么可能放在一起都做了。)
\2. 技术架构不是堆砌技术词汇。架构二字至少从中文上理解,也是一个结构性的东西,陈列“springboot+Tomcat+Mysql+git+Maven” 5 个技术词汇只能说你用到了这些工具,不能称之为架构,你这么写反而显得你非常不专业。比如产出面板这个项目其实就简单到没什么所谓的架构值得一提,你就不应该单独列出来。
\3. “负责内容”首先要写清晰,到达清晰了再去追求“写出亮点”。下面举几个不清晰的例子:
- “负责技术文章模块的开发,富文本编辑器, 实现了文章的新增编辑和查找, 同时支持用户对文章评论功能”
其实你只是做了文章的发布、搜索和评论(应该就是很简单的搜索),富文本编辑器应该是你直接用了第三方的库。但是你“技术文章模块的开发,富文本编辑器”这样的表述会让人一眼扫过去,以为富文本编辑器是你做的,但是细品了一下会想到这估计不可能,进而产生这个人在给工作内容灌水的感觉。
- “对于一些商品重复显示的页面, 为了提高效率降低代码重复率, 采用了 freemarker 页面静态技术优化”
这句话完全是不可理解的,我看到以后脑子里只有三个问号:
商品在页面里重复显示不是很正常的吗?一个商品出现在搜索结果里的同时可能也会出现在侧栏的推荐位里啊
这和代码重复率有什么关系?
freemarker 又是什么?
HTML 页面本身不就是静态的吗?静态技术优化这种只在特定语境里才能理解的抽象的、自我发明的技术词汇究竟是什么?
如果简历是一份代码的话,我现在要给你报 5 个 not undefined 的 Error 。
- “负责合同管理工作流对应的数据表对应关系,及相关业务逻辑代码的编写”
你做了相关业务逻辑的编写,那你写的应该是“实现工作流和数据表的对应”吧。你没解释工作流是什么,数据表又是什么,以及为什么需要这个对应关系。全靠人猜,而且很难猜。
以及,对应关系就是在数据层面做了一个关联吧?难点在哪里?你没有解释清楚,是时效性的维护?还是一致性的维护?我猜不出来,看你简历的人更没耐心去猜。
总之负责内容这块看下来,直觉就是很不清晰。靠自己去猜了一下你实际上做的工作内容是什么,然后感觉比较碎、有些水。
但是可以先做到把工作内容讲清楚,无论如何这是第一步。
4 用 xx 第三方库实现了 xx 这种就不要写了,比如法务系统里那个“合同页面导出到 word”。这不是你做的,是这个 xx 库做的,你只是一个搬运工。除非这个第三方库有坑,你改这个库或者做了一层 cover 把坑填了,这才值得写。
5.版本管理工具这种就不要提了。还是那句话,不要复读常识。当然除非你在工作中根据自己的项目情况制定了一套类似 git flow 的版本管理经验,这才值得写。
自我介绍
你好,我叫李博,木子李,博士的博。94年的,今年是26。籍贯是陕西。
17年毕业于延安大学,专业是信息与计算科学。
毕业后就来了深圳工作,到目前为止是有三年多的工作经验。
平常工作中主要使用的是 Spring Boot、MyBatis 等框架,数据库使用过关系型的 MySQL 和 Oracle,文档型的使用过 MongDB,以及内存型的数据库 Redis。
目前最近的项目是前后端分离开发的项目,后端使用的 Spring Cloud 的微服务架构,前段使用的是 Vue.js 结合 Element-UI 组件库开发的。
大体的情况就是这些。
编程思想
OPP
面向过程编程(英语:Procedure-oriented Programming,缩写:OPP)
OOP
面向对象编程(英语:Object-oriented programming,缩写:OOP)
OPP vs OOP
面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
而面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
三大特征
面向对象的三大特征:封装、继承、多态
封装
把数据以及对数据的操作封装在一个类里。
继承
多态
父类引用指向子类对象。
AOP
在软件行业,AOP 为 Aspect Oriented Programming 的缩写,意为:面向切面编程
Spring AOP 的实现原理:动态代理
数据结构
布隆过滤器
布隆过滤器是一种用来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
布隆过滤器(Bloom Filter)是由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。
插入操作
- 使用哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
判断一个元素是否存在
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
使用场景
判断给定数据是否存在:
- 比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5亿以上!)
- 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)
- 邮箱的垃圾邮件过滤
- 黑名单功能
去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
实现
Google Guava 的布隆过滤器
创建了一个最多存放 1500 个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之一(0.01)
1 | // 创建布隆过滤器对象 |
Redis 中的布隆过滤器
Guava 提供的布隆过滤器的实现只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,就需要用到 Redis 中的布隆过滤器了。
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。
官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module。
常用命令
BF.ADD:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:BF.ADD {key} {item}。BF.MADD: 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式BF.ADD与之相同,只不过它允许多个输入并返回多个值。格式:BF.MADD {key} {item} [item ...]。BF.EXISTS: 确定元素是否在布隆过滤器中存在。格式:BF.EXISTS {key} {item}。BF.MEXISTS: 确定一个或者多个元素是否在布隆过滤器中存在格式:BF.MEXISTS {key} {item} [item ...]。
使用
1 | 127.0.0.1:6379> BF.ADD myFilter java |
B 树
B树(balance tree)可以认为是 m 叉的多路平衡查找树
B+ 树
B树和B+树的区别
- B+树的中间节点不保存数据,只在叶子结点中保存数据;而B树数据分布在整颗树中。
- B+树的叶子结点按顺序链接,可以很方便的进行范围查找。
红黑树
5 个特性
- 每个节点要么是红色,要么是黑色;
- 根节点永远是黑色的;
- 所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
- 每个红色节点的两个子节点一定都是黑色;
- 从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
HashMap 为什么要使用红黑树?
红黑树是基于二叉查找树的改造,二叉查找树具有平衡性和有序性的特点,能够支持快速的查找功能,但完全平衡树的维护成本比较高,红黑树采用的“适度平衡”标准,可以保证每次插入或删除操作后的重平衡过程,全树拓扑结构的更新仅涉及常数个节点。尽管最坏情况下需对多达logn个节点重染色,但就分摊意义而言仅为O(1)个。
算法
KMP 算法
谈到字符串问题,不得不提的就是 KMP 算法,它是用来解决字符串查找的问题,可以在一个字符串(S)中查找一个子串(W)出现的位置。KMP 算法把字符匹配的时间复杂度缩小到 O(m+n) ,而空间复杂度也只有O(m)。因为“暴力搜索”的方法会反复回溯主串,导致效率低下,而KMP算法可以利用已经部分匹配这个有效信息,保持主串上的指针不回溯,通过修改子串的指针,让模式串尽量地移动到有效的位置。
排序算法
排序算法的成本模型是比较和交换的次数。
选择排序
从数组中选择最小元素,将它与数组的第一个元素交换位置。再从数组剩下的元素中选择出最小的元素,将它与数组的第二个元素交换位置。不断进行这样的操作,直到将整个数组排序。
选择排序需要 ~N2/2 次比较和 ~N 次交换,它的运行时间与输入无关,这个特点使得它对一个已经排序的数组也需要这么多的比较和交换操作。
1 | public class Selection<T extends Comparable<T>> extends Sort<T> { |
冒泡排序
从左到右不断交换相邻逆序的元素,在一轮的循环之后,可以让未排序的最大元素上浮到右侧。
在一轮循环中,如果没有发生交换,那么说明数组已经是有序的,此时可以直接退出。
1 | public class Bubble<T extends Comparable<T>> extends Sort<T> { |
插入排序
每次都将当前元素插入到左侧已经排序的数组中,使得插入之后左侧数组依然有序。
对于数组 {3, 5, 2, 4, 1},它具有以下逆序:(3, 2), (3, 1), (5, 2), (5, 4), (5, 1), (2, 1), (4, 1),插入排序每次只能交换相邻元素,令逆序数量减少 1,因此插入排序需要交换的次数为逆序数量。
插入排序的时间复杂度取决于数组的初始顺序,如果数组已经部分有序了,那么逆序较少,需要的交换次数也就较少,时间复杂度较低。
- 平均情况下插入排序需要 ~N2/4 比较以及 ~N2/4 次交换;
- 最坏的情况下需要 ~N2/2 比较以及 ~N2/2 次交换,最坏的情况是数组是倒序的;
- 最好的情况下需要 N-1 次比较和 0 次交换,最好的情况就是数组已经有序了。
1 | public class Insertion<T extends Comparable<T>> extends Sort<T> { |
希尔排序
对于大规模的数组,插入排序很慢,因为它只能交换相邻的元素,每次只能将逆序数量减少 1。希尔排序的出现就是为了解决插入排序的这种局限性,它通过交换不相邻的元素,每次可以将逆序数量减少大于 1。
希尔排序使用插入排序对间隔 h 的序列进行排序。通过不断减小 h,最后令 h=1,就可以使得整个数组是有序的。
1 | public class Shell<T extends Comparable<T>> extends Sort<T> { |
希尔排序的运行时间达不到平方级别,使用递增序列 1, 4, 13, 40, … 的希尔排序所需要的比较次数不会超过 N 的若干倍乘于递增序列的长度。后面介绍的高级排序算法只会比希尔排序快两倍左右。
归并排序
归并排序的思想是将数组分成两部分,分别进行排序,然后归并起来。
1. 归并方法
归并方法将数组中两个已经排序的部分归并成一个。
1 | public abstract class MergeSort<T extends Comparable<T>> extends Sort<T> { |
2. 自顶向下归并排序
将一个大数组分成两个小数组去求解。
因为每次都将问题对半分成两个子问题,这种对半分的算法复杂度一般为 O(NlogN)。
1 | public class Up2DownMergeSort<T extends Comparable<T>> extends MergeSort<T> { |
3. 自底向上归并排序
先归并那些微型数组,然后成对归并得到的微型数组。
1 | public class Down2UpMergeSort<T extends Comparable<T>> extends MergeSort<T> { |
快速排序
1. 基本算法
- 归并排序将数组分为两个子数组分别排序,并将有序的子数组归并使得整个数组排序;
- 快速排序通过一个切分元素将数组分为两个子数组,左子数组小于等于切分元素,右子数组大于等于切分元素,将这两个子数组排序也就将整个数组排序了。
1 | public class QuickSort<T extends Comparable<T>> extends Sort<T> { |
2. 切分
取 a[l] 作为切分元素,然后从数组的左端向右扫描直到找到第一个大于等于它的元素,再从数组的右端向左扫描找到第一个小于它的元素,交换这两个元素。不断进行这个过程,就可以保证左指针 i 的左侧元素都不大于切分元素,右指针 j 的右侧元素都不小于切分元素。当两个指针相遇时,将切分元素 a[l] 和 a[j] 交换位置。
1 | private int partition(T[] nums, int l, int h) { |
3. 性能分析
快速排序是原地排序,不需要辅助数组,但是递归调用需要辅助栈。
快速排序最好的情况下是每次都正好将数组对半分,这样递归调用次数才是最少的。这种情况下比较次数为 CN=2CN/2+N,复杂度为 O(NlogN)。
最坏的情况下,第一次从最小的元素切分,第二次从第二小的元素切分,如此这般。因此最坏的情况下需要比较 N2/2。为了防止数组最开始就是有序的,在进行快速排序时需要随机打乱数组。
4. 算法改进
4.1 切换到插入排序
因为快速排序在小数组中也会递归调用自己,对于小数组,插入排序比快速排序的性能更好,因此在小数组中可以切换到插入排序。
4.2 三数取中
最好的情况下是每次都能取数组的中位数作为切分元素,但是计算中位数的代价很高。一种折中方法是取 3 个元素,并将大小居中的元素作为切分元素。
4.3 三向切分
对于有大量重复元素的数组,可以将数组切分为三部分,分别对应小于、等于和大于切分元素。
三向切分快速排序对于有大量重复元素的随机数组可以在线性时间内完成排序。
1 | public class ThreeWayQuickSort<T extends Comparable<T>> extends QuickSort<T> { |
5. 基于切分的快速选择算法
快速排序的 partition() 方法,会返回一个整数 j 使得 a[l..j-1] 小于等于 a[j],且 a[j+1..h] 大于等于 a[j],此时 a[j] 就是数组的第 j 大元素。
可以利用这个特性找出数组的第 k 个元素。
该算法是线性级别的,假设每次能将数组二分,那么比较的总次数为 (N+N/2+N/4+..),直到找到第 k 个元素,这个和显然小于 2N。
1 | public T select(T[] nums, int k) { |
堆排序
1. 堆
堆中某个节点的值总是大于等于或小于等于其子节点的值,并且堆是一颗完全二叉树。
堆可以用数组来表示,这是因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。这里不使用数组索引为 0 的位置,是为了更清晰地描述节点的位置关系。
1 | public class Heap<T extends Comparable<T>> { |
2. 上浮和下沉
在堆中,当一个节点比父节点大,那么需要交换这个两个节点。交换后还可能比它新的父节点大,因此需要不断地进行比较和交换操作,把这种操作称为上浮。
1 | private void swim(int k) { |
类似地,当一个节点比子节点来得小,也需要不断地向下进行比较和交换操作,把这种操作称为下沉。一个节点如果有两个子节点,应当与两个子节点中最大那个节点进行交换。
1 | private void sink(int k) { |
3. 插入元素
将新元素放到数组末尾,然后上浮到合适的位置。
1 | public void insert(Comparable v) { |
4. 删除最大元素
从数组顶端删除最大的元素,并将数组的最后一个元素放到顶端,并让这个元素下沉到合适的位置。
1 | public T delMax() { |
5. 堆排序
把最大元素和当前堆中数组的最后一个元素交换位置,并且不删除它,那么就可以得到一个从尾到头的递减序列,从正向来看就是一个递增序列,这就是堆排序。
5.1 构建堆
无序数组建立堆最直接的方法是从左到右遍历数组进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。
5.2 交换堆顶元素与最后一个元素
交换之后需要进行下沉操作维持堆的有序状态。
1 | public class HeapSort<T extends Comparable<T>> extends Sort<T> { |
6. 分析
一个堆的高度为 logN,因此在堆中插入元素和删除最大元素的复杂度都为 logN。
对于堆排序,由于要对 N 个节点进行下沉操作,因此复杂度为 NlogN。
堆排序是一种原地排序,没有利用额外的空间。
现代操作系统很少使用堆排序,因为它无法利用局部性原理进行缓存,也就是数组元素很少和相邻的元素进行比较和交换。
小结
1. 排序算法的比较
| 算法 | 稳定性 | 时间复杂度 | 空间复杂度 | 备注 |
|---|---|---|---|---|
| 选择排序 | × | N2 | 1 | |
| 冒泡排序 | √ | N2 | 1 | |
| 插入排序 | √ | N ~ N2 | 1 | 时间复杂度和初始顺序有关 |
| 希尔排序 | × | N 的若干倍乘于递增序列的长度 | 1 | 改进版插入排序 |
| 快速排序 | × | NlogN | logN | |
| 三向切分快速排序 | × | N ~ NlogN | logN | 适用于有大量重复主键 |
| 归并排序 | √ | NlogN | N | |
| 堆排序 | × | NlogN | 1 | 无法利用局部性原理 |
快速排序是最快的通用排序算法,它的内循环的指令很少,而且它还能利用缓存,因为它总是顺序地访问数据。它的运行时间近似为 ~cNlogN,这里的 c 比其它线性对数级别的排序算法都要小。
使用三向切分快速排序,实际应用中可能出现的某些分布的输入能够达到线性级别,而其它排序算法仍然需要线性对数时间。
动态规划
推荐算法
Java 语言
基础
多态
多态的三个条件:
- 要有继承关系
- 子类要重写父类的方法
- 父类引用指向子类对象
为什么说 Java 语言“编译与解释并存”?
高级编程语言按照程序的执行方式分为编译型和解释型两种。简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(*.class 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存。
Java中的几种基本数据类型是什么?对应的包装类型是什么?各自占用多少字节呢?
Java中有8种基本数据类型,分别为:
- 6种数字类型 :byte、short、int、long、float、double
- 1种字符类型:char
- 1种布尔型:boolean。
这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean
| 基本类型 | 位数 | 字节 | 默认值 |
|---|---|---|---|
| int | 32 | 4 | 0 |
| short | 16 | 2 | 0 |
| long | 64 | 8 | 0L |
| byte | 8 | 1 | 0 |
| char | 16 | 2 | ‘u0000’ |
| float | 32 | 4 | 0f |
| double | 64 | 8 | 0d |
| boolean | 1 | false |
为什么 Java 中只有值传递?
Java 对对象的传递,传递的是对象引用的一份拷贝,虽然会可以通过引用修改对象的状态,但出了方法后原变量的引用并没有改变,即对象引用是按值传递的。
包装类
哪些地方会自动拆装箱
- 将基本数据类型放入集合类
- 包装类型和基本类型的大小比较
- 包装类型的运算
- 函数参数与返回值
java 是否存在使得语句 i > j || i <= j 结果为 false 的 i、j 值?
存在,java 的数值 NaN 代表 not a number,无法用于比较,例如使 i = Double.NaN; j = i; 最后 i == j 的结果依旧为 false。
反射
序列化
泛型
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
JVM
运行时数据区域
JDK 1.8 之前:

JDK 1.8 :

虚拟机栈
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
从方法调用直至执行完成的过程,对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
堆
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC 堆(Garbage Collected Heap).从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
在 JDK 7 版本及JDK 7 版本之前,堆内存被通常被分为下面三部分:
- 新生代内存(Young Generation)
- 老生代(Old Generation)
- 永生代(Permanent Generation)

JDK 8 版本之后方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。

对象头
Hotspot的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
| 状态 | 存储内容 | 锁标记 |
|---|---|---|
| 无锁 | 对象的hashCode、对象分代年龄、是否是偏向锁(0) | 01 |
| 偏向锁 | 偏向线程ID、偏向时间戳、对象分代年龄、是否是偏向锁(1) | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 00 |
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 10 |
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
方法区
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
方法区也被称为永久代。很多人都会分不清方法区和永久代的关系,为此我也查阅了文献。
方法区和永久代的关系
《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久代这一说法。
对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有①使用句柄和②直接指针两种:
- 句柄: 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
![对象的访问定位-使用句柄]()
- 直接指针: 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。


这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。
类加载机制
类的生命周期/类加载过程
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括 7 个阶段。其中准备、验证、解析 3 个部分统称为连接(Linking)。
加载(loading) –> 验证(Verification) –>准备(Preparation) –> 解析(Resolution) –> 初始化(Initialization) –> 使用(Using) –> 卸载(Unloading)
加载
将 .class 文件加载到 JVM 运行时数据区的方法区内,然后在堆中创建一个 java.lang.Class 对象,用来封装类在方法区内的数据结构。
.class 文件来源:
- 本地磁盘
- 网络下载
- zip、jar 等归档文件中
- 数据库
- 动态编译 Java 源文件
验证
验证的目的是为了确保 Class 文件中的字节流包含的信息符合当前虚拟机的要求,而且不会危害虚拟机自身的安全。
包括以下四个阶段的验证:
文件格式的验证
是否以
0xCAFEBABE开头、主次版本号是否在当前虚拟机的处理范围之内、常量池中的常量是否有不被支持的类型。元数据的验证
对字节码描述的信息进行语义分析。例如:这个类是否有父类,除了java.lang.Object 之外。
字节码验证
通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。
符号引用验证
准备
为类的静态变量分配内存,并根据数据类型将其初始化为默认的零值(注意不是程序中设置的值)
注意:如果是常量(static final),且在声明时就指定了初始值,则会直接赋值为指定值。
解析
将常量池中的符号引用转换为直接引用。
初始化
初始化类变量
类初始化时机:
- 创建类的实例,也就是 new 一个对象
- 访问某个类或接口的静态变量
- 调用类的静态方法
- 反射
Class.forName("") - 初始化一个类的子类(会首先初始化子类的父类)
- JVM 启动时标明的启动类
类加载器
分类
启动类加载器
负责加载
JAVA_HOME\lib目录中能被虚拟机识别的类,可以通过Launcher.getBootstrapClassPath().getURLs()查看。由 C++ 实现,无法被 Java 程序直接引用。
扩展类加载器
负责加载
JAVA_HOME\lib\ext目录下的类应用类加载器
责加载用户类路径(ClassPath)所指定的类
继承关系
通过组合的方式实现的继承关系。
启动类加载器没有父类
扩展类加载器的父类为 null
应用类加载器继承自扩展类加载器
自定义类加载器继承自引用类加载器
双亲委派模型
当类加载器收到了类加载的请求,它首先把请求委托给父加载器去完成,当父加载器无法加载时,子加载器才会尝试自己去加载该类。
意义
- 防止重复加载
- 保证 Java 基础类的安全性
双亲委派模型的破坏者-线程上下文类加载器
在Java应用中存在着很多服务提供者接口(Service Provider Interface,SPI),这些接口允许第三方为它们提供实现,如常见的 SPI 有 JDBC、JNDI 等,这些 SPI 的接口属于 Java 核心库,一般存在 rt.jar 包中,由 Bootstrap 类加载器加载,而 SPI 的第三方实现代码则是作为Java应用所依赖的 jar 包被存放在 classpath 路径下,由于启动类加载器无法直接加载 SPI 的实现类,同时由于双亲委派模式的存在,Bootstrap 类加载器也无法反向委托AppClassLoader 加载器SPI的实现类。在这种情况下,我们就需要线程上下文类加载器。
线程上下文类加载器(contextClassLoader)可以通过java.lang.Thread 类中的getContextClassLoader() 和 setContextClassLoader(ClassLoader cl) 方法来获取和设置线程的上下文类加载器。如果没有手动设置上下文类加载器,线程将继承其父线程的上下文类加载器,初始线程的上下文类加载器是应用类加载器,在线程中运行的代码可以通过此类加载器来加载类和资源。
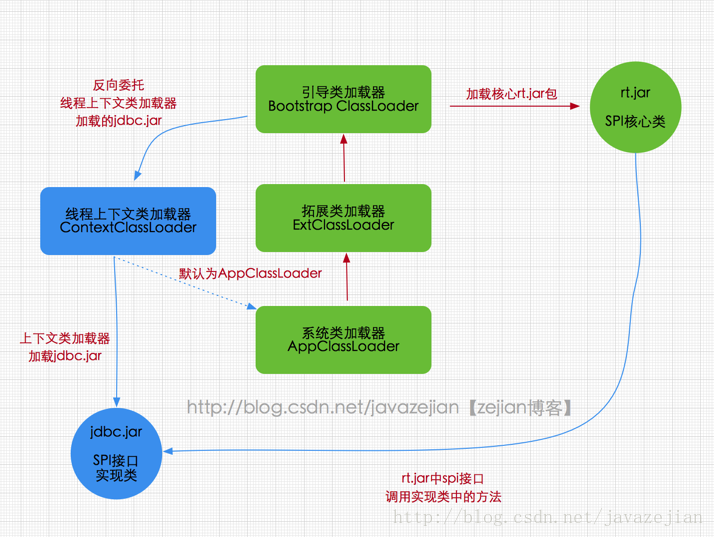
“破坏”是指破坏了父类加载器无法加载子类加载器范围的类这样的规则。
就是通过在父类加载器中使用 Thread.getContextClassLoader() 获取到子类加载器,然后再调用子类加载器的 findClass() 方法去加载。
内存分配

大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置。
Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。
大对象直接进入老年代
为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
分配担保机制就是进行了 Minor GC 还是无法满足,则将对象存到老年代。
垃圾回收过程
- 那些内存需要回收?(对象是否可以被回收的两种经典算法: 引用计数法 和 可达性分析算法)
- 什么时候回收?(堆的新生代、老年代、永久代的垃圾回收时机,MinorGC 和 FullGC)
- 如何回收?(三种经典垃圾回收算法(标记清除算法、复制算法、标记整理算法)及分代收集算法 和 七种垃圾收集器)
监测垃圾对象

引用计数法
这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。
可达性分析算法
可作为GC Roots的对象包括下面几种:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈(Native方法)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
引用
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
1.强引用(StrongReference)
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用(SoftReference)
如果一个对象只具有软引用,那就类似于可有可无的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
3.弱引用(WeakReference)
如果一个对象只具有弱引用,那就类似于可有可无的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4.虚引用(PhantomReference)
“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
虚引用主要用来跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
如何判断一个类是无用的类
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 “无用的类” :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader已经被回收。 - 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
垃圾收集算法

标记-清除算法
该算法分为“标记”和“清除”阶段:首先标记出所有不需要回收的对象,在标记完成后统一回收掉所有没有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
- 效率问题
- 空间问题(标记清除后会产生大量不连续的碎片)

复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。

标记-整理算法
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。

分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
JVM 两种模式的区别
JVM工作在Server模式可以大大提高性能,但应用的启动会比client模式慢大概10%。
最主要的差别在于:-Server模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。原因是:
当虚拟机运行在-client模式的时候,使用的是一个代号为C1的轻量级编译器,而-server模式启动的虚拟机采用相对重量级,代号为C2的编译器。C2比C1编译器编译的相对彻底,服务起来之后,性能更高。
垃圾收集器

如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
Serial 收集器
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 “单线程” 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( “Stop The World” ),直到它收集结束。
新生代采用复制算法,老年代采用标记-整理算法。 
虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短。
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它简单而高效(与其他收集器的单线程相比)。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
ParNew 收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。
新生代采用复制算法,老年代采用标记-整理算法。 
它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器)配合工作。
并行和并发概念补充:
- 并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
Parallel Scavenge 收集器
Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和ParNew一样。
1 | -XX:+UseParallelGC |
Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。 Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用Parallel Scavenge收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
新生代采用复制算法,老年代采用标记-整理算法。 
是JDK1.8默认收集器
使用 java -XX:+PrintCommandLineFlags -version命令查看
1 | -XX:InitialHeapSize=262921408 -XX:MaxHeapSize=4206742528 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC |
JDK1.8 默认使用的是Parallel Scavenge + Parallel Old,如果指定了-XX:+UseParallelGC参数,则默认指定了-XX:+UseParallelOldGC,可以使用-XX:-UseParallelOldGC来禁用该功能
Serial Old 收集器
Serial 收集器的老年代版本,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
Parallel Old 收集器
Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
从名字中的Mark Sweep这两个词可以看出,CMS 收集器是一种 “标记-清除”算法实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
- 初始标记: 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
- 并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- 重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
- 并发清除: 开启用户线程,同时 GC 线程开始对未标记的区域做清扫。

从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:并发收集、低停顿。但是它有下面三个明显的缺点:
- 对 CPU 资源敏感;
- 无法处理浮动垃圾;
- 它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。
G1 收集器
G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
- 并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
- 分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
- 空间整合:与 CMS 的“标记–清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
- 可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
G1 收集器的运作大致分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
JDK 监控和故障处理工具
JDK 命令行工具
这些命令在 JDK 安装目录下的 bin 目录下:
jps(JVM Process Status): 类似 UNIX 的ps命令。用户查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息;jstat( JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据;jinfo(Configuration Info for Java) : Configuration Info forJava,显示虚拟机配置信息;jmap(Memory Map for Java) :生成堆转储快照;jhat(JVM Heap Dump Browser ) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果;jstack(Stack Trace for Java):生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
JDK 可视化分析工具
JConsole:Java 监视与管理控制台
JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监视本地及远程服务器的 java 进程的内存使用情况。你可以在控制台输出console命令启动或者在 JDK 目录下的 bin 目录找到jconsole.exe然后双击启动。
Visual VM:多合一故障处理工具
VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java 应用程序的详细信息。在 VisualVM 的图形用户界面中,您可以方便、快捷地查看多个 Java 应用程序的相关信息。
synchronized 锁
synchronized通过Monitor来实现线程同步,Monitor是依赖于底层操作系统的Mutex Lock(互斥锁)来实现的线程同步。
锁一共四种状态,级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
锁状态存放在JVM对象头中的 Mark Word 中。
无锁
无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点就是修改操作在循环内进行,CAS原理及应用即是无锁的实现。
偏向锁
在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
当一个线程访问同步代码块并获取锁时,会在Mark Word里存储锁偏向的线程ID。在线程进入和退出同步块时不是通过CAS操作来加锁和解锁,而是检测Mark Word里是否存储着指向当前线程的偏向锁。
引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
轻量级锁
是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
在代码进入同步块的时候,如果同步对象锁状态为无锁状态,虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,然后拷贝对象头中的Mark Word复制到锁记录中。
拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。
如果此时有另一个新线程请求锁,虚拟机会检查对象的Mark Word是否指向该线程的栈帧,没有则说明多个线程竞争锁。该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。
重量级锁
升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁(monitor)的指针,此时等待锁的线程都会进入阻塞状态。
总结
偏向锁通过对象头的Mark Word存储线程ID来减少过多的CAS操作,提高在无竞争环境下的Synchronized效率。
轻量级锁则是通过CAS自旋等待来避免线程的阻塞和唤醒操作,提高在竞争不激烈环境下synchronized的效率。
Synchronized和ReentrantLock在唤醒被挂起线程竞争的时候有什么区别?
Synchronized和ReentrantLock他们的开销差距是在释放锁时唤醒线程的数量,Synchronized是唤醒锁池里所有的线程+刚好来访问的线程,而ReentrantLock则是当前线程后进来的第一个线程+刚好来访问的线程.
ReentrantLock
ReentrantLock上锁的时候如果只有一个线程进来,是不会有线程挂起的操作的,也就是说只需要在AQS里使用CAS改变一个state的值为1
集合框架
Collection
| 线程不安全 | 线程安全 |
|---|---|
| Arraylist | Vector/CopyOnWriteArrayList |
| LinkedList | ConcurrentLinkedQueue |
| HashMap | ConcurrentHashMap |
List
ArrayList
扩容机制
- 以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
- int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
Arraylist 与 LinkedList 区别?
- 底层数据结构:
Arraylist底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
- 插入和删除是否受元素位置的影响: ①
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ②LinkedList采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。 - 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用: ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
Set
HashSet
HashSet 底层就是基于 HashMap 实现的。set 中的元素作为 key 存储在 hashmap 中,value 对应set中定义的同一个 Object。
Map
HashMap
put 流程

- 计算 key 的 hash 值(hashcode 高位抑或运算)
- 判断哈希表是否为空,如果为空则进行
resize() - 根据 hash 值计算数组下标,查看数组对应位置是否有值,没有就直接创建新节点存入
- 如果存在值则判断 hash 值是否相等、key 是否 equal,如果相等则覆盖旧值。
- 如果不等,则判断是否是红黑树节点,如果是则进入红黑树 put 操作。
- 如果不是则表示为链表,循环遍历链表进行插入操作
- 插入后链表后,链表长度如果大于 8,而哈希表数组长度小于 64,则扩容后 reHash,数组长度大于 64,则将链表转化为红黑树
- 最后
++modCount,++size,如果size 大与阀值则进行resize()。
哈希表数组长度为什么必须为 2 的幂次方?
为了通过减法结合按位与操作代替取模运算提高性能。
a % b == (b-1) & a
而只有当 b 是 2 的指数时,等式才成立。
为什么要把 hashcode 与其高位进行抑或运算?
为了减少哈希碰撞。
HashMap 和 Hashtable 的区别
- 线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的,因为 HashTable 内部的方法基本都经过
synchronized修饰。 - 效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对 Null key 和 Null value 的支持: HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;HashTable 不允许有 null 键和 null 值,否则会抛出 NullPointerException。
- 初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小。
- 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
HashMap 和 TreeMap 区别
TreeMap 和HashMap 都继承自AbstractMap ,但是需要注意的是TreeMap它还实现了NavigableMap接口和SortedMap 接口。
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现SortMap接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。
ConcurentHashMap
1.8以前的ConcurrentHashMap 的时候, 会初始化一个Segment数组, 容量为16,每个Segment都继承了ReentrantLock类,也就是说每个Segment类本身就是一个锁,之后Segment内部又有一个table数组,而每个table数组里的索引数据又对应着一个HashEntry链表.
ConcurrentHashMap1.8为什么用CAS+Synchronized取代Segment+ReentrantLock?
1.8 中的 ConcurrentHashMap,Synchronized是将每一个Node对象作为了一个锁,将锁粒度进一步细化了,也就是说,除非两个线程同时操作一个Node,注意,是一个Node而不是一个Node链表哦,那么才会争抢同一把锁.
如果使用ReentrantLock其实也可以将锁细化成这样的,只要让Node类继承ReentrantLock就行了,这样的话调用f.lock()就能做到和Synchronized(f)同样的效果,但为什么不这样做呢?
请大家试想一下,锁已经被细化到这种程度了,那么出现并发争抢的可能性还高吗?还有就是,哪怕出现争抢了,只要线程可以在30到50次自旋里拿到锁,那么Synchronized就不会升级为重量级锁,而等待的线程也就不用被挂起,我们也就少了挂起和唤醒这个上下文切换的过程开销.
但如果是ReentrantLock呢?它则只有在线程没有抢到锁,然后新建Node节点后再尝试一次而已,不会自旋,而是直接被挂起,这样一来,我们就很容易会多出线程上下文开销的代价.当然,你也可以使用tryLock(),但是这样又出现了一个问题,你怎么知道tryLock的时间呢?在时间范围里还好,假如超过了呢?
所以,在锁被细化到如此程度上,使用Synchronized是最好的选择了.这里再补充一句,Synchronized和ReentrantLock他们的开销差距是在释放锁时唤醒线程的数量,Synchronized是唤醒锁池里所有的线程+刚好来访问的线程,而ReentrantLock则是当前线程后进来的第一个线程+刚好来访问的线程.
如果是线程并发量不大的情况下,那么Synchronized因为自旋锁,偏向锁,轻量级锁的原因,不用将等待线程挂起,偏向锁甚至不用自旋,所以在这种情况下要比ReentrantLock高效
IO
分类
四大基类:
java.io.InputStreamjava.io.OutputStreamjava.io.Readerjava.io.Writer
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流。
Files 和 Paths
从 Java 7 开始,提供了 Files 和 Paths 这两个工具类,能极大地方便我们读写文件。
虽然 Files 和 Paths 是 java.nio 包里面的类,但他俩封装了很多读写文件的简单方法。
BIO
BIO (Blocking I/O): 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。
NIO
NIO (Non-blocking/New I/O): NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。
NIO核心组件
NIO 包含下面几个核心的组件:
- Channel(通道)
- Buffer(缓冲区)
- Selector(选择器)
AIO
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
BIO,NIO,AIO 总结
Java 中的 BIO、NIO和 AIO 理解为是 Java 语言对操作系统的各种 IO 模型的封装。
如何区分 “同步/异步 ”和 “阻塞/非阻塞” 呢?
同步/异步是从行为角度描述事物的,而阻塞和非阻塞描述的当前事物的状态(等待调用结果时的状态)。
NIO的特性/NIO与IO区别
IO流是阻塞的,NIO流是非阻塞的。
IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。
任何时候访问NIO中的数据,都是通过缓冲区进行操作。最常用的缓冲区是 ByteBuffer。
NIO 通过Channel(通道) 进行读写。
通道是双向的,可读也可写,而流的读写是单向的。
NIO有选择器,而IO没有。
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。
多线程
线程
状态
java.lang.Thread.State枚举类中定义了六种线程的状态,可以调用线程Thread中的getState()方法获取当前线程的状态。
| 线程状态 | 解释 |
|---|---|
| NEW | 尚未启动的线程状态,即线程创建,还未调用start方法 |
| RUNNABLE | 就绪状态(调用start,等待调度)+正在运行 |
| BLOCKED | 等待监视器锁时,陷入阻塞状态 |
| WAITING | 等待状态的线程正在等待另一线程执行特定的操作(如notify) |
| TIMED_WAITING | 具有指定等待时间的等待状态 |
| TERMINATED | 线程完成执行,终止状态 |
下图源自《Java并发编程艺术》图4-1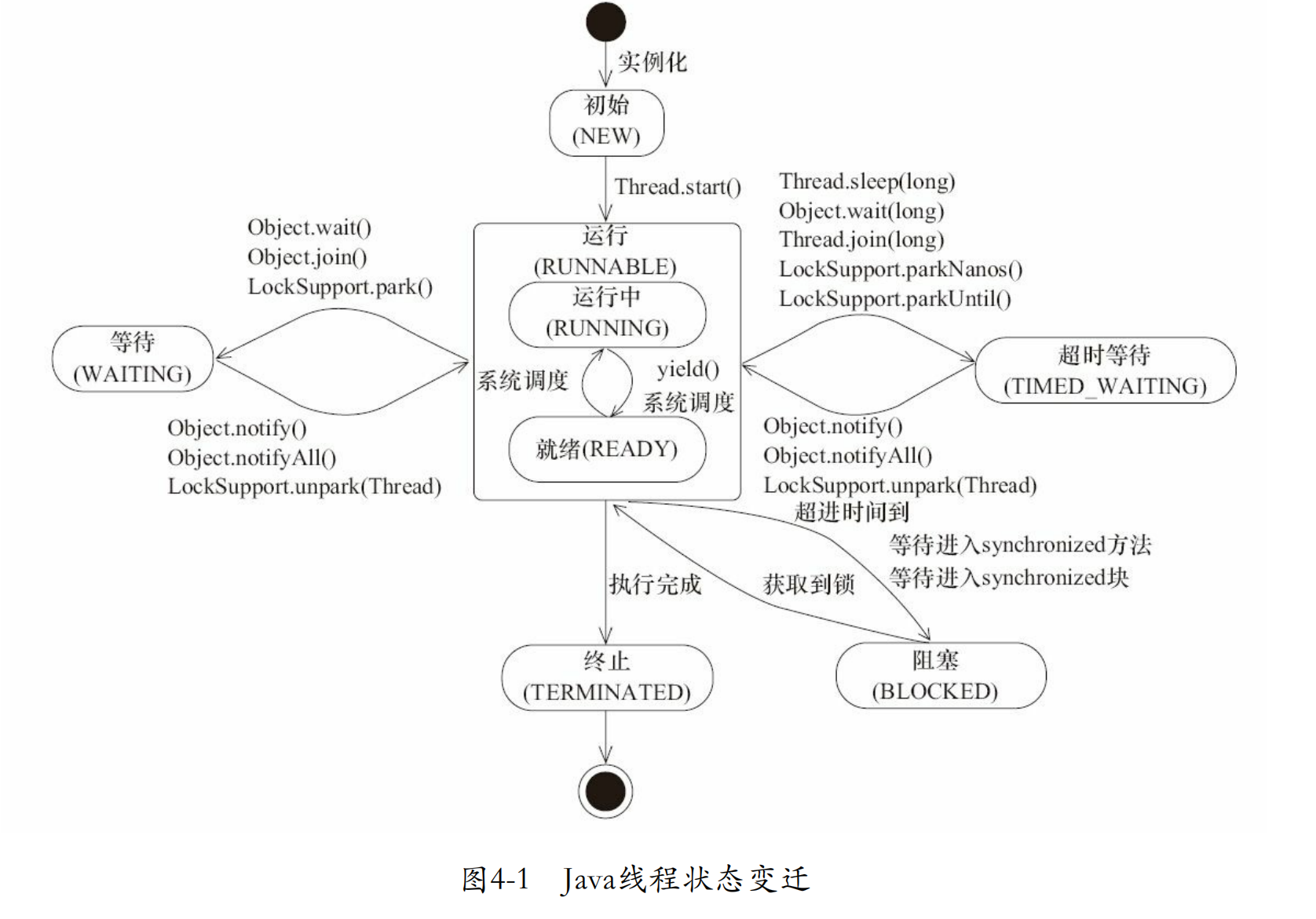
volatile
volatile 关键字除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。
synchronized
在 Java 早期版本中,synchronized 属于 重量级锁,效率低下。
因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
synchronized 和 ReentrantLock 的区别
两者都是可重入锁
synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
ReentrantLock 比 synchronized 增加了一些高级功能
主要有三点:
- 等待可中断 :
ReentrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。 - 可实现公平锁 :
ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。ReentrantLock默认情况是非公平的,可以通过ReentrantLock类的ReentrantLock(boolean fair)构造方法来制定是否是公平的。 - 可实现选择性通知(锁可以绑定多个条件):
synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制。ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition()方法。
- 等待可中断 :
synchronized 关键字和 volatile 关键字的区别
synchronized 关键字和 volatile 关键字是两个互补的存在,而不是对立的存在!
- volatile 关键字是线程同步的轻量级实现,所以volatile 性能肯定比 synchronized 关键字要好。但是volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块。
- volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
- volatile 关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性。
为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
因为直接调用 run() 方法不会创建新线程去执行,而是当作普通方法在当前线程里执行。
线程池
创建
《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
ThreadPoolExecutor
1 | public ThreadPoolExecutor(int corePoolSize, |
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize: 核心线程数线程数定义了最小可以同时运行的线程数量。maximumPoolSize: 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数:
keepAliveTime:当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁;unit:keepAliveTime参数的时间单位。threadFactory:executor 创建新线程的时候会用到。handler:饱和策略。
ThreadPoolExecutor 饱和策略
ThreadPoolExecutor 饱和策略定义:
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,ThreadPoolTaskExecutor 定义一些策略:
ThreadPoolExecutor.AbortPolicy:抛出RejectedExecutionException来拒绝新任务的处理。ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
execute()方法和 submit()方法的区别?
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;submit()方法用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future对象可以判断任务是否执行成功,并且可以通过Future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
原子类
AtomicInteger 类的原理
AtomicInteger 类的部分源码:
1 | // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用) |
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
CAS的缺点
ABA问题
假设有两个线程——线程1和线程2,两个线程按照顺序进行以下操作:
(1)线程1读取内存中数据为A;
(2)线程2将该数据修改为B;
(3)线程2将该数据修改为A;
(4)线程1对数据进行CAS操作
在第(4)步中,由于内存中数据仍然为A,因此CAS操作成功,但实际上该数据已经被线程2修改过了。这就是ABA问题。
在AtomicInteger的例子中,ABA似乎没有什么危害。但是在某些场景下,ABA却会带来隐患,例如栈顶问题:一个栈的栈顶经过两次(或多次)变化又恢复了原值,但是栈可能已发生了变化。
对于ABA问题,比较有效的方案是引入版本号,内存中的值每发生一次变化,版本号都+1;在进行CAS操作时,不仅比较内存中的值,也会比较版本号,只有当二者都没有变化时,CAS才能执行成功。Java中的AtomicStampedReference类便是使用版本号来解决ABA问题的。
高竞争下的开销问题
在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。当然,更重要的是避免在高竞争环境下使用乐观锁。
功能限制
CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性,这意味着:(1)原子性不一定能保证线程安全,例如在Java中需要与volatile配合来保证线程安全;(2)当涉及到多个变量(内存值)时,CAS也无能为力。
除此之外,CAS的实现需要硬件层面处理器的支持,在Java中普通用户无法直接使用,只能借助atomic包下的原子类使用,灵活性受到限制。
AQS
AQS 的全称为(AbstractQueuedSynchronizer)
AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 ReentrantLock,Semaphore,其他的诸如 ReentrantReadWriteLock,SynchronousQueue,FutureTask 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
AQS 组件总结
- Semaphore(信号量)-允许多个线程同时访问: synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
- CountDownLatch (倒计时器): CountDownLatch 是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
- CyclicBarrier(循环栅栏): CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用 await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
用过 CountDownLatch 么?什么场景下用的?
CountDownLatch 的作用就是 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。之前在项目中,有一个使用多线程读取多个文件处理的场景,我用到了 CountDownLatch 。具体场景是下面这样的:
我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。
为此我们定义了一个线程池和 count 为 6 的CountDownLatch对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用CountDownLatch对象的 await()方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
锁
乐观锁 VS 悲观锁
- 乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
- 悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
乐观锁的实现方式主要有两种:CAS机制和版本号机制。
公平锁 VS 非公平锁
公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,锁被占用时直接进入队列中排队。
公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐率相对非公平锁要低,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。
非公平锁的优点是可以减少唤起线程的开销,整体的吞吐率高。
缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
可重入锁 VS 非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法再获取锁时会自动获得锁,不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。
独享锁 VS 共享锁
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
ReentrantReadWriteLock有两把锁:ReadLock和WriteLock,读锁是共享锁,写锁是独享锁。
设计模式

单例模式
实现方式
饿汉模式
Static initializers are run by the JVM at class initialization time, after class loading but before the class is used by any thread. Because the JVM acquires a lock during initialization [JLS 12.4.2] and this lock is acquired by each thread at least once to ensure that the class has been loaded, memory writes made during static initialization are automatically visible to all threads. Thus statically initialized objects require no explicit synchronization either during construction or when being referenced
1 | public class Singleton1 { |
类加载机制保障了饿汉模式的线程安全。JVM 在类加载时会获取一把锁,这把锁在线程访问对象时也会先去争取,确保类已经被加载了。
懒汉模式
1 | public class Singleton2 { |
线程安全的懒汉模式
1 | public class Singleton3 { |
双重校验锁模式(DCL,即 double-checked locking)
1 | public class Singleton4 { |
为什么要两次判空?
第一次判空是为了减少无谓的抢夺锁,提升销量。
第二次判空是为了保障不会破坏单例,假设没有第二次判空,线程 1,线程 2 同时通过第一次判空,之后线程 1 获得了锁,并实例化了 instance,之后线程 2 获得锁,又会实例化一遍,破坏了单例模式。
为什么要加 volatile 关键字?
instance = new Singleton4(); 可以被拆解为三条机器指令(伪代码)
1 | memory = allocate(); //1:分配对象的内存空间 |
由于存在指令重排序,上述三条指令的顺序可能会变成 1、3、2
如果没有使用 volatile,那假设线程 1 已经执行到创建对象的语句了,且刚好执行到重排序后到机器指令 3,此时 instance 已经不是 null 了,其他线程就会获取到一个没有完整初始化的 instance 对象,进而造成未知错误。
静态内部类单例模式
1 | public class Singleton5 { |
静态内部类模式综合了懒汉和饿汉模式,既满足线程安全,又满足延迟加载。
枚举单例模式
《Effective Java》作者认为该模式是单例模式的最佳实践。
1 | public enum Singleton6 { |
反射攻击
私有化构造器并不能阻止反射攻击。
1 | public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException { |
1 | false |
反射攻击枚举单例模式
1 | public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException { |
1 | Exception in thread "main" java.lang.NoSuchMethodException: com.gzhennaxia.demo.singleton.Singleton6.<init>() |
报错说找不到空构造方法,但即使手动添加了空构造方法同样会报这个错,因为 Java 编译器会为每个构造器自动添加两个参数,这点从反编译文件中可以看出(只有一个 com/gzhennaxia/demo/singleton/Singleton6."<init>":(Ljava/lang/String;I)V 双参构造器)。
1 | public enum Singleton6 { |
1 | Classfile /Users/libo/Documents/GitHub/projects/demo/src/main/java/com/gzhennaxia/demo/singleton/Singleton6.class |
从反编译结果可以看出枚举的实例化调用的是继承自 java.lang.Enum 的 protected Enum(String var1, int var2) 构造器,那是否可以反射调用该构造器来实例化 Singleton6 呢?
1 | public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException { |
1 | Exception in thread "main" java.lang.IllegalArgumentException: Cannot reflectively create enum objects |
结果报错,查看 java.lang.reflect.Constructor.newInstance (Constructor.java:417)
1 | public T newInstance(Object ... initargs) |
可以看到反射创建实例的时候会判断类的修饰符中是否有 enum,如果有就抛出 IllegalArgumentException 异常。
因此,枚举类型可以防止反射攻击。
非枚举的防守方法
在构造器中判断实例是否已经存在,存在就抛出异常,保证构造器只被调用一次!
1 | public class Singleton1 { |
序列化攻击
一般类需要实现 Serializable 接口才能被序列化,但枚举类不用,因为枚举类本质是继承了 java.lang.Enum 的,而 Enum 已经声明实现了 Serializable。
一般的单例模式无法防止序列化攻击,经过序列化和反序列化后会创建出新的实例。
1 | public class SingletonTest2 { |
1 | false |
但是对于枚举类来说,反序列化后还是原来的实例。
1 | public static void main(String[] args) throws IOException, ClassNotFoundException { |
1 | true |
可以看到反序列化枚举后得到的实例和序列化之前的实例是同一个实例。查看 ByteArrayOutputStream.writeObject() 方法源码:
1 | public final void writeObject(Object obj) throws IOException { |
writeObject0() 源码:
1 | private void writeObject0(Object obj, boolean unshared) |
如果是枚举类型,会调用 writeEnum() 方法:
1 | private void writeEnum(Enum<?> en, |
接着再看 Enum 类型的反序列化,ObjectInputStream.readObject() 源码:
1 | public final Object readObject() |
ObjectInputStream.readObject0() 源码:
1 | private Object readObject0(boolean unshared) throws IOException { |
ObjectInputStream.readEnum() 源码:
1 | private Enum<?> readEnum(boolean unshared) throws IOException { |
Enum.valueOf() 源码:
1 | public static <T extends Enum<T>> T valueOf(Class<T> enumType, |
最终是根据 name 在枚举类实力数组里查找,所以返回的实例是已经存在的实例,并不会新建实例。
因此枚举可以防止反序列化攻击。
非枚举的防守方法
增加 readResolve() 方法返回单例,反序列化时会判断对象是否存在该方法,存在则会调用该方法返回对象。
总结
| 饿汉模式 | 懒汉模式 | 线程安全的懒汉模式 | 双重校验锁模式 | 静态内部类单例模式 | 枚举单例模式 | |
|---|---|---|---|---|---|---|
| 延迟加载 | 否 | 是 | 是 | 是 | 是 | 否 |
| 线程安全 | 是 | 否 | 是 | 是 | 是 | 是 |
| 反射攻击 (能否抵御) | 否 | 否 | 否 | 否 | 否 | 能 |
| 反序列化攻击 (能否抵御) | 否 | 否 | 否 | 否 | 否 | 能 |
工厂模式
策略模式
《大话设计模式》第2章 商场促销——策略模式
现金收费抽象类
1 | public interface CashSuper { |
正常收费子类
1 | public class CashNormal implements CashSuper{ |
打折收费子类
1 | public class CashRebate implements CashSuper { |
返利收费子类
1 | public class CashReturn implements CashSuper { |
简单工厂实现
现金收费工厂类
1 | public class CashFactory { |
客户端
1 | public class Client { |
策略与简单工厂结合
CashContext类
1 | public class CashContext { |
如何消除switch语句?
通过反射
客户端
1 | public class Client { |
简单工厂模式 VS 策略模式与简单工厂结合
1 | //简单工厂模式的用法 |
- 简单工厂模式需要让客户端认识两个类,CashSuper和CashFactory,而策略模式与简单工厂结合的用法,客户端就只需要认识一个类CashContext就可以了。耦合更加降低。
- 策略模式与简单工厂结合的用法在客户端实例化的是CashContext的对象,调用的是CashContext的方法getResult,这使得具体的收费算法彻底地与客户端分离。连算法的父类CashSuper都不让客户端认识了。
策略模式的优缺点
优点
低耦合
策略模式是一种定义一系列算法的方法,所有算法完成相同的工作,只是实现不同,它可以以相同的方式调用所有的算法,减少了各种算法类与使用算法类之间的耦合。
简化单元测试
每个算法都有自己的类,可以通过自己的接口单独测试。
缺点
- 策略类需要对客户端透明:客户端必须知道所有的策略类,并自行决定哪一个策略类,也就是客户端需要理解这些算法的区别以便选择适当的算法
- 策略类数量多:策略模式会造成系统产生很多具体策略类,任何细小的变化都会导致系统增加一个新的具体策略类
- 客户端无法使用多个策略类:客户端每次只能使用一个策略类,不支持使用一个策略类完成部分功能后再使用另一个策略类来完成剩下的功能
典型应用
JDK
比较器接口 java.util.Comparator
通过 Collections.sort(List,Comparator) 和 Arrays.sort(Object[],Comparator) 对集合和数组进行排序。
Comparator 接口充当了抽象策略角色,Collections 和 Arrays 则是环境角色。
Spring
实例化策略接口 org.springframework.beans.factory.support.InstantiationStrategy
Spring 在具体实例化Bean的过程中,先通过 ConstructorResolver 找到对应的实例化方法和参数,再通过实例化策略 InstantiationStrategy 进行实例化。
1 | public interface InstantiationStrategy { |
InstantiationStrategy 扮演抽象策略角色,有两种具体策略类,分别为 SimpleInstantiationStrategy 和 CglibSubclassingInstantiationStrategy

在 SimpleInstantiationStrategy 中对这三个方法做了简单实现,如果工厂方法实例化直接用反射创建对象,如果是构造方法实例化的则判断是否有 MethodOverrides,如果无 MethodOverrides 也是直接用反射,如果有 MethodOverrides 就需要用 cglib 实例化对象,SimpleInstantiationStrategy 把通过 cglib 实例化的任务交给了它的子类 CglibSubclassingInstantiationStrategy。
项目
应用世界:不同策略上下架应用
应用世界中上下架应用有不同的策略:过期时间、点击量、用户量等策略。
过期时间策略在应用到达过期时间时自动下架。
点击量在应用的点击次数到达阀值后自动下架。
用户量在应用的新用户数达到阀值后自动下架。
责任链模式
模式结构
责任链模式包含如下角色:
- 处理器抽象类
- 具体处理器
- 处理器链维护器(可选):维护了各个处理器的前后关系。可以由客户端再发送请求前生成链,或者动态地生成链。
- 客户端
伪例
请假流程
请假请求类:LeaveRequest
1 | public class LeaveRequest { |
处理器抽象类:LeaveRequestHandler
1 | public abstract class LeaveRequestHandler { |
处理器具体类:SupervisorHandler、ManagerHandler、GeneralManagerHandler
1 | public class SupervisorHandler extends LeaveRequestHandler { |
客户端:Worker
1 | public class Worker { |
典型应用
Tomcat 过滤器中的责任链模式
Servlet 过滤器是可用于 Servlet 编程的 Java 类,可以实现以下目的:在客户端的请求访问后端资源之前,拦截这些请求;在服务器的响应发送回客户端之前,处理这些响应。
Mybatis 中的 Plugin 机制
Mybatis 中的 Plugin 机制使用了责任链模式,配置各种官方或者自定义的 Plugin,与 Filter 类似,可以在执行 Sql 语句的时候做一些操作。
包装模式/装饰者模式
别称:包装模式、装饰器模式、Wrapper、Decorator
装饰器模式(Decorator Pattern)允许在不改变其结构的情况下向一个现有的对象添加新的功能。
结构
- 抽象构件 (Component)
- 具体构件 (Concrete Component)
- 抽象装饰类 (Decorator)
- 具体装饰类 (Concrete Decorators)
简单示例
画图形:图形有长方形、圆形;可以画红色的也可以画绿色的。
抽象构件
1 | public interface Shape { |
具体构件
1 | public class Rectangle implements Shape { |
1 | public class Circle implements Shape { |
抽象装饰类
1 | public abstract class ShapeDecorator implements Shape { |
具体装饰类
1 | public class RedShapeDecorator extends ShapeDecorator { |
1 | public class GreenShapeDecorator extends ShapeDecorator { |
客户端使用
1 | public static void main(String[] args) { |
1 | Shape: rectangle Color: red |
典型应用
Java I/O
抽象构件:java.io.InputStream
具体构件:
java.io.FileInputStreamjava.io.ByteArrayInputStreamjava.io.PipedInputStream
抽象装饰类:java.io.FilterInputStream
具体装饰类:
java.io.BufferedInputStreamjava.io.DataInputStreamjava.io.PushbackInputStream
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
1 | FileInputStream fileInputStream = new FileInputStream(filePath); |
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
模版方法模式
代理模式
用代理对象代替目标对象来实现某个目的(服务/主题/功能)。
目的
- 隐藏目标对象
- 增强目标对象
代理模式结构
服务接口
声明了服务接口。 代理必须遵循该接口才能伪装成服务对象。
服务类
提供了一些实用的业务逻辑。
代理类
代理类包含一个指向服务对象的引用成员变量。 代理完成其任务 (例如延迟初始化、 记录日志、 访问控制和缓存等) 后会将请求传递给服务对象。 通常情况下, 代理会对其服务对象的整个生命周期进行管理。
客户端
客户端能通过同一接口与服务或代理进行交互,所以你可在一切需要服务对象的代码中使用代理。
静态代理
劳动仲裁案例:代理律师代理讨薪员工索要工资。
服务接口
代理主题:讨薪
1 | public interface AskAbility { |
服务类
1 | public class ZhangSan implements AskAbility { |
代理类
1 | public class Lawyer implements AskAbility { |
客户端
1 | public class Client { |
动态代理
静态代理中代理类在编译期已经存在,一个服务类需要一个代理类与之对应,当服务类增多时,代理类随着增多,导致类数量太多。
动态代理就是为了减少类数量而产生。
动态代理有 JDK(基于接口、反射生成) 和 CGLIB(基于继承、字节码生成) 两种实现方式。
Spring AOP 就是基于动态代理实现的。
JDK 动态代理
两个重要的元素:
InvocationHandler 接口
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;- proxy:动态代理对象
- method:正在执行的方法
- args:当前执行方法传入的实参
Proxy 类
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) throws IllegalArgumentException
1 | public class AskingHandler implements InvocationHandler { |
1 | public class Client { |
CGLIB 动态代理
JDK 只能对实现了接口的类做动态代理,而不能对没有实现接口的类做动态代理,所以出现了 cgLib。
CGLib(Code Generation Library)是一个强大、高性能的 Code 生成类库,它可以在程序运行期间动态扩展类或接口,它的底层是使用 java字节码操作框架 ASM 实现。
CGLIB 两个重要元素:
MethodInterceptor 方法拦截器
Object intercept(Object var1, Method var2, Object[] var3, MethodProxy var4) throws Throwable;Enhancer
1
2
3
4
5
6public static Object create(Class type, Callback callback) {
Enhancer e = new Enhancer();
e.setSuperclass(type);
e.setCallback(callback);
return e.create();
}
服务类
1 | public class Employee { |
方法拦截器
1 | public class AskingMethodInterceptor implements MethodInterceptor { |
客户端
1 | public class Client { |
Spring 何时使用JDK/CGLIB
目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP。
目标对象没有实现了接口,采用 CGLIB 库。
如何强制使用 CGLIB 实现 AOP
在 Spring 配置文件中加入:
<aop:aspectj-autoproxy proxy-target-class="true"/>Spring Boot 中是在主配置文件中添加:
spring.aop.proxy-target-class=true或者在启动类上添加:
@EnableAspectJAutoProxy(proxyTargetClass = true)
在 Spring Boot 2.x 已经默认使用 CGLIGB 生成代理了。
Spring 5.x 中 AOP 默认依旧使用 JDK 动态代理。
SpringBoot 2.x 开始,为了解决使用 JDK 动态代理可能导致的类型转化异常而默认使用 CGLIB。
在 SpringBoot 2.x 中,如果需要默认使用 JDK 动态代理可以通过配置项
spring.aop.proxy-target-class=false来进行修改,proxyTargetClass配置已无效。
强制使用 cglib 做动态代理有哪些好处?
如果不做特殊配置 spring 的
@Transactional注解,放在类中非接口内的方法上时,是不起作用的。因为 spring 默认使用JDK的代理,被代理的类只能拦截接口中的方法,不能拦截非接口中的方法。如果注入时需要直接使用子类,那么启动时会报错
1
2
3
4
5
6
7// 正常
UserService userService;
// 报错:
UserServiceImpl userService;因为 JDK 动态代理是基于接口的,代理生成的对象只能赋值给接口变量。
JDK 与 CGLIB 性能对比
- JDK 在创建代理类的速度上要比 CGLIB 快大概8倍左右
- JDK 1.6以前,CGLIB 代理类执行代理方法的速度要比 JDK 的大概高 10 倍。
- JDK 1.6/1.7 时,JDK 动态代理的运行速度在调用次数比较少的情况下要比 CGLIB 快,调用次数多的情况下还是 CGLIB 更快一些。
- JDK 1.8 时,JDK 动态代理的运行速度已经比 CGLIB 快了。
JDK 动态代理与 CGLIB 动态代理的区别
- JDK 动态代理基于接口,CGLIB 动态代理基于继承
- JDK 动态代理通过反射生成代理,CGLIB 通过操作字节码生成动态代理
- JDK 生成动态代理比CGLIB快
- JDK 动态代理执行代理方法时,需要通过反射机制进行回调,CGLIB 对方法的调用和直接调用普通类的方式一致,所以
CGLib执行代理方法的效率要高于JDK的动态代理
迭代器模式
目的
在不暴露集合底层表现形式 (列表、 栈和树等) 的情况下遍历集合中所有的元素。
主要思想
将集合的遍历行为抽取为单独的迭代器对象。
结构
- 抽象迭代器(Iterator)
- 具体迭代器(Concrete Iterators)
- 抽象集合(Collection)
- 具体集合(Concrete Collections)
简单示例
学生报数
抽象迭代器
1 | public interface StudentIterator { |
具体迭代器
1 | public class ConcreteStudentIterator implements StudentIterator { |
抽象集合
1 | public abstract class StudentCollection { |
具体集合
1 | public class ConcreteStudentCollection extends StudentCollection { |
客户端使用
1 | public static void main(String[] args) { |
1 | 我是1号:张三 |
典型应用
Java 集合

网络
网络分层
网络分层有三种:
- OSI 7层协议
- TCP/IP 4层协议
- 中和的5层协议
TCP
三次握手
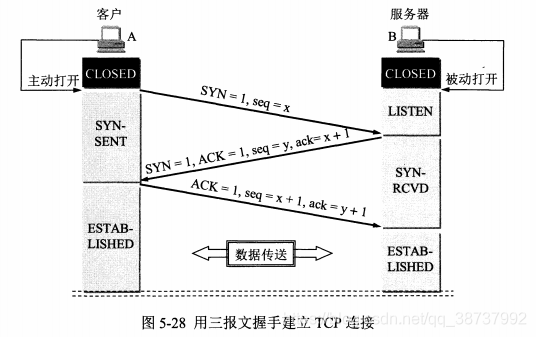
为什么要三次握手?
三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
所以三次握手就能确认双发收发功能都正常,缺一不可。
四次挥手
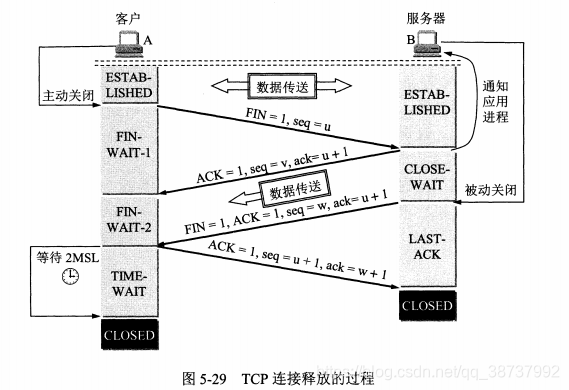
为什么要四次挥手?
四次挥手是为了连接双方能够断开彼此之间的数据通道。少于四次无法实现这个目的。
假如客户端率先发起断开连接的请求:
第一次挥手:客户端发送断开连接的请求给服务器
为了实现安全性,需要等待服务器的确认报文。
第二次挥手:服务器发送确认报文给客户端
由于 TCP 是全双工模式,双通道相互独立,故服务器还可以继续发送数据报文给客户端,此时客户端往服务器端的数据通道关闭,TCP 连接处于半关闭状态。
第三次挥手:服务器发送断开连接的请求给客户端
为了安全性,需要等待客户端的确认报文。
第四次挥手:客户端发送确认报文给服务器
当服务器接收到该报文后即可关闭连接,但客户端在发送完该报文后并不能确保服务器是否已收到,需要等待 2MSL 时间后再关闭。
2MSL等待状态
报文段最大生存时间MSL(Maximum Segment Lifetime),在第四次挥手后主动端之所以还需要等待 2MSL 时间,是因为它无法保证报文是否被接收到,但如果假设报文丢失了,那么被动端会在 2MSL 时间内再发送一次断开连接的请求,此时主动端就可以判定确认报文丢失了,然后重新发送一次确认报文,如果 2MSL 时间内没有收到被动端再一次的断开连接请求,就认为被动端已经收到确认报文了,就可以关闭连接了。
TCP 协议如何保证可靠传输
- 应用数据被分割成 TCP 认为最适合发送的数据块。
- TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
- 校验和: TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
- TCP 的接收端会丢弃重复的数据。
- 流量控制: TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
- 拥塞控制: 当网络拥塞时,减少数据的发送。
- ARQ协议: 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
- 超时重传: 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
UDP
UDP 最大只支持 512 字节的数据。
TCP 与 UDP 的区别
- TCP 面向连接,UDP 无连接
- TCP 根据流量控制和拥塞控制,以及重传控制和数据校验保证提供可靠的数据传输服务。而 UDP 不保证数据的可靠性。
- TCP 的报文段头部占20各字节,比 UDP 的报文段头部多12个字节。消耗的资源更多。由于建立连接有握手的机制,TCP 的使用效率会比 UDP 要低一些。
HTTP
常见状态码
- 200 OK:正常返回信息
- 400 Bad Request:客户端请求有语法错误,不能被服务器所理解
- 403 Forbidden:服务器收到请求,但是拒绝提供服务
- 404 Not Found:请求资源不存在,输入了错误的URL
- 500 Internal Server Error:服务器发生不可预期错误
- 503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常
常见请求头
- Accept: text/html 浏览器可以接受服务器回发的类型为 text/html。
- Accept: */* 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)。
- Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
- Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
- User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36 告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本。
常见响应头
- Content-Type:text/html;charset=UTF-8 告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
- Connection:keep-alive 这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
- Refresh: 5; url=http://baidu.com 用于重定向,或者当一个新的资源被创建时。默认会在5秒后刷新重定向。
Cookie
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。
用途
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
创建
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
浏览器禁用 Cookie
此时无法使用 Cookie 来保存用户信息,只能使用 Session。除此之外,不能再将 Session ID 存放到 Cookie 中,而是使用 URL 重写技术,将 Session ID 作为 URL 的参数进行传递。
Session
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
浏览器中输入url地址 ->> 显示主页的过程
HTTP 1.0 与 HTTP 1.1、HTTP 2.0
在 HTTP/1.0 中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
1 | Connection:keep-alive |
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
HTTP 2.0:
二进制分帧
HTTP1.x基于文本,HTTP2.0采用二进制格式。
首部压缩
多路复用
服务端推送
在 HTTP 2.0 中,服务器可以对客户端的一个请求发送多个响应。
HTTPS
SSL: Secure Sockets Layer
TLS: Transport Layer Security
HTTPS 是基于 HTTP 的扩展,在 HTTPS 中,原有的 HTTP 协议会得到 TLS(安全传输层协议)或其前身 SSL(安全套接层)的加密。
HTTPS = HTTP + TLS/SSL

HTTPS 整个通信过程可以分为两大阶段:证书验证和数据传输,数据传输阶段又可以分为非对称加密和对称加密两个阶段。
具体流程如下:
浏览器客户端发送 HTTPS 请求。
采用 HTTPS 协议的服务器必须向 CA 机构有偿申请合法的 CA(Certification Authority)证书。CA机构颁发证书时会生成一对公钥和私钥,服务器将私钥自己保存,公钥包含在证书中,可以公开,同时证书本身会附带一个电子签名,这个签名是用来验证证书的完整性和真实性,防止证书被篡改。
服务器将证书传送给浏览器客户端
浏览器客户端解析证书对其进行验证。如果证书不是可信机构颁发的、证书中的域名与实际域名不一致、或者证书已过期,就会向用户显示一个警告,询问是否还要继续通信。
如果证书没有问题,就从证书中取出共钥,然后生成一个随机码,用共钥加密后作为之后对称加密的密钥。
浏览器客户端将对称加密的密钥发送给服务器
服务器收到密钥后会使用自己的私钥解密得到对称加密的密钥。
至此,客户端和服务器就建立好了安全连接,解决了对称加密的密钥泄漏问题。
服务器使用密钥对数据进行对称加密并发送给客户端,客户端使用相同的密钥解密数据。
双方使用对称加密进行数据传输。
HTTP 和 HTTPS 的区别
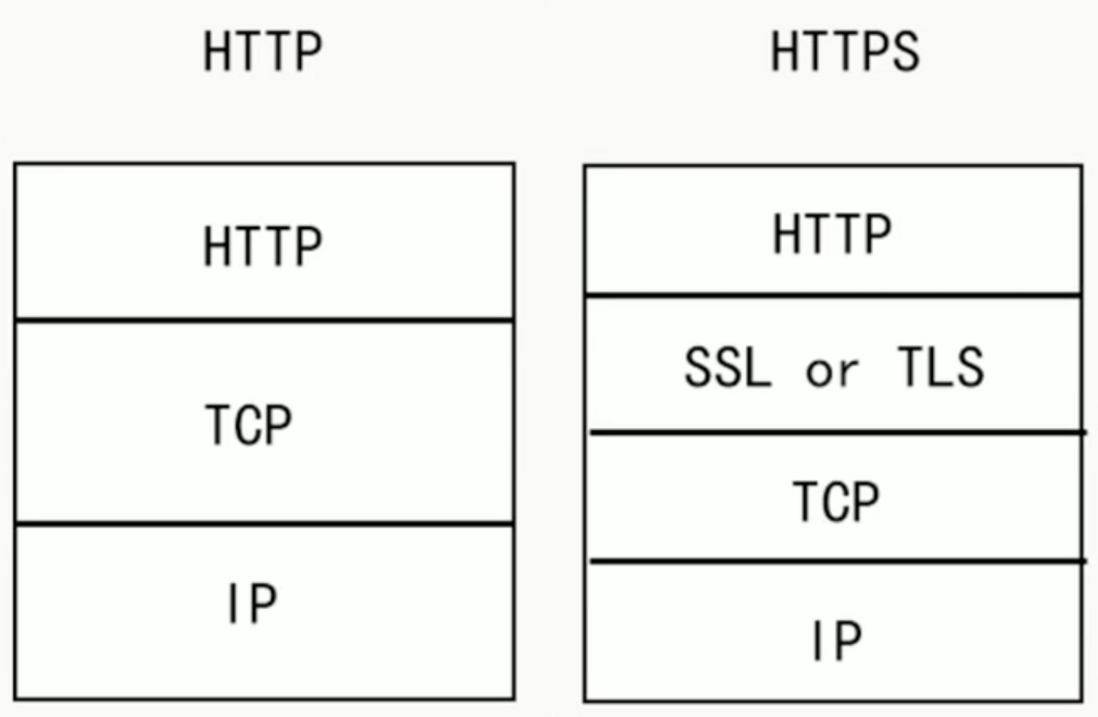
端口
HTTP 默认使用端口 80,而 HTTPS 默认使用端口443。
资源消耗
Https 由于加解密处理会消耗更多的CPU和内存资源,所以 HTTP 页面响应速度比 HTTPS 快。
安全性
HTTP 安全性没有 HTTPS 高,但是 HTTPS 比HTTP耗费更多服务器资源。
- 对称加密:密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES等;
- 非对称加密:密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。
数据库
Mysql
InnoDB
默认使用的B+树的索引模型
MyISAM和InnoDB区别
MyISAM是MySQL 5.5版之前的默认数据库引擎。5.5版本之后,默认的存储引擎为InnoDB。
两者的对比:
- 是否支持行级锁 : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
- 是否支持事务和崩溃后的安全恢复: MyISAM 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持,外键等高级数据库功能。 具有事务、回滚和崩溃修复能力的事务安全型表。
- 是否支持外键: MyISAM不支持,而InnoDB支持。
- 是否支持MVCC :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在
READ COMMITTED和REPEATABLE READ两个隔离级别下工作;MVCC可以使用乐观锁和悲观锁来实现;各数据库中MVCC实现并不统一。
索引
结构
MySQL索引使用的数据结构主要有BTree索引和哈希索引。
主键索引
回表
从非主键索引树回到主键索引树的查询的过程叫做回表。
也就是说通过非主键索引的查询需要多扫描一棵索引树,因此需要尽量使用主键索引查询。
覆盖索引
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
例如:存在联合索引(col1,col2),之后根据 col1 查询 col2,此时由于索引结点上包含所需的值,所以不需要回表。
主键索引与非主键索引的区别
非主键索引的叶子节点存放的是主键的值,而主键索引的叶子节点存放的是整行数据。非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
非主键索引列的查询,则先搜索非主键索引树,得到主键ID值,再到主键索引树搜索一次,这个过程也被称为回表。
非主键索引一定会查询多次吗?
覆盖索引也可以只查询一次,覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
聚集索引和非聚集索引的区别
- 聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但对数据更新影响较大。(比如主键索引)
- 非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置。非聚集索引检索效率比聚集索引低,但对数据更新影响较小。
B+树索引和Hash索引比较
InnoDB 为什么使用B+树而不是hash索引
- 哈希索引适合等值查询,不适合范围查询
- 哈希索引没办法利用索引完成排序
- 哈希索引不支持多列联合索引的最左匹配规则
- 如果有大量重复键值的情况下,因为哈希碰撞问题,会导致哈希索引的效率大大降低。
联合索引
联合索引(A,B,C),但是查询的时候是反过来查的(C=xxx and B=xxx and A=xxx),这种能走索引吗?
where里面的条件顺序在查询之前会被mysql自动优化,变为A,B,C,然后使用联合索引。
1 | (1) select * from myTest where a=3 and b=5 and c=4; ---- abc顺序 |
MySql 索引自动优化
当预估返回的数据量超过一定比例(当预估的查询量达到总量的30% )的时候,mysql 就会进行全表扫描。
mysql 会根据索引大概估算选择最快的索引。
例如:
1
2
3
4-- sql1:
select * from table where col_a = 123 and col_b in ('foo', 'bar') order by id desc;
-- sql2: select * from table where col_a = 456 and col_b in ('foo', 'bar') order by id desc;结果 sql1 选择利用了 col_a 的索引,速度很快,sql2利用了主键ID的索引,扫描了全表(40w行)。
仔细分析,发现数据库中,col_a=456 的记录数有近1万条,而 col_a=123 的记录数只有几条。
当 col_a=456 时,Mysql 认为主键索引会比普通index更快,所以mysql最后选择了数据量更大的id索引。
那么,如何解决这个问题呢?
很简单,只要在order语句里写多个键即可,比如:order by col_a, id desc
事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务的四大特性(ACID)
- 原子性(Atomicity): 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性(Consistency): 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
- 隔离性(Isolation): 并发访问数据库时,一个事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
并发事务带来哪些问题?
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复读和幻读区别:
不可重复读的重点是修改,比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除,比如多次读取一条记录发现记录增多或减少了。
事务隔离级别有哪些?MySQL的默认隔离级别是?
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看,MySQL 8.0 该命令改为SELECT @@transaction_isolation;
1 | mysql> SELECT @@tx_isolation; |
这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 REPEATABLE-READ(可重读) 事务隔离级别下使用的是Next-Key Lock 锁(间隙锁)算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server) 是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的 SERIALIZABLE(可串行化) 隔离级别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 READ-COMMITTED(读取提交内容) ,但是InnoDB 存储引擎默认使用 REPEAaTABLE-READ(可重读) 并不会有任何性能损失。
Next-Key Lock(间隙锁)
举例来说,假如emp表中只有101条记录,其empid的值分别是 1,2,…,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。
锁
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。
如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。
行锁 VS 表锁
- 表锁: 开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突概率高,并发度低
- 行锁: 开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高
InnoDB的行锁模式及加锁方法
InnoDB实现了以下两种类型的行锁。
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
InnoDB行锁模式兼容性列表
| 请求锁模式 是否兼容当前锁模式 |
X | IX | S | IS |
|---|---|---|---|---|
| X | 冲突 | 冲突 | 冲突 | 冲突 |
| IX | 冲突 | 兼容 | 冲突 | 兼容 |
| S | 冲突 | 冲突 | 兼容 | 兼容 |
| IS | 冲突 | 兼容 | 兼容 | 兼容 |
连接查询
- left join (左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
- right join (右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
- inner join (等值连接或者叫内连接):只返回两个表中连接字段相等的行。
- full join (全外连接):返回左右表中所有的记录和左右表中连接字段相等的记录。MySQL不支持
优化
查询数据库的运行情况
显示数据库运行状态
SHOW STATUS
显示数据库运行总时间
SHOW STATUS LIKE 'uptime'
显示连接的次数
SHOW STATUS LIKE 'connections'
显示执行CRUD的次数
1 | SHOW STATUS LIKE 'com_select' |
慢查询
慢查询配置
Linux下修改my.cnf,Windows下修改my.ini。修改后需要重启mysql才会生效。
1 | #开启慢查询 |
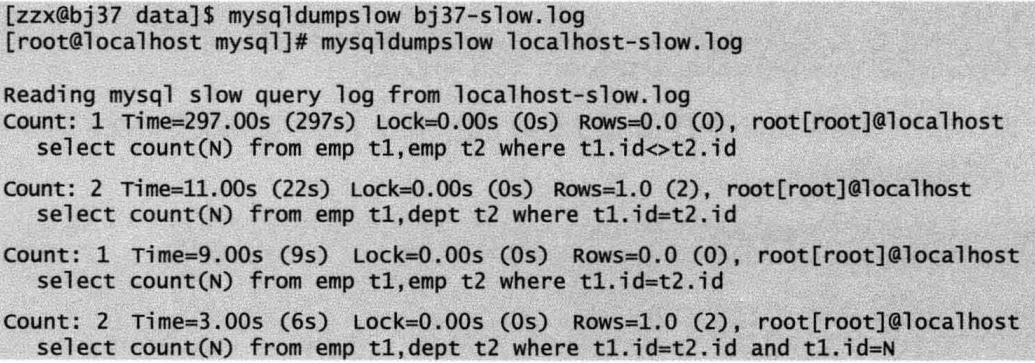
定位慢查询SQL
如果慢查询日志中记录内容较多,则可以使用Mysql自带的慢查询日志分析工具mysqldumpslow来对慢查询日志进行分类汇总。该工具位于/mysql/bin目录下。mysqldumpslow会自动将文本完全一致但变量不同的SQL语句视为同一个语句进行统计,变量值用N来代替。
1 | mysqldumpslow -s r -t 10 /data/dbdata/frem-slow.log |
执行计划
1 | explain [要分析的sql] |
分析结果中有如下几列:
- id:查询序号
- select_type
- table
- type
- possible_keys
- key
- key_len
- ref
- rows
- Extra
id
表示 select 查询序列号。id值越大,越优先执行。\如果id相同,执行顺序由上至下** **
select_type
表示查询类型。主要用于区分普通查询、子查询、联合查询等几种查询情况。
取值:
- simple
- primary
- subquery
- derived
- union
- union result
①simple:表示简单查询,只有一个select操作,即不使用连接和union。
1 | #只有一个select操作,所以都是简单查询 |
②primary:表示主查询。子查询语句中的最外层select,或union操作的第一个select。
1 | #子查询形式:第一个select操作为primary |
③subquery:表示子查询。子查询语句中的内层select。
1 | #第二个select操作为subquery |
④derived:表示FROM后跟着的select查询,会被标记为derived(导出表/衍生表)。
1 | #第二个select操作为derived |
⑤union:表示UNION操作后面的select查询。
1 | #第二个select操作为union |
⑥union result:表示获取UNION最后结果的查询。
1 | #第一个select操作为primary |

table
表示查询用到的表。
type
表示找到匹配行用到的访问类型。
最为常见的类型有:
- NULL
- system
- const
- eq_ref
- ref
- range
- index
- All
按照性能从高到低顺序如下:NULL–>system–>const–>eq-ref–>ref–>range–>index–>All 。一般来说,要让查询至少达到range级别,最好能达到ref级别。
①NULL:不用访问表或索引,就可直接得出结果。
②system:该表是最多仅有一行的系统表(这是const类型的一个特例)。系统表中的数据通常已经加载到了内存中,所以不需要磁盘IO。
例子1:查询系统表
例子2:内层嵌套(const)返回了一个临时表,外层嵌套从临时表中查询,其扫描类型也是system,也不需要磁盘IO。

③const:最多只有一个匹配行,所以该行中的其它列的值可以当作常量来处理。例如,根据主键primary key或唯一索引unique index进行查询。简单地说const就是直接按主键或唯一键取值。例如在②中介绍system时的举例中user表的访问类型就是const,其通过主键来取值。

④eq_ref:使用唯一索引,对于每个索引键值,表中只有一条记录匹配。简单说,就是多表连接中使用primary key或unique index作为关联条件。
注意const和eq_ref的区别:简单地说是const是直接按主键或唯一键读取,eq_ref用于联表查询的情况,按联表的主键或唯一键联合查询。
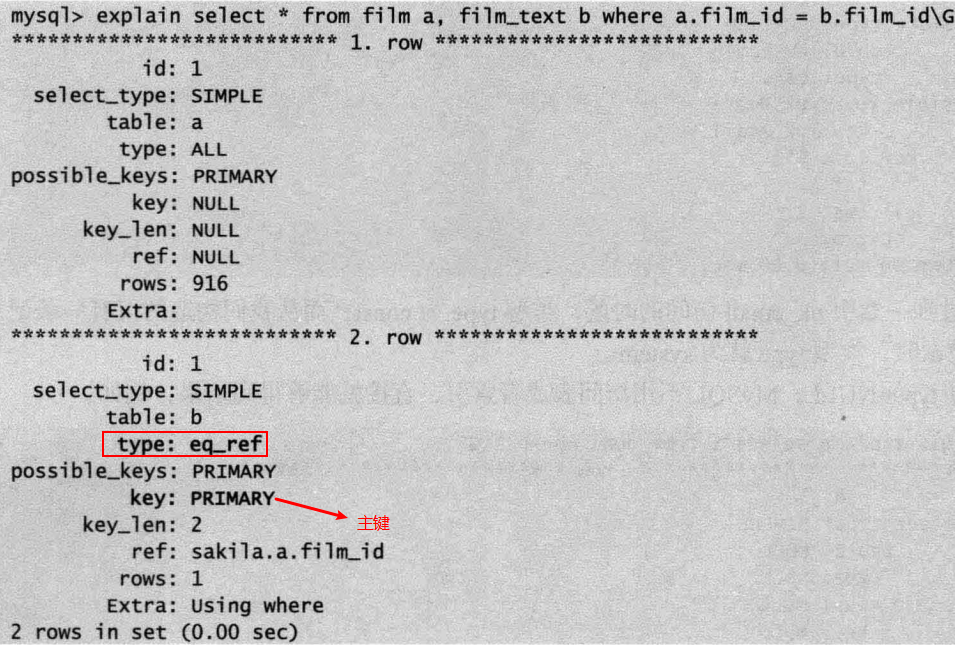 )
)
⑤ref:使用非唯一索引,或唯一索引的前缀扫描,返回匹配某个单独值的所有行(可能匹配多个行)。
 )
)
ref还经常出现在join操作中
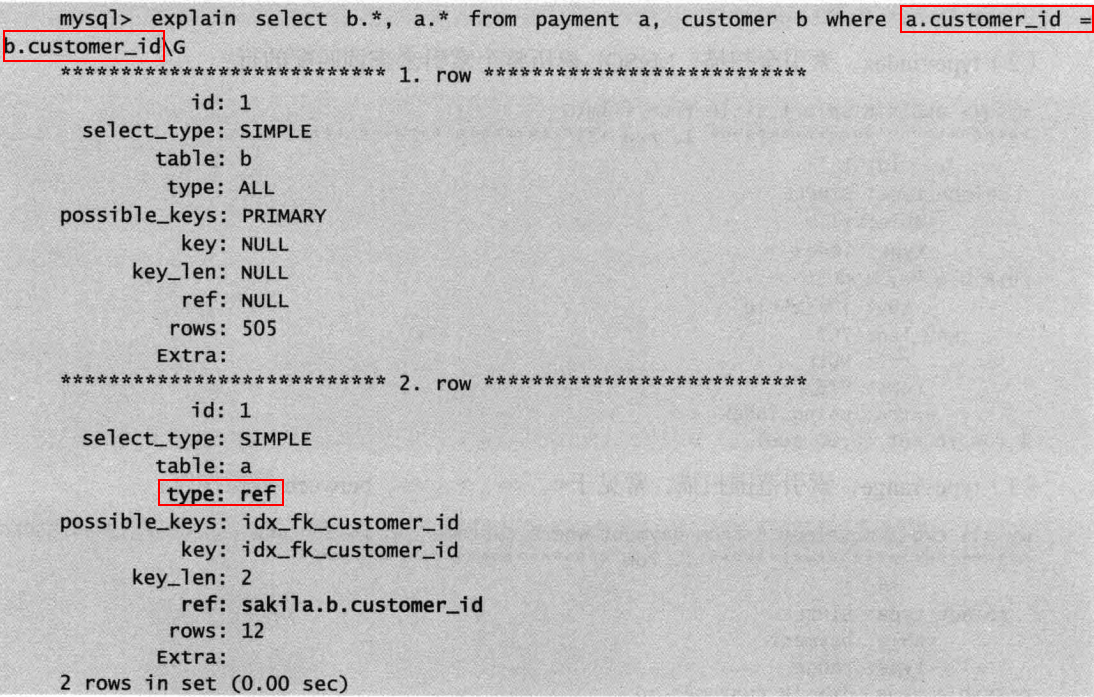
⑥ref_or_null:与ref类似,区别在于条件中包含对NULL的查询。
⑦index_merge:索引合并优化。
⑧unique_subquery:in的后面是一个查询主键字段的子查询。
⑨index_subquery:与unique subquery类似,区别在于in的后面是查询非唯一索引字段的子查询。
⑩range:只检索指定范围的行,使用一个索引来选择行。常见于<,<=,>,>=,between或者IN操作符。
key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。

11.index:索引全扫描。遍历整个索引来查询匹配的行。

12.ALL:全表扫描,性能最差。

possible_keys和key
possible_keys表示查询时可能使用到的索引,而key表示实际使用的索引
key_len
表示使用到的索引字段的长度
ref
表示该表的索引字段关联了哪张表的哪个字段
rows
表示扫描行的数量
Extra
表示执行情况的说明和描述。包含不适合在其它列中显示但对执行计划非常重要的额外信息。记录几个重要的:
Using index :使用覆盖索引的时候就会出现
Using where:在查找使用索引的情况下,需要回表去查询所需的数据。表示Mysql将对storage engine提取的结果进行过滤,过滤条件字段无索引;
Using index condition:查找使用了索引,但是需要回表查询数据。会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
Using index & using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
Using filesort:使用了文件排序。当查询语句包含ORDER BY时,如果无法使用索引来完成排序,则需要进行额外的排序操作。
Using temporary:使用临时表来保存中间结果
Oracle
索引
oracle 默认的索引是 B+树索引
索引结构
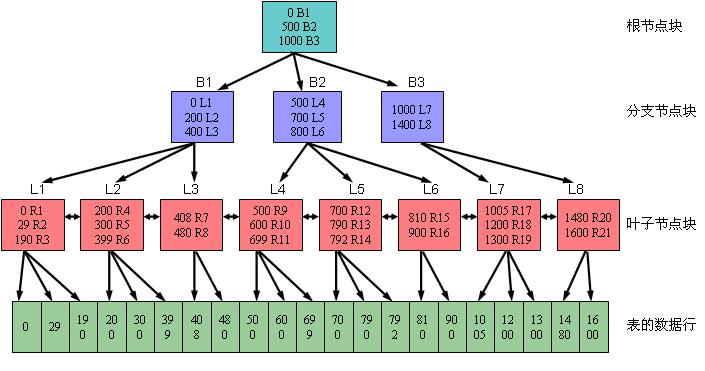
B+ 树索引
位图索引
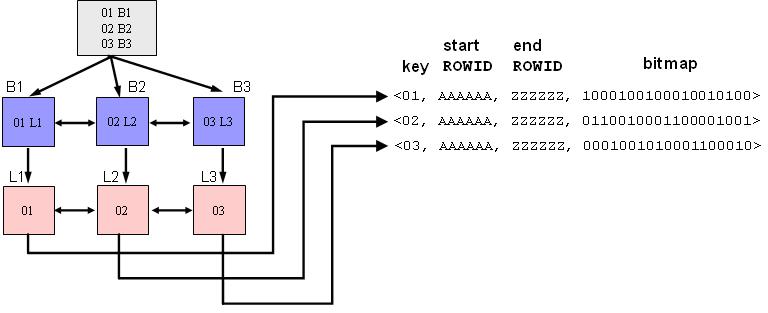
位图索引适合只有几个固定值的列,如性别、婚姻状况、行政区等。
位图可以通过 AND/OR 操作,快速得到查询结果。
此外,位图索引适合静态数据,而不适合索引频繁更新的列。
因为位图索引列的修改会将所有该值的行进行加锁。
锁
优化
最左前缀原则
联合索引的任何前缀索引都会使用到索引查询,(col1, col2, col3) 这个联合索引的所有前缀就是(col1), (col1, col2), (col1, col2, col3) 包含这些列的查询都会启用索引查询,除此之外的查询即时包含了联合索引中的多列也不会启用索引查询。即 (col2), (col3), (col2, col3) 都不会启动(col1, col2, col3) 这个联合索引查询。
禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询
原因:
- 消耗更多的 CPU 和 IO 以网络带宽资源
- 无法使用覆盖索引
- 可减少表结构变更带来的影响
禁止使用不含字段列表的 INSERT 语句
禁止对索引列使用函数
对索引列使用函数会导致索引失效。
将不等于改成 or
将<>a !=a 改成<a or >a,因为不等于用不到索引。
禁止使用左模糊和全模糊条件查询
左模糊 %key 和全模糊 %key% 无法使用索引,只有右模糊 key% 才能使用到索引。
避免使用子查询,可以把子查询优化为 join 操作
通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
子查询性能差的原因:
子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
避免使用 JOIN 关联太多的表
对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 join_buffer_size 参数进行设置。
在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
对应同一列进行 or 判断时,使用 in 代替 or
in 的值不要超过 500 个,in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
禁止使用 order by rand() 进行随机排序
order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
在明显不会有重复值时使用 UNION ALL 而不是 UNION
- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作
- UNION ALL 不会再对结果集进行去重操作
执行计划
Mysql 使用 Explain + select…
比较重要的字段有:
- select_type : 查询类型,有简单查询、联合查询、子查询等
- key : 使用的索引
- rows : 扫描的行数
分库分表
分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。 常见的分库分表工具有:sharding-jdbc(当当)、TSharding(蘑菇街)、MyCAT(基于 Cobar)、Cobar(阿里巴巴)…。
推荐使用 sharding-jdbc 。 因为,sharding-jdbc 是一款轻量级 Java 框架,以 jar 包形式提供服务,不要我们做额外的运维工作,并且兼容性也很好。
- 客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
- 中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
分库分表之后,id 主键如何处理?
- 数据库自增 id : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
- 利用 redis 生成 id : 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
- Twitter的snowflake算法
- 美团的Leaf分布式ID生成系统 :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
MongoDB
面向集合(Collection)和文档(document)的存储,以JSON格式的文档保存数据。
与关系型数据库术语类比
| mongodb | 关系型数据库 |
|---|---|
| Database | Database |
| Collection | Table |
| Document | Record/Row |
| Filed | Column |
| Embedded Documents | Table join |
MongoDB的优势有哪些
- 面向文档的存储:以 BSON 格式的文档保存数据。
- 任何属性都可以建立索引。
- 复制以及高可扩展性。
- 自动分片。
- 丰富的查询功能。
- 快速的即时更新。
- 来自 MongoDB 的专业支持。
BSON VS JSON
BSON 有更快的遍历速度
json需要扫字符串,而bson可以直接定位
json是像字符串一样存储的,bson是按结构存储的
如何执行事务/加锁?
mongodb没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能
在哪些场景使用MongoDB?
规则: 如果业务中存在大量复杂的事务逻辑操作,则不要用MongoDB数据库;在处理非结构化 / 半结构化的大数据使用MongoDB,操作的数据类型为动态时也使用MongoDB,比如:
- 内容管理系统,切面数据、日志记录
- 移动端
Apps:O2O送快递骑手、快递商家的信息(包含位置信息) - 数据管理,监控数据
Linux
命令
lsof
查看端口对应的进程ID
lsof -i:80
1 | iMacDev110:~ libo$ lsof -i:80 |
ps
查看所有Java进程
ps -ef | grep java
1 | iMacDev110:~ libo$ ps -ef | grep java |
top
top命令可以实时动态地查看系统的整体运行情况。
1 | Processes: 438 total, 2 running, 436 sleeping, 2376 threads 11:18:31 |
查看某个进程的内存占用情况
top -p pid
stat
stat命令用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。
grep
日志文件中根据关键词搜索,并加上颜色
grep "orderId" info.log --color=auto
1 | [tomcat8@3f037c3314ba sst-mobile]$ grep "orderId" info.20201117.txt |
vim
cat
tail
netstat
netstat命令用来打印Linux中网络系统的状态信息,可让你得知整个Linux系统的网络情况。
框架
Spring
IoC
@Autowaire 和 @Resource 有什么区别?
- @Autowired 注解是按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false
- @Resource 默认按名称装配,放在 setter 方法上则按属性名装配。可以通过配置其 type 属性来按类型装配。
- @Autowired 结合@Qualifier 可以实现按名称装配。
- @Resources 是 JDK 的注解,@Autowired 是 Spring的注解。
| 注解对比 | @Resource |
@Autowire |
|---|---|---|
| 注解来源 | JDK | Spring |
| 装配方式 | 优先按名称 | 优先按类型 |
| 属性 | name、type | required |
@Autowaire 放在成员变量上和放在set方法上的区别是什么?
放在 setter 上可以对注入的 Bean 做其他的操作,除此之外并无其他区别。
例如:
1 | class DaoDemo{ |
AOP
Spring AOP和AspectJ是什么关系?
其实AOP并不是Spring的专属,AOP最开始是一种编程模型,后来大佬们为了探讨AOP的标准化,统一AOP规范,成立了一个AOP联盟。除了Spring外,AOP的框架有很多,比如AspectJ, AspectWerkz, JBoss-AOP。
最开始,Spring AOP和AspectJ是完全独立的,Spring有自己的实现和使用语法。但是Spring的AOP使用起来太麻烦了,深受大家吐槽。于是Spring支持了广受大家好评的AspectJ语法,通过在配置类上添加@EnableAspectJAutoProxy这个注解来开启对AspectJ的语法。
但Spring仅仅是支持了AspectJ的部分语法(有些语法是不支持的),但底层实现还是自己的一套东西。而且两个框架的目标不同,AspectJ是一套完整的AOP解决方案,更为健壮,但使用起来比较复杂,还需要使用特殊的语法和编译器。而Spring的目的是想要把AOP和IoC框架结合起来,让Spring管理的Bean能够很方便地使用AOP的功能。
所以Spring AOP和AspectJ没啥关系,只是Spring借鉴了Aspect的声明语法。
循环依赖/三级缓存
三级缓存:
- singletonFactories : 进入实例化阶段的单例对象工厂的cache (三级缓存)
- earlySingletonObjects :完成实例化但是尚未初始化的,提前暴光的单例对象的Cache (二级缓存)
- singletonObjects:完成初始化的单例对象的cache(一级缓存)
A,B相互依赖的两个类的创建过程:
- 使用
context.getBean(A.class),旨在获取容器内的单例A(若A不存在,就会走A这个Bean的创建流程),显然初次获取A是不存在的,因此走A的创建之路~ 实例化A(注意此处仅仅是实例化),并将它放进缓存(此时A已经实例化完成,已经可以被引用了)初始化A:@Autowired依赖注入B(此时需要去容器内获取B)- 为了完成依赖注入B,会通过
getBean(B)去容器内找B。但此时B在容器内不存在,就走向B的创建之路~ 实例化B,并将其放入缓存。(此时B也能够被引用了)初始化B,@Autowired依赖注入A(此时需要去容器内获取A)此处重要:初始化B时会调用getBean(A)去容器内找到A,上面我们已经说过了此时候因为A已经实例化完成了并且放进了缓存里,所以这个时候去看缓存里是已经存在A的引用了的,所以getBean(A)能够正常返回- B初始化成功(此时已经注入A成功了,已成功持有A的引用了),return(注意此处return相当于是返回最上面的
getBean(B)这句代码,回到了初始化A的流程中~)。 - 因为B实例已经成功返回了,因此最终A也初始化成功
- 到此,B持有的已经是初始化完成的A,A持有的也是初始化完成的B
为什么需要三级缓存,二级缓存不行吗?
如果没有AOP,其实Spring使用二级缓存就可以解决循环依赖的问题。若使用二级缓存,在AOP情形下,注入到其他Bean的,不是最终的代理对象,而是原始目标对象。
因为Spring对Bean有一个生命周期的定义,而代理对象是在Bean初始化完成后,执行后置处理器的时候生成的。所以不能在二级缓存的时候就直接生成代理对象,放进缓存。
Spring Boot
Spring Boot的主要优点
- 开发基于 Spring 的应用程序很容易。
- Spring Boot 项目所需的开发或工程时间明显减少,通常会提高整体生产力。
- Spring Boot不需要编写大量样板代码、XML配置和注释。
- Spring引导应用程序可以很容易地与Spring生态系统集成,如Spring JDBC、Spring ORM、Spring Data、Spring Security等。
- Spring Boot遵循“固执己见的默认配置”,以减少开发工作(默认配置可以修改)。
- Spring Boot 应用程序提供嵌入式HTTP服务器,如Tomcat和Jetty,可以轻松地开发和测试web应用程序。(这点很赞!普通运行Java程序的方式就能运行基于Spring Boot web 项目,省事很多)
- Spring Boot提供命令行接口(CLI)工具,用于开发和测试Spring Boot应用程序,如Java或Groovy。
- Spring Boot提供了多种插件,可以使用内置工具(如Maven和Gradle)开发和测试Spring Boot应用程序。
Spring Boot 最大的优势是什么?
Spring Boot 的最大的优势是“约定优于配置“。“约定优于配置“是一种软件设计范式,开发人员按照约定的方式来进行编程,可以减少软件开发人员需做决定的数量,获得简单的好处,而又不失灵活性。
Spring Boot 中 “约定优于配置“的具体产品体现在哪里?
Spring Boot Starter、Spring Boot Jpa 都是“约定优于配置“的一种体现。都是通过“约定优于配置“的设计思路来设计的,
Spring Boot Starter 在启动的过程中会根据约定的信息对资源进行初始化;Spring Boot Jpa 通过约定的方式来自动生成 Sql ,避免大量无效代码编写。
Spring Boot Starter 的工作原理是什么?
- Spring Boot 在启动时会去依赖的 Starter 包中寻找 resources/META-INF/spring.factories 文件
- 根据 spring.factories 配置加载 AutoConfigure 类
- 根据 @Conditional 注解的条件,进行自动配置并将 Bean 注入 Spring Context
Spring Boot 在启动的时候,按照约定去读取 Spring Boot Starter 的配置信息,再根据配置信息对资源进行初始化,并注入到 Spring 容器中。这样 Spring Boot 启动完毕后,就已经准备好了一切资源,使用过程中直接注入对应 Bean 资源即可。
Starter
什么是 Spring Boot Starters?
Spring Boot Starters 是一系列依赖关系的集合,因为它的存在,项目的依赖之间的关系对我们来说变的更加简单了。举个例子:在没有Spring Boot Starters之前,我们开发REST服务或Web应用程序时; 我们需要使用像Spring MVC,Tomcat和Jackson这样的库,这些依赖我们需要手动一个一个添加。但是,有了 Spring Boot Starters 我们只需要一个只需添加一个spring-boot-starter-web一个依赖就可以了,这个依赖包含的字依赖中包含了我们开发REST 服务需要的所有依赖。
Spring Boot 的 Starter 有两个作用:
将某个功能/领域所需的依赖集中到一起,可以认为是一个组合依赖。
例如
spring-boot-starter-web就组合了spring-web、spring-webmvc、spring-boot-starter-tomcat等依赖。提供自动配置类给 Spring 完成自动配置
自定义 Starter
引入 SpringBoot 自动化配置依赖:
spring-boot-autoconfigure创建一个 HelloworldService,并定义 sayHello() 方法打印。
1
2
3
4
5
6
7
8public class HelloworldService {
private String words;
public String sayHello() {
return "hello, " + words;
}
}创建属性类,指定配置前缀,读取项目配置文件中的属性。
1
2
3
4
5
6(prefix = "helloworld")
public class HelloworldProperties {
public static final String DEFAULT_WORDS = "world";
private String words = DEFAULT_WORDS;
}创建自动化配置类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 相当于一个普通的 java 配置类
// 当 HelloworldService 在类路径的条件下
({HelloworldService.class})
// 将 application.properties 的相关的属性字段与该类一一对应,并生成 Bean
@EnableConfigurationProperties(HelloworldProperties.class)
public class HelloworldAutoConfiguration {
// 注入属性类
private HelloworldProperties hellowordProperties;
// 当容器没有这个 Bean 的时候才创建这个 Bean
(HelloworldService.class)
public HelloworldService helloworldService() {
HelloworldService helloworldService = new HelloworldService();
helloworldService.setWords(hellowordProperties.getWords());
return helloworldService;
}
}在 META-INF 目录下创建 spring.factories,指定自动配置类。
1
2# Auto Configure
=com.objcoding.starters.helloworld.HelloworldAutoConfiguration使用
引用自定义的 Starter
在主配置文件中配置响应的配置属性。
在需要的地方通过
@Autowired注入 HelloworldService,然后调用它的sayHello()方法。
自动配置
Spring Boot 项目启动时会扫描所有所有依赖 jar 包下的 spring.factories 文件,将其中的自动配置类注册到 Spring IoC 容器中。
Spring Boot 项目的启动注解@SpringBootApplication 由下面三个注解组成:
- @Configuration
- @ComponentScan
- @EnableAutoConfiguration
其中 @EnableAutoConfiguration 是实现自动配置的入口,该注解又通过 @Import 注解导入了AutoConfigurationImportSelector,在该类中 getCandidateConfigurations 方法会通过 SpringFactoriesLoader.loadFactoryNames() 加载所有 spring.factories 文件中指定的自动配置类。
这些自动配置类中会使用 @EnableConfigurationProperties 注解指定相应的配置属性类,配置属性类中通过 @ConfigurationProperties(prefix = "xxx") 读取主配置文件中相应前缀的配置选项。通过 Conditional 相关注解指定加载相关的服务类(例如 RedisTemplate,RestTemplate),并将配置类中的配置设置到服务类中,最终通过 @Bean 实例化服务类并注入到容器中。
启动流程
过滤器
过滤器的配置比较简单,直接实现Filter 接口即可,也可以通过@WebFilter注解实现对特定URL拦截,看到Filter 接口中定义了三个方法。
init():该方法在容器启动初始化过滤器时被调用,它在Filter的整个生命周期只会被调用一次。注意:这个方法必须执行成功,否则过滤器会不起作用。doFilter():容器中的每一次请求都会调用该方法,FilterChain用来调用下一个过滤器Filter。destroy(): 当容器销毁 过滤器实例时调用该方法,一般在方法中销毁或关闭资源,在过滤器Filter的整个生命周期也只会被调用一次
1 | @Component |
执行顺序
过滤器用@Order注解控制执行顺序,通过@Order控制过滤器的级别,值越小级别越高越先执行。
拦截器
拦截器它是链式调用,一个应用中可以同时存在多个拦截器Interceptor, 一个请求也可以触发多个拦截器 ,而每个拦截器的调用会依据它的声明顺序依次执行。
首先编写一个简单的拦截器处理类,请求的拦截是通过HandlerInterceptor 来实现,看到HandlerInterceptor 接口中也定义了三个方法。
preHandle():这个方法将在请求处理之前进行调用。注意:如果该方法的返回值为false,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。postHandle():只有在preHandle()方法返回值为true时才会执行。会在Controller 中的方法调用之后,DispatcherServlet 返回渲染视图之前被调用。 有意思的是:postHandle()方法被调用的顺序跟preHandle()是相反的,先声明的拦截器preHandle()方法先执行,而postHandle()方法反而会后执行。afterCompletion():只有在preHandle()方法返回值为true时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。
1 | @Component |
将自定义好的拦截器处理类进行注册,并通过addPathPatterns、excludePathPatterns等属性设置需要拦截或需要排除的 URL。
1 | @Configuration |
执行顺序
拦截器默认的执行顺序,就是它的注册顺序,可以通过order属性手动设置控制,值越小越先执行。
1 |
|
过滤器与拦截器的区别
- Filter是基于函数回调的,而Interceptor则是基于Java反射的。
- Filter依赖于Servlet容器,因此只能在web环境使用,而Interceptor不依赖于Servlet容器。不仅能应用在
web程序中,也可以用于Application、Swing等程序中。 - Filter对几乎所有的请求起作用,而Interceptor只能对action请求起作用。
- Interceptor可以访问Action的上下文,值栈里的对象,而Filter不能。
- 在action的生命周期里,Interceptor可以被多次调用,而Filter只能在容器初始化时调用一次。
过滤器与拦截器的顺序
过滤前-拦截前-action执行-拦截后-过滤后
过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
MyBatis
多数据源
在开发过程中,避免不了需要同时操作多个数据库的情况,通常的应用场景如下 :
数据库高性能场景:
主从,包括一主一从,一主多从等,在主库进行增删改操作,在从库进行读操作。
数据库高可用场景:
主备,包括一往一备,多主多备等,在数据库无法访问时可以切换。
同构或异构数据的业务处理:
需要处理的数据存储在不同的数据库中,包括同构(如都是 MySQL ),异构(如一个 MySQL ,另外是 PG 或者 Oracle )。
多数据源一般有三个策略:
重点看动态数据源就可以了
多套数据源:
即针对每个数据库建立一套数据处理逻辑,每套数据库都包括数据源配置、会话工厂( sessionFactory )、连接、SQL 操作、实体。各套数据库相互独立。
动态数据源:
确定数量的多个数据源共用一个会话工厂,根据条件动态选取数据源进行连接、SQL 操作。
参数化变更数据源:
根据参数添加数据源,并进行数据源切换,数据源数量不确定。通常用于对多个数据库的管理工作。
多套数据源
配置数据库连接信息
1 | # master |
配置数据源
1 |
|
配置 session 工厂
1 |
|
多套实体类、DAO、Mapper
对应创建多套实体类,DAO接口类,Mapper.xml 文件。
使用
客户端要操作哪个数据库,就选取对应的 Dao 接口进行操作就可以了。
优点
简单、直接:
一个库对应一套处理方式,很好理解。
符合开闭原则( OCP ):
设计模式告诉我们,对扩展开放,对修改关闭,添加多一个数据库,原来的那一套不需要改动,只添加即可。
缺点
资源浪费:
针对每一个数据源写一套操作,连接数据库的资源也是独立的,分别占用同样多的资源。
SqlSessionFactory是一个工厂,建议是使用单例,完全可以重用,不需要建立多个,只需要更改数据源即可,跟多线程,使用线程池减少资源消耗是同一道理。代码冗余:
在前面的多数据源配置中可以看出,其实 master 和 slave 的很多操作是一样的,只是改个名称而已,因此会造成代码冗余。
缺乏灵活:
所有需要使用的地方都需要引入对应的 mapper,对于很多操作,只是选择的数据源不一样,代码逻辑是一致的。另外,对于一主多从的情况,若需要对多个从库进行负载均衡,相对比较麻烦。
正因为有上述的缺点,所以还有改进的空间。于是就有了动态数据源。
动态数据源
配置数据库连接信息
1 | # master |
配置数据源
1 |
|
配置动态数据源
添加动态数据源类
1
2
3
4
5
6
7public class DynamicDataSource extends AbstractRoutingDataSource {
protected Object determineCurrentLookupKey() {
// 此处暂时返回固定 master 数据源, 后面按动态策略修改
return DataSourceConstants.DS_KEY_MASTER;
}
}设置动态数据源为主数据源
1
2
3
4
5
6
7
8
9
10
11
12
13
public DataSource dynamicDataSource() {
Map<Object, Object> dataSourceMap = new HashMap<>(2);
dataSourceMap.put(DataSourceConstants.DS_KEY_MASTER, masterDataSource());
dataSourceMap.put(DataSourceConstants.DS_KEY_SLAVE, slaveDataSource());
//设置动态数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(dataSourceMap);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource());
return dynamicDataSource;
}注意,需要在
DynamicDataSourceConfig中,排除DataSourceAutoConfiguration的自动配置,否则会出现The dependencies of some of the beans in the application context form a cycle的错误。1
(exclude = { DataSourceAutoConfiguration.class })
动态数据源切换器
前面固定写了一个数据源路由策略,总是返回 master,显然不是我们想要的。我们想要的是在需要的地方,想切换就切换。因此,需要有一个动态获取数据源 key 的地方(我们称为上下文),对于 web 应用,访问以线程为单位,使用 ThreadLocal 就比较合适,如下:
1 | public class DynamicDataSourceContextHolder { |
设置动态数据源 DynamicDataSource 路由策略
修改前面 DynamicDataSource 的 determineCurrentLookupKey 方法如下:
1 |
|
直接使用切换器切换数据源
1 | ("/listall") |
使用自定义注解切换数据源
自定义注解 DS
1 | ({ElementType.METHOD,ElementType.TYPE}) |
定义切面
1 |
|
在方法/类上使用自定义注解
1 | /** |
缺点
对于动态数据源,还有哪些地方需要考虑或者说值得改进的地方呢?
- 事务如何处理?其实在开发中应该尽量避免跨库事务,但如果避免不了,则需要使用分布式事务。
- 对于当前的动态数据源,相对来说还是固定的数据源(如一主一从,一主多从等),即在编码时已经确定的数据库数量,只是在具体使用哪一个时进行动态处理。如果数据源本身并不确定,或者说需要根据用户输入来连接数据库,这时,如何处理呢?这种情况出现得比较多的是在对多个数据库进行管理时的处理。这种情况,我将在下一篇文章中进行讲解,我把它叫做”参数化变更数据源”。
#{}和${}的区别是什么?
#{value} 会将value添加上双引号,而 ${} 则是原封不动的插入 sql,会导致 sql 注入问题。
Xml 映射文件中,除了常见的 select|insert|updae|delete 标签之外,还有哪些标签?
<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态 sql 的 9 个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中为 sql 片段标签,通过<include>标签引入 sql 片段,<selectKey>为不支持自增的主键生成策略标签。
MyBatis 是否支持延迟加载?如果支持,它的实现原理是什么?
MyBatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 MyBatis 配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用 a.getB().getName(),拦截器 invoke()方法发现 a.getB()是 null 值,那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,然后调用 a.setB(b),于是 a 的对象 b 属性就有值了,接着完成 a.getB().getName()方法的调用。这就是延迟加载的基本原理。
为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而 MyBatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
Spring Cloud
什么是 Spring Cloud
Spring Cloud provides tools for developers to quickly build some of the common patterns in distributed systems.
Spring Cloud 为开发人员提供了在分布式系统中快速构建一些常见模式的工具。
Spring Cloud 就是微服务系统架构的一站式解决方案,在构建微服务的过程中需要做注册中心 、配置中心 、服务网关 、数据监控等等,而 Spring Cloud 为我们提供了一套简易的编程模型,使我们能在 Spring Boot 的基础上轻松地实现微服务项目的构建。
重要组件
Eureka服务发现框架Ribbon进程内负载均衡器Open Feign服务调用映射Hystrix服务降级熔断器Zuul微服务网关Config微服务统一配置中心Bus消息总线
服务注册管理中心 Eureka
Eureka 就是一个服务发现框架。主要提供服务注册和服务发现两大功能。
其实就是服务提供者和服务消费者之间的“桥梁/中介”,服务提供者可以把自己注册到服务中介那里,而服务消费者如需要消费一些服务就可以在服务中介中寻找注册在服务中介的服务提供者。
服务注册
当 Eureka 客户端向 Eureka Server 注册时,它提供自身的元数据,比如IP地址、端口,运行状况指示符URL,主页等。
心跳连接
Eureka 客户端默认情况下会每隔30秒发送一次心跳连接。用来告知 Eureka Server 该 Eureka 客户仍然存活,没有出现问题。
正常情况下,如果 Eureka Server 在90秒没有收到 Eureka 客户的续约,它会将实例从其注册表中删除。
服务发现
Eureka 客户端从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。
服务下线
Eureka 客户端在程序关闭时向Eureka服务器发送取消请求。发送请求后,该客户端实例信息将从服务器的实例注册表中删除。
该下线请求不会自动完成,它需要调用以下内容:DiscoveryManager.getInstance().shutdownComponent();
自我保护机制
如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
与 zookeeper 的区别
CAP 理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
CAP:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance(分区容错性)
BASE:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
Zookeeper保证CP
zk 会出现这样的情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。
选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
Eureka保证AP
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。
而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
除此之外,Eureka还有一种自我保护机制。
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
负载均衡器 Ribbon
RestTemplate是Spring提供的一个访问Http服务的客户端类,微服务之间的调用是使用的RestTemplate。
Ribbon 是一个客户端内的负载均衡器,运行在消费者端。
负载均衡算法
RoundRobinRule:轮询策略。Ribbon默认采用的策略。若经过一轮轮询没有找到可用的provider,其最多轮询 10 轮。若最终还没有找到,则返回null。RandomRule: 随机策略,从所有可用的provider中随机选择一个。RetryRule: 重试策略。先按照RoundRobinRule策略获取provider,若获取失败,则在指定的时限内重试。默认的时限为 500 毫秒。
Nginx 和 Ribbon 的对比
提到 负载均衡 就不得不提到大名鼎鼎的 Nignx 了,而和 Ribbon 不同的是,Nginx 是一种集中式的负载均衡器。
何为集中式呢?简单理解就是 将所有请求都集中起来,然后再进行负载均衡。
在 Nginx 中请求是先进入负载均衡器,而在 Ribbon 中是先在客户端进行负载均衡才进行请求的。
服务调用 OpenFeign
OpenFeign运行在消费者端,使用Ribbon进行负载均衡,所以OpenFeign直接内置了Ribbon。
Spring Cloud OpenFeign 是基于Ribbon和Hystrix的声明式服务调用组件,可以动态创建基于Spring MVC注解的接口实现用于服务调用,在Spring Cloud 2.0中已经取代Feign成为了一等公民。
Hystrix
Hystrix 就是一个能进行 熔断 和 降级 的库,通过使用它能提高整个系统的弹性。
服务熔断
熔断 是指的 Hystrix 中的 断路器模式 ,你可以使用简单的 @HystrixCommand 注解来标注某个服务调用接口,这样 Hystrix 就会使用 断路器 来“包装”这个方法,每当调用时间超过指定时间时(默认为1000ms),断路器将会中断对这个方法的调用。
1 | ( |
服务降级
降级是为了更好的用户体验,当一个服务调用异常时,通过执行另一种代码逻辑来给用户友好的回复。这也就对应着 Hystrix 的 后备处理 模式。你可以通过设置 fallbackMethod 来给一个方法设置备用的代码逻辑。
比如有一个热点新闻,大量用户同时访问可能会导致系统崩溃,那么我们就进行 服务降级 ,一些请求会做一些降级处理比如当前人数太多请稍后查看等等。
1 | // 指定了后备方法调用 |
服务网关 Zuul
网关是系统唯一对外的入口,介于客户端与服务器端之间,用于对请求进行鉴权、限流、 路由、监控等功能。
Zuul 中最关键的就是 路由和过滤器
Zuul 需要向 Eureka 进行注册,然后在启动类上加入 @EnableZuulProxy 注解。
路由
统一前缀
1 | zuul: |
服务别名
1 | zuul: |
服务名屏蔽
在配置完路由策略之后使用微服务名称还是可以访问的,这个时候需要将服务名屏蔽。
1 | zuul: |
路径屏蔽
Zuul 还可以指定屏蔽掉的路径 URI,即只要用户请求中包含指定的 URI 路径,那么该请求将无法访问到指定的服务。通过该方式可以限制用户的权限。
1 | zuul: |
敏感请求头屏蔽
默认情况下,像 Cookie、Set-Cookie 等敏感请求头信息会被 zuul 屏蔽掉,我们可以将这些默认屏蔽去掉,当然,也可以添加要屏蔽的请求头。
过滤
如果说路由功能是 Zuul 的基操的话,那么过滤器就是 Zuul的利器了。可以进行各种过滤,这样我们就能实现 限流,灰度发布,权限控制 等等。
要实现自己的 Filter 只需要继承 ZuulFilter 然后将这个过滤器类以 @Component 注解加入 Spring 容器中就行了。
令牌桶限流
首先会有个令牌桶,如果里面没有满那么就会以一定 固定的速率 会往里面放令牌,一个请求过来首先要从桶中获取令牌,如果没有获取到,那么就拒绝,如果获取到那么就放行。
配置中心 Config
什么是 Spring Cloud Config
Spring Cloud Config为分布式系统中的外部化配置提供服务器和客户端支持。使用Config服务器,可以在中心位置管理所有环境中应用程序的外部属性。
Spring Cloud Config 就是能将各个 服务/应用/系统/模块 的配置文件存放到 统一的地方(e.g. Git)然后进行管理。
应用只有启动的时候才会进行配置文件的加载,那么我们的 Spring Cloud Config 就暴露出一个接口给启动应用来获取它所想要的配置文件,应用获取到配置文件然后再进行它的初始化工作。
如果应用运行时去更改远程配置仓库(Git)中的对应配置文件,那么依赖于这个配置文件的已启动的应用会不会进行其相应配置的更改呢?答案是不会的。
可以使用 Webhooks ,这是 github 提供的功能,它能确保远程库的配置文件更新后客户端中的配置信息也得到更新。
但是生产环境不会使用。一般会使用 Bus 消息总线 + Spring Cloud Config 进行配置的动态刷新。
消息总线 Bus
用于将服务和服务实例与分布式消息系统链接在一起的事件总线。
Spring Cloud Bus 的作用就是管理和广播分布式系统中的消息,也就是消息引擎系统中的广播模式。
Spring Cloud 与 Spring Cloud Alibaba 的区别
我们平常说的 Spring Cloud 其实是指 Spring Cloud 其中的一种实现方式,即 Spring Cloud Netflix,而 Spring Cloud Alibaba 则是另一套实现方式。

服务器
Tomcat
Nginx
负载均衡的6种策略
轮询(默认)
1
2
3
4upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
}指定权重
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。1
2
3
4upstream backserver {
server 192.168.0.14 weight=8;
server 192.168.0.15 weight=10;
}权重越高,访问概率越大。
ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session共享问题。
1
2
3
4
5upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}最少连接
1
2
3
4
5upstream item { # item名字可以自定义
least_conn;
server 192.168.101.60:81;
server 192.168.101.77:80;
}fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。1
2
3
4
5upstream backserver {
server server1;
server server2;
fair;
}url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。1
2
3
4
5
6upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
最后需要在server.location中指定上面定义的upstream
1 | server{ |
负载均衡参数
1 | 下面的参数可同时配置,使用空格分开即可 |
缓存
Redis
数据结构
Redis有5个基本数据结构,string、list、hash、set和zset。
string
Redis的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。
当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。
字符串最大长度为512M。
初始化字符串
需要提供「变量名称」和「变量的内容」
1 | > set ireader beijing.zhangyue.keji.gufen.youxian.gongsi |
获取字符串的内容
提供「变量名称」
1 | > get ireader |
获取字符串的长度
提供「变量名称」
1 | > strlen ireader |
获取子串
提供「变量名称」以及开始和结束位置[start, end]
1 | > getrange ireader 28 34 |
覆盖子串
提供「变量名称」以及开始位置和目标子串
1 | > setrange ireader 28 wooxian |
追加子串
1 | > append ireader .hao |
字符串没有提供子串插入方法和子串删除方法。
计数器
如果字符串的内容是一个整数,那么还可以将字符串当成计数器来使用。
1 | > set ireader 42 |
计数器是有范围的,它不能超过Long.Max,不能低于Long.MIN
1 | > set ireader 9223372036854775807 |
过期和删除
字符串可以使用del指令进行主动删除,可以使用expire指令设置过期时间,到点会自动删除,这属于被动删除。可以使用ttl指令获取字符串的寿命。
1 | > expire ireader 60 |
list
Redis将列表数据结构命名为list而不是array,是因为列表的存储结构用的是链表而不是数组,而且链表还是双向链表。因为它是链表,所以随机定位性能较弱,首尾插入删除性能较优。
负下标
链表元素的位置使用自然数0,1,2,....n-1表示,还可以使用负数-1,-2,...-n来表示,-1表示「倒数第一」,-2表示「倒数第二」,那么-n就表示第一个元素,对应的下标为0。
队列/堆栈
链表可以从表头和表尾追加和移除元素,结合使用 rpush/rpop/lpush/lpop 四条指令,可以将链表作为队列或堆栈使用,左向右向进行都可以。
1 | # 右进左出 |
在日常应用中,列表常用来作为异步队列来使用。
长度
使用llen指令获取链表长度
1 | > rpush ireader go java python |
随机读
可以使用 lindex 指令访问指定位置的元素。
使用 lrange 指令来获取链表子元素列表,提供start和end下标参数
1 | > rpush ireader go java python |
修改元素
使用lset指令修改指定位置的元素。
1 | > rpush ireader go java python |
插入元素
使用linsert指令在列表的中间位置插入元素,linsert指令里增加了方向参数before/after来显示指示前置和后置插入。
不过linsert指令并不是通过指定位置来插入,而是通过指定具体的值。这是因为在分布式环境下,列表的元素总是频繁变动的,意味着上一时刻计算的元素下标在下一时刻可能就不是你所期望的下标了。
1 | > rpush ireader go java python |
删除元素
列表的删除操作也不是通过指定下标来确定元素的,你需要指定删除的最大个数以及元素的值
1 | > rpush ireader go java python |
定长列表
在实际应用场景中,我们有时候会遇到「定长列表」的需求。比如要以走马灯的形式实时显示中奖用户名列表,因为中奖用户实在太多,能显示的数量一般不超过100条,那么这里就会使用到定长列表。维持定长列表的指令是ltrim,需要提供两个参数start和end,表示需要保留列表的下标范围,范围之外的所有元素都将被移除。
1 | > rpush ireader go java python javascript ruby erlang rust cpp |
如果指定参数的end对应的真实下标小于start,其效果等价于del指令,因为这样的参数表示需要需要保留列表元素的下标范围为空。
快速列表
如果再深入一点,你会发现Redis底层存储的还不是一个简单的linkedlist,而是称之为快速链表quicklist的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的冗余空间。
hash
哈希等价于Java语言的HashMap,在实现结构上它使用二维结构,第一维是数组,第二维是链表,hash的内容key和value存放在链表中,数组里存放的是链表的头指针。通过key查找元素时,先计算key的hashcode,然后用hashcode对数组的长度进行取模定位到链表的表头,再对链表进行遍历获取到相应的value值,链表的作用就是用来将产生了「hash碰撞」的元素串起来。Java语言开发者会感到非常熟悉,因为这样的结构和HashMap是没有区别的。哈希的第一维数组的长度也是2^n。
增加元素
可以使用hset一次增加一个键值对,也可以使用hmset一次增加多个键值对
1 | > hset ireader go fast |
获取元素
可以通过hget定位具体key对应的value,可以通过hmget获取多个key对应的value,可以使用hgetall获取所有的键值对,可以使用hkeys和hvals分别获取所有的key列表和value列表。这些操作和Java语言的Map接口是类似的。
1 | > hmset ireader go fast java fast python slow |
删除元素
可以使用hdel删除指定key,hdel支持同时删除多个key
1 | > hmset ireader go fast java fast python slow |
判断元素是否存在
通常我们使用hget获得key对应的value是否为空就直到对应的元素是否存在了,不过如果value的字符串长度特别大,通过这种方式来判断元素存在与否就略显浪费,这时可以使用hexists指令。
1 | > hmset ireader go fast java fast python slow |
计数器
hash结构还可以当成计数器来使用,对于内部的每一个key都可以作为独立的计数器。如果value值不是整数,调用hincrby指令会出错。
1 | > hincrby ireader go 1 |
扩容
当hash内部的元素比较拥挤时(hash碰撞比较频繁),就需要进行扩容。扩容需要申请新的两倍大小的数组,然后将所有的键值对重新分配到新的数组下标对应的链表中(rehash)。
如果hash结构很大,比如有上百万个键值对,那么一次完整rehash的过程就会耗时很长。这对于单线程的Redis里来说有点压力山大。所以Redis采用了渐进式rehash的方案。它会同时保留两个新旧hash结构,在后续的定时任务以及hash结构的读写指令中将旧结构的元素逐渐迁移到新的结构中。这样就可以避免因扩容导致的线程卡顿现象。
缩容
Redis的hash结构不但有扩容还有缩容,从这一点出发,它要比Java的HashMap要厉害一些,Java的HashMap只有扩容。缩容的原理和扩容是一致的,只不过新的数组大小要比旧数组小一倍。
set
Java 中 HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
增加元素
可以一次增加多个元素
1 | > sadd ireader go java python |
读取元素
使用smembers列出所有元素,
使用scard获取集合长度,
使用srandmember随机获取count个元素,如果不提供count参数,默认为1
1 | > sadd ireader go java python |
删除元素
使用srem删除一到多个元素,使用spop随机删除一个元素
1 | > sadd ireader go java python rust erlang |
判断元素是否存在
使用sismember指令,只能接收单个元素
1 | > sadd ireader go java python rust erlang |
zset
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层实现使用了两个数据结构,第一个是hash,第二个是跳跃列表,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。跳跃列表的目的在于给元素value排序,根据score的范围获取元素列表。
增加元素
通过zadd指令可以增加一到多个value/score对,score放在前面
1 | > zadd ireader 4.0 python |
长度
通过指令zcard可以得到zset的元素个数
1 | > zcard ireader |
删除元素
通过指令zrem可以删除zset中的元素,可以一次删除多个
1 | > zrem ireader go python |
计数器
同hash结构一样,zset也可以作为计数器使用。
1 | > zadd ireader 4.0 python 4.0 java 1.0 go |
获取排名和分数
通过zscore指令获取指定元素的权重,通过zrank指令获取指定元素的正向排名,通过zrevrank指令获取指定元素的反向排名[倒数第一名]。正向是由小到大,负向是由大到小。
1 | > zscore ireader python |
根据排名范围获取元素列表
通过zrange指令指定排名范围参数获取对应的元素列表,携带withscores参数可以一并获取元素的权重。
通过zrevrange指令按负向排名获取元素列表。
1 | > zrange ireader 0 -1 # 获取所有元素 |
根据score范围获取列表
通过zrangebyscore指令指定score范围获取对应的元素列表。通过zrevrangebyscore指令获取倒排元素列表。
参数-inf表示负无穷,+inf表示正无穷。
1 | > zrangebyscore ireader 0 5 |
根据范围移除元素列表
可以通过排名范围,也可以通过score范围来一次性移除多个元素
1 | > zremrangebyrank ireader 0 1 |
跳跃列表
zset内部的排序功能是通过「跳跃列表」数据结构来实现的。
因为zset要支持随机的插入和删除,所以它不好使用数组来表示。我们先看一个普通的链表结构。
我们需要这个链表按照score值进行排序。这意味着当有新元素需要插入时,需要定位到特定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表做不到,那该怎么办?
跳跃列表就是类似于(公司-部门-组长)这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。
「跳跃列表」之所以「跳跃」,是因为内部的元素可能「身兼数职」,比如上图中间的这个元素,同时处于L0、L1和L2层,可以快速在不同层次之间进行「跳跃」。
定位插入点时,先在顶层进行定位,然后下潜到下一级定位,一直下潜到最底层找到合适的位置,将新元素插进去。你也许会问那新插入的元素如何才有机会「身兼数职」呢?
跳跃列表采取一个随机策略来决定新元素可以兼职到第几层,首先L0层肯定是100%了,L1层只有50%的概率,L2层只有25%的概率,L3层只有12.5%的概率,一直随机到最顶层L31层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
单线程
虽然说 Redis 是单线程模型,但是, 实际上,Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
大体上来说,Redis 6.0 之前主要还是单线程处理。
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
为什么 Redis 选择单线程模型
Redis 选择使用单线程模型处理客户端的请求主要还是因为 CPU 不是 Redis 服务器的瓶颈,所以使用多线程模型带来的性能提升并不能抵消它带来的开发成本和维护成本,系统的性能瓶颈也主要在网络 I/O 操作上;
而 Redis 引入多线程操作也是出于性能上的考虑,对于一些大键值对的删除操作,通过多线程非阻塞地释放内存空间也能减少对 Redis 主线程阻塞的时间,提高执行的效率。
单线程的Redis为什么这么快
完全基于内存
采用单线程,避免了不必要的上下文切换。
高效的数据结构
使用I/O多路复用模型,非阻塞IO
I/O多路复用,多路只多个连接,复用指的是复用同一个线程,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求。
过期策略
Redis是如何判断数据是否过期?
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。
Redis的过期策略
过期策略通常有以下三种:
定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
定期过期
每隔一定的时间,会扫描expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
Redis中同时使用了惰性过期和定期过期两种过期策略。
Redis 每隔 100ms 就随机选择一些设置了过期时间的Key,检查它们是否过期,如果过期的话就删除它们。
每秒 10 次:
- 随机测试 20 个带有过期时间的key
- 删除已过期的key
- 如果超过 25% 的key已过期,从步骤 1 重新开始
内存淘汰机制
Redis 提供 6 种数据淘汰策略:
no-eviction(默认)
禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。
volatile-lru(least recently used)
从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
Redis使用的是近似LRU算法。近似LRU算法通过随机采样法淘汰数据,每次随机出5(默认)个key,从里面淘汰掉最近最少使用的key。
volatile-ttl
从已设置过期时间的数据集中挑选将要过期的数据淘汰
volatile-random
从已设置过期时间的数据集中任意选择数据淘汰
allkeys-lru(least recently used)
在键空间中,移除最近最少使用的 key(这个是最常用的)
allkeys-random
从数据集中任意选择数据淘汰
4.0 版本后增加以下两种:
volatile-lfu(least frequently used)
从已设置过期时间的数据集中挑选最不经常使用的数据淘汰
allkeys-lfu(least frequently used)
在键空间中,移除最不经常使用的 key
持久化
Redis 有两种持久化:RDB(快照)和 AOF(追加文件)
注:4.0之后增加了混合方式,结合了 RDB 和 AOF 的优点。
区别:
- RDB 是将内存中数据某一时刻的快照写入二进制文件中。
- AOF 是将每条导致数据变动的指令追加到 aof 文件中。
优缺点:
| RDB | AOF | |
|---|---|---|
| 文件大小 | 小 | 大 |
| 重启时间 | 短 | 长 |
| 数据丢失 | 多 | 少 |
事务
Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务(transaction)功能。
使用 MULTI命令后可以输入多个命令。Redis不会立即执行这些命令,而是将它们放到队列,当调用了EXEC命令将执行所有命令。
但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。
Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。
缓存穿透
什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。
解决办法
参数校验
一些不合法的参数请求直接抛出异常信息返回给客户端。
缓存无效 key
如果缓存和数据库都查不到某个 key 的数据就写一个固定值(e.g. null)到 Redis 中去并设置过期时间
布隆过滤器
把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会继续走下面的流程。
计算元素值的哈希值。根据哈希值,在位数组中把对应下标的值置为 1。
缓存雪崩
什么是缓存雪崩?
缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。
解决办法
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
针对热点缓存失效的情况:
合理设置缓存过期时间(e.g. 随机)
分布式缓存
为了防止缓存服务器宕机出现的缓存雪崩,可以使用分布式缓存,分布式缓存中每一个节点只缓存部分的数据,当某个节点宕机时可以保证其它节点的缓存仍然可用。
缓存预热
避免在系统刚启动不久由于还未将大量数据进行缓存而导致缓存雪崩。
Redis和数据库双写一致性问题
采用 Cache Aside Pattern:
- 读的时候先读缓存,如果缓存不存在的话就读数据库,取出数据库后更新缓存。
- 写的时候,先更新数据库,再删除缓存。
为什么是删除缓存,而不是更新缓存?
- 有两个更新请求A、B,A先与B更新的数据库,但由于网络震荡,B先与A更新了缓存,此时缓存的数据就是脏数据。
- 为了考虑性能。更新了的数据并不一定会立即有新的访问,放在缓存里占内存,还不如直接删除,有新的访问时再放进去就好了,是一种懒加载的思想。
如果删除失败了,导致数据不一致怎么办?
采用延时双删策略,先删除缓存,再更新数据库,更新成功了就延时异步删除缓存。
用 Redis 实现点赞功能
Redis 做消息队列
- 基于List的 LPUSH+BRPOP 的实现
- PUB/SUB,订阅/发布模式
- 基于Sorted-Set的实现
- 基于Stream类型的实现
Redis 做分布式锁
利用 Redis 的 SETNX 和 EXPIRE 命令
加锁命令:
SETNX key value当键不存在时,对键进行设置操作并返回成功,否则返回失败。KEY 是锁的唯一标识,一般按业务来决定命名。
解锁命令:
DEL key通过删除键值对释放锁,以便其他线程可以通过 SETNX 命令来获取锁。
锁超时:
EXPIRE key timeout设置 key 的超时时间,以保证即使锁没有被显式释放,锁也可以在一定时间后自动释放,避免资源被永远锁住。
SETNX 和 EXPIRE 非原子性
如果 SETNX 成功,在设置锁超时时间后,服务器挂掉、重启或网络问题等,导致 EXPIRE 命令没有执行,锁没有设置超时时间变成死锁。
可以通过使用 lua 脚本保证原子性。
Redis在 2.6.12 版本开始,为 SET 命令增加一系列选项:
1 | SET key value[EX seconds][PX milliseconds][NX|XX] |
- EX seconds: 设定过期时间,单位为秒
- PX milliseconds: 设定过期时间,单位为毫秒
- NX: 仅当key不存在时设置值
- XX: 仅当key存在时设置值
set命令的nx选项,就等同于setnx命令
锁误解除
如果线程 A 成功获取到了锁,并且设置了过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁;随后 A 执行完成,线程 A 使用 DEL 命令来释放锁,但此时线程 B 加的锁还没有执行完成,线程 A 实际释放的线程 B 加的锁。
通过在 value 中设置当前线程的标识,在删除之前验证 key 对应的 value 判断锁是否是当前线程持有。可生成一个 UUID 标识当前线程,使用 lua 脚本做验证标识和解锁操作。
超时解锁导致并发
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
A、B 两个线程发生并发显然是不被允许的,一般有两种方式解决该问题:
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
不可重入
可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
在本地记录重入次数,如 Java 中使用 ThreadLocal 进行重入次数统计。
本地记录重入次数虽然高效,但如果考虑到过期时间和本地、Redis 一致性的问题,就会增加代码的复杂性。另一种方式是 Redis hash 数据结构来实现分布式锁,既存锁的标识也对重入次数进行计数。
无法等待锁释放
上述命令执行都是立即返回的,如果客户端可以等待锁释放就无法使用。
- 可以通过客户端轮询的方式解决该问题,当未获取到锁时,等待一段时间重新获取锁,直到成功获取锁或等待超时。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
- 另一种方式是使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。
主备切换
为了保证 Redis 的可用性,一般采用主从方式部署。主从数据同步有异步和同步两种方式,Redis 将指令记录在本地内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一致的状态,一边向主节点反馈同步情况。
在包含主从模式的集群部署方式中,当主节点挂掉时,从节点会取而代之,但客户端无明显感知。当客户端 A 成功加锁,指令还未同步,此时主节点挂掉,从节点提升为主节点,新的主节点没有锁的数据,当客户端 B 加锁时就会成功。
集群脑裂
集群脑裂指因为网络问题,导致 Redis master 节点跟 slave 节点和 sentinel 集群处于不同的网络分区,因为 sentinel 集群无法感知到 master 的存在,所以将 slave 节点提升为 master 节点,此时存在两个不同的 master 节点。Redis Cluster 集群部署方式同理。
当不同的客户端连接不同的 master 节点时,两个客户端可以同时拥有同一把锁。
Redisson 实现简单分布式锁
对于Java用户而言,我们经常使用Jedis,Jedis是Redis的Java客户端,除了Jedis之外,Redisson也是Java的客户端,Jedis是阻塞式I/O,而Redisson底层使用Netty可以实现非阻塞I/O,该客户端是封装了锁的,继承了J.U.C的Lock接口,所以我们可以像使用ReentrantLock一样使用Redisson。
Guava Cache
使用 CacheBuilder 就可以构建一个缓存对象,CacheBuilder使用build链式构建。
消息中间件
RabbitMQ
生产者将消息发给交换器的时候,一般会指定一个 RoutingKey(路由键),用来指定这个消息的路由规则,而这个 RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。
RabbitMQ 中通过 Binding(绑定) 将 Exchange(交换器) 与 Queue(消息队列) 关联起来,在绑定的时候一般会指定一个 BindingKey(绑定建) ,这样 RabbitMQ 就知道如何正确将消息路由到队列了。
Exchange Types(交换器类型)
RabbitMQ 常用的 Exchange Type 有 fanout、direct、topic、headers 这四种。
fanout
fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
direct
direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
topic
topic类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
- RoutingKey 为一个点号“.”分隔的字符串;
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
- BindingKey 中可以存在两种特殊字符串
*和#,用于做模糊匹配,其中*用于匹配一个单词,#用于匹配多个单词(可以是零个)。
headers(不推荐)
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。
如何保证消息不丢失?
- 消费者端通过 confirm 机制,保证消息投递不丢失
- rabbitMq端通过持久化保证消息不丢失
- 消费者端通过手动ack机制保障消息正常消费
Kafka
Elasticsearch
Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。 它被用作全文检索、结构化搜索、分析以及这三个功能的组合。例如 GitHub 使用 Elasticsearch 对1300亿行代码进行查询。
应用场景
日志实时分析
日志分析是 ES 应用最广泛的领域,支持全栈的日志分析
搜索服务
文档的全文检索、电商平台商品的搜索。
数据分析
为什么 Elasticsearch 那么快?
Elasticsearch 基于 Apache Lucene,Lucene 实现快速搜索的核心就是倒排索引。
倒排索引
将文档中的单词作为索引,将文档ID作为记录的索引结构称为倒排索引。
核心概念
Term:文档拆分后的单词与文档ID的映射。
Term Dictionary:所有单词组成的二叉排序树,根据 Term Dictionary 可以快速定位到 Term。
Term Index:单词前缀的二叉排序树,根据 Term Index 可以快速定位到 Term Dictionary。
Term Index 以FST(finite state transducers)的形式保存在内存中,FST特点是非常节省内存。
Term dictionary在磁盘上是以分快的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary可以更节约磁盘空间。
容器
Docker
命令
在 docker 中执行 bash 命令
docker exec -it set-mobile_qa /bin/bash
操作系统
架构
前后端分离
要理解前后端分离,首先要理解什么是前端,什么是后端。
在系统架构中,前端是负责系统的界面样式、视觉呈现以及和用户交互的部分,后端是负责数据处理的部分。负责这两部分开发的人就是前后端工程师。
前后端未分离的项目中,HTML页面和数据处理包含在同一个项目里,部署在单个服务器中。客户端(浏览器)发送请求到服务器,服务器查询数据库,再对数据进行相应处理,最后再生成相应的HTML文件,将生成的HTML文件返回给客户端。
这个阶段前端工程师负责编写网页模版,之后交给后端工程师,后端工程师则将数据嵌入到网页模版中。
前后端半分离的项目是HTML网页
将网页模版和数据填充逻辑分离成前端项目,后端项目只负责数据处理。前后端项目分别独立开发和部署,通过HTTP协议传递数据。此时客户端访问前端项目获取HTML、CSS、JS等文件,再通过js向后端发送ajax请求获取数据,
一个项目包括视图展示和数据处理两大部分,视图展示就是前端,数据处理就是后端。
SSH
SSM
微服务
服务雪崩
服务雪崩就是一个服务的不可用导致了整个调用链上的服务集体雪崩。
服务熔断
所谓 熔断 就是服务雪崩的一种有效解决方案。当指定时间窗内的请求失败率达到设定阈值时,系统将通过 断路器 直接将此请求链路断开。
服务降级
RPC
RPC 解决了什么问题?
让分布式或者微服务系统中不同服务之间的调用像本地调用一样简单。
既有 HTTP ,为啥用 RPC 进行服务调用?
RPC 只是一种概念、一种设计,就是为了解决 不同服务之间的调用问题, 它一般会包含有 传输协议 和 序列化协议 这两个。
但是,HTTP 是一种协议,RPC框架可以使用 HTTP 协议作为传输协议或者直接使用TCP 作为传输协议,使用不同的协议一般也是为了适应不同的场景。
REST和RPC
分布式
分布式、集群、微服务、SOA 之间的区别
- 分布式
- 不同模块部署在不同服务器上,
- 集群
- 多台服务器部署相模块构成集群,通过负载均衡对外提供服务。
- SOA
- 面向服务的架构(Service Oriented Architecture),把系统按照实际业务,拆分成刚刚好大小的、合适的、独立部署的模块,每个模块之间相互独立。
- 微服务
- 微服务是SOA架构演进的结果。是一种比较现代化的细粒度的SOA实现方式。
TCC
两段式(2PC)
三段式(3PC)
集群
前端
HTML
CSS
JS
Vue
$nextTick
项目
工作中遇到的最难的问题是什么?
新开启的项目为了进度,需要在老项目的基础上移植一些代码,重组拼装。这个时候在时间与质量之间需要做出权衡。重构 or 搬运。是一个很难选择的问题。先前项目都是外包人员开发的。项目质量差,依赖多,继承深。让你无从下手,感觉很绝望。很大一部分的代码公司还申请了专利。这个时候,不是说你秀 runtime 技巧或者流畅、性能优化就能完美完成的。你要站在软件工程的角度思考问题。代码不可用的问题需要在我这里打住。业务功能分离专注。适当挑战新的技术点,比如使用 http2,coap 等等一些新的通信协议带来的未知挑战。使用 swift 或者 oc 是个很难选择的问题。现在葱一开始,坚持写测试用例。面向对象编码。哦,还要提高编码速度,因为与此同时,老板又在催进度,我还是得维持我是一个靠谱的人,坚持我输出的代码,必属精品的追求有莫有?
工作中遇到的最有成就感的是什么?
HR
离职原因
公司规模
什么是嵌入式服务器?我们为什么要使用嵌入式服务器呢?
思考一下在你的虚拟机上部署应用程序需要些什么。
第一步:安装 Java
第二部:安装 Web 或者是应用程序的服务器(Tomat/Wbesphere/Weblogic 等等)
第三部:部署应用程序 war 包
如果我们想简化这些步骤,应该如何做呢?
让我们来思考如何使服务器成为应用程序的一部分?
你只需要一个安装了 Java 的虚拟机,就可以直接在上面部署应用程序了,
是不是很爽?
这个想法是嵌入式服务器的起源。
当我们创建一个可以部署的应用程序的时候,我们将会把服务器(例如,tomcat)嵌入到可部署的服务器中。
例如,对于一个 Spring Boot 应用程序来说,你可以生成一个包含 Embedded Tomcat 的应用程序 jar。你就可以像运行正常 Java 应用程序一样来运行 web 应用程序了。
嵌入式服务器就是我们的可执行单元包含服务器的二进制文件(例如,tomcat.jar)。
3、微服务同时调用多个接口,怎么支持事务的啊?
支持分布式事务,可以使用Spring Boot集成 Aatomikos来解决,但是我一般不建议这样使用,因为使用分布式事务会增加请求的响应时间,影响系统的TPS。一般在实际工作中,会利用消息的补偿机制来处理分布式的事务。
4、shiro和oauth还有cas他们之间的关系是什么?问下您公司权限是如何设计,还有就是这几个概念的区别。
cas和oauth是一个解决单点登录的组件,shiro主要是负责权限安全方面的工作,所以功能点不一致。但往往需要单点登陆和权限控制一起来使用,所以就有 cas+shiro或者oauth+shiro这样的组合。
token一般是客户端登录后服务端生成的令牌,每次访问服务端会进行校验,一般保存到内存即可,也可以放到其他介质;redis可以做Session共享,如果前端web服务器有几台负载,但是需要保持用户登录的状态,这场景使用比较常见。
我们公司使用oauth+shiro这样的方式来做后台权限的管理,oauth负责多后台统一登录认证,shiro负责给登录用户赋予不同的访问权限。
5、各服务之间通信,对Restful和Rpc这2种方式如何做选择?
在传统的SOA治理中,使用rpc的居多;Spring Cloud默认使用restful进行服务之间的通讯。rpc通讯效率会比restful要高一些,但是对于大多数公司来讲,这点效率影响甚微。我建议使用restful这种方式,易于在不同语言实现的服务之间通讯。
6、怎么设计无状态服务?
对于无状态服务,首先说一下什么是状态:如果一个数据需要被多个服务共享,才能完成一笔交易,那么这个数据被称为状态。进而依赖这个“状态”数据的服务被称为有状态服务,反之称为无状态服务。
那么这个无状态服务原则并不是说在微服务架构里就不允许存在状态,表达的真实意思是要把有状态的业务服务改变为无状态的计算类服务,那么状态数据也就相应的迁移到对应的“有状态数据服务”中。
场景说明:例如我们以前在本地内存中建立的数据缓存、Session缓存,到现在的微服务架构中就应该把这些数据迁移到分布式缓存中存储,让业务服务变成一个无状态的计算节点。迁移后,就可以做到按需动态伸缩,微服务应用在运行时动态增删节点,就不再需要考虑缓存数据如何同步的问题。
7、Spring Cache 三种常用的缓存注解和意义?
@Cacheable ,用来声明方法是可缓存,将结果存储到缓存中以便后续使用相同参数调用时不需执行实际的方法,直接从缓存中取值。
@CachePut,使用 @CachePut 标注的方法在执行前,不会去检查缓存中是否存在之前执行过的结果,而是每次都会执行该方法,并将执行结果以键值对的形式存入指定的缓存中。
@CacheEvict,是用来标注在需要清除缓存元素的方法或类上的,当标记在一个类上时表示其中所有的方法的执行都会触发缓存的清除操作。
8、Spring Boot 如何设置支持跨域请求?
现代浏览器出于安全的考虑, HTTP 请求时必须遵守同源策略,否则就是跨域的 HTTP 请求,默认情况下是被禁止的,IP(域名)不同、或者端口不同、协议不同(比如 HTTP、HTTPS)都会造成跨域问题。
一般前端的解决方案有:
- ① 使用 JSONP 来支持跨域的请求,JSONP 实现跨域请求的原理简单的说,就是动态创建
<script>标签,然后利用<script>的 SRC 不受同源策略约束来跨域获取数据。缺点是需要后端配合输出特定的返回信息。 - ② 利用反应代理的机制来解决跨域的问题,前端请求的时候先将请求发送到同源地址的后端,通过后端请求转发来避免跨域的访问。
后来 HTML5 支持了 CORS 协议。CORS 是一个 W3C 标准,全称是”跨域资源共享”(Cross-origin resource sharing),允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而克服了 AJAX 只能同源使用的限制。它通过服务器增加一个特殊的 Header[Access-Control-Allow-Origin]来告诉客户端跨域的限制,如果浏览器支持 CORS、并且判断 Origin 通过的话,就会允许 XMLHttpRequest 发起跨域请求。
前端使用了 CORS 协议,就需要后端设置支持非同源的请求,Spring Boot 设置支持非同源的请求有两种方式。
第一,配置 CorsFilter。
1 | @Configuration |
需要配置上述的一段代码。第二种方式稍微简单一些。
第二,在启动类上添加:
1 | public class Application extends WebMvcConfigurerAdapter { |
9、JPA 和 Hibernate 有哪些区别?JPA 可以支持动态 SQL 吗?
JPA本身是一种规范,它的本质是一种ORM规范(不是ORM框架,因为JPA并未提供ORM实现,只是制定了规范)因为JPA是一种规范,所以,只是提供了一些相关的接口,但是接口并不能直接使用,JPA底层需要某种JPA实现,Hibernate 是 JPA 的一个实现集。
JPA 是根据实体类的注解来创建对应的表和字段,如果需要动态创建表或者字段,需要动态构建对应的实体类,再重新调用Jpa刷新整个Entity。动态SQL,mybatis支持的最好,jpa也可以支持,但是没有Mybatis那么灵活。
10、Spring 、Spring Boot 和 Spring Cloud 的关系?
Spring 最初最核心的两大核心功能 Spring Ioc 和 Spring Aop 成就了 Spring,Spring 在这两大核心的功能上不断的发展,才有了 Spring 事务、Spring Mvc 等一系列伟大的产品,最终成就了 Spring 帝国,到了后期 Spring 几乎可以解决企业开发中的所有问题。
Spring Boot 是在强大的 Spring 帝国生态基础上面发展而来,发明 Spring Boot 不是为了取代 Spring ,是为了让人们更容易的使用 Spring 。
Spring Cloud 是一系列框架的有序集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。
Spring Cloud 是为了解决微服务架构中服务治理而提供的一系列功能的开发框架,并且 Spring Cloud 是完全基于 Spring Boot 而开发,Spring Cloud 利用 Spring Boot 特性整合了开源行业中优秀的组件,整体对外提供了一套在微服务架构中服务治理的解决方案。
用一组不太合理的包含关系来表达它们之间的关系。
Spring ioc/aop > Spring > Spring Boot > Spring Cloud