
数据类型
Object
equals 方法和 hashcode 方法
Object 中的 hashcode 是根据对象的内存地址生成的,equals 使用 ‘==’ 直接比较对象的地址。
改写 equals 时总是要改写 hashcode,使得 equals 结果为 true 时,hashcode 结果也为 true,hashcode 结果为 false,equals 结果也为 false(即 hashcode 是 equals 的必要不充分条件)。因为在集合类(HashMap,HashSet 等)中的比较操作为了提高效率,一般都是先比较 hashcode 值,再比较 equals。可以利用 IDEA 快速生成 equals 和 hashcode 方法。
对象克隆(复制)
假如说你想复制一个简单变量。很简单:
1 | int apples = 5; |
不仅仅是int类型,其它七种原始数据类型(boolean,char,byte,short,float,double.long)同样适用于该类情况。但是如果你复制的是一个对象,情况就有些复杂了。
假设说我是一个beginner,我会这样写:
1 | class Student { |
结果:
学生1:12345
学生2:12345
我们试着改变stu2实例的number字段,再打印结果看看:
1 | stu2.setNumber(54321); |
结果:
学生1:54321
学生2:54321
这就怪了,为什么改变学生2的学号,学生1的学号也发生了变化呢?原因出在(stu2 = stu1) 这一句。该语句的作用是将stu1的引用赋值给stu2,这样,stu1和stu2指向内存堆中同一个对象。如图:

那么,怎样才能达到复制一个对象呢?是否记得万类之王Object。它有11个方法,有两个protected的方法,其中一个为clone方法。
1 | /* |
仔细一看,它还是一个native方法,大家都知道native方法是非Java语言实现的代码,供Java程序调用的,因为Java程序是运行在JVM虚拟机上面的,要想访问到比较底层的与操作系统相关的就没办法了,只能由靠近操作系统的语言来实现。
因为每个类直接或间接的父类都是Object,因此它们都含有clone()方法,但是因为该方法是protected,所以都不能在类外进行访问。要想对一个对象进行复制,就需要对clone方法覆盖。
为什么要克隆?
大家先思考一个问题,为什么需要克隆对象?直接new一个对象不行吗?
答案是:克隆的对象可能包含一些已经修改过的属性,而new出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的“状态”就靠clone方法了。那么我把这个对象的临时属性一个一个的赋值给我新new的对象不也行嘛?可以是可以,但是一来麻烦不说,二来,大家通过上面的源码都发现了clone是一个native方法,就是快啊,在底层实现的。
提个醒,我们常见的Object a=new Object();Object b;b=a;这种形式的代码复制的是引用,即对象在内存中的地址,a和b对象仍然指向了同一个对象。而通过clone方法赋值的对象跟原来的对象时同时独立存在的。
如何实现克隆
先介绍一下两种不同的克隆方法,浅克隆(ShallowClone)和深克隆(DeepClone)。
在Java语言中,数据类型分为值类型(基本数据类型)和引用类型,值类型包括int、double、byte、boolean、char等简单数据类型,引用类型包括类、接口、数组等复杂类型。浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制。
浅克隆
浅克隆的一般步骤是:
- 被复制的类需要实现Clonenable接口(不实现的话在调用clone方法会抛出CloneNotSupportedException异常), 该接口为标记接口(不含任何方法)。
- 覆盖clone()方法,访问修饰符设为public。方法中调用super.clone()方法得到需要的复制对象。
1 | class Student implements Cloneable{ |
结果:
学生1:12345
学生2:12345
学生1:12345
学生2:54321
如果你还不相信这两个对象不是同一个对象,那么你可以看看这一句:
1 | System.out.println(stu1 == stu2); // false |
深克隆
在学生类里再加一个Address类。
1 | class Address { |
结果:
学生1:123,地址:杭州市
学生2:123,地址:杭州市
在main方法中试着改变addr实例的地址。
1 | addr.setAdd("西湖区"); |
结果:
学生1:123,地址:杭州市
学生2:123,地址:杭州市
学生1:123,地址:西湖区
学生2:123,地址:西湖区
这就奇怪了,怎么两个学生的地址都改变了?原因是浅复制只是复制了addr变量的引用,并没有真正的开辟另一块空间,将值复制后再将引用返回给新对象。所以,为了达到真正的复制对象,而不是纯粹引用复制。我们需要将Address类可复制化,并且修改clone方法
1 | class Address implements Cloneable { |
结果:
学生1:123,地址:杭州市
学生2:123,地址:杭州市
学生1:123,地址:西湖区
学生2:123,地址:杭州市
这样结果就符合我们的想法了。
最后我们可以看看API里其中一个实现了clone方法的类:java.util.Date,该类其实也属于深度复制。
1 | /** |
String
比较
1 | String str1 = "abc"; |
split 方法
replace、replaceAll 方法
String,StringBuffer与StringBuilder的区别
String 字符串常量StringBuffer
字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中, String 效率是远要比 StringBuffer 快的:
1 | String S1 = “This is only a” + “ simple” + “ test”; |
你会很惊讶的发现,生成 String S1 对象的速度简直太快了,而这个时候 StringBuffer 居然速度上根本一点都不占优势。其实这是 JVM 的一个把戏,在 JVM 眼里,这个 String S1 = “This is only a” + “ simple” + “test”; 其实就是:String S1 = “This is only a simple test”; 所以当然不需要太多的时间了。但大家这里要注意的是,如果你的字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:
1 | String S2 = “This is only a”; |
这时候 JVM 会规规矩矩的按照原来的方式去做。在大部分情况下 StringBuffer > String
StringBuffer
Java.lang.StringBuffer线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。
可将字符串缓冲区安全地用于多个线程。可以在必要时对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。
StringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。例如,如果 z 引用一个当前内容是“start”的字符串缓冲区对象,则此方法调用 z.append(“le”) 会使字符串缓冲区包含“startle”,而 z.insert(4, “le”) 将更改字符串缓冲区,使之包含“starlet”。
在大部分情况下 StringBuilder > StringBuffer
java.lang.StringBuilde
java.lang.StringBuilder一个可变的字符序列是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的方法基本相同。
Class
- 获取Class对象引用的方式有3种,Object类的getClass方法,Class类的静态方法forName以及字面常量的方式”.class”
- 实例类的getClass方法和Class类的静态方法forName都会触发类的初始化阶段,而字面常量获取Class对象的方式则不会触发初始化。
- 向Class引用添加泛型约束仅仅是为了提供编译期类型的检查从而避免将错误延续到运行时期。
- 在Java中,所有类型转换都是在运行时进行正确性检查的
- 一个类在 JVM 中只会有一个 Class 实例
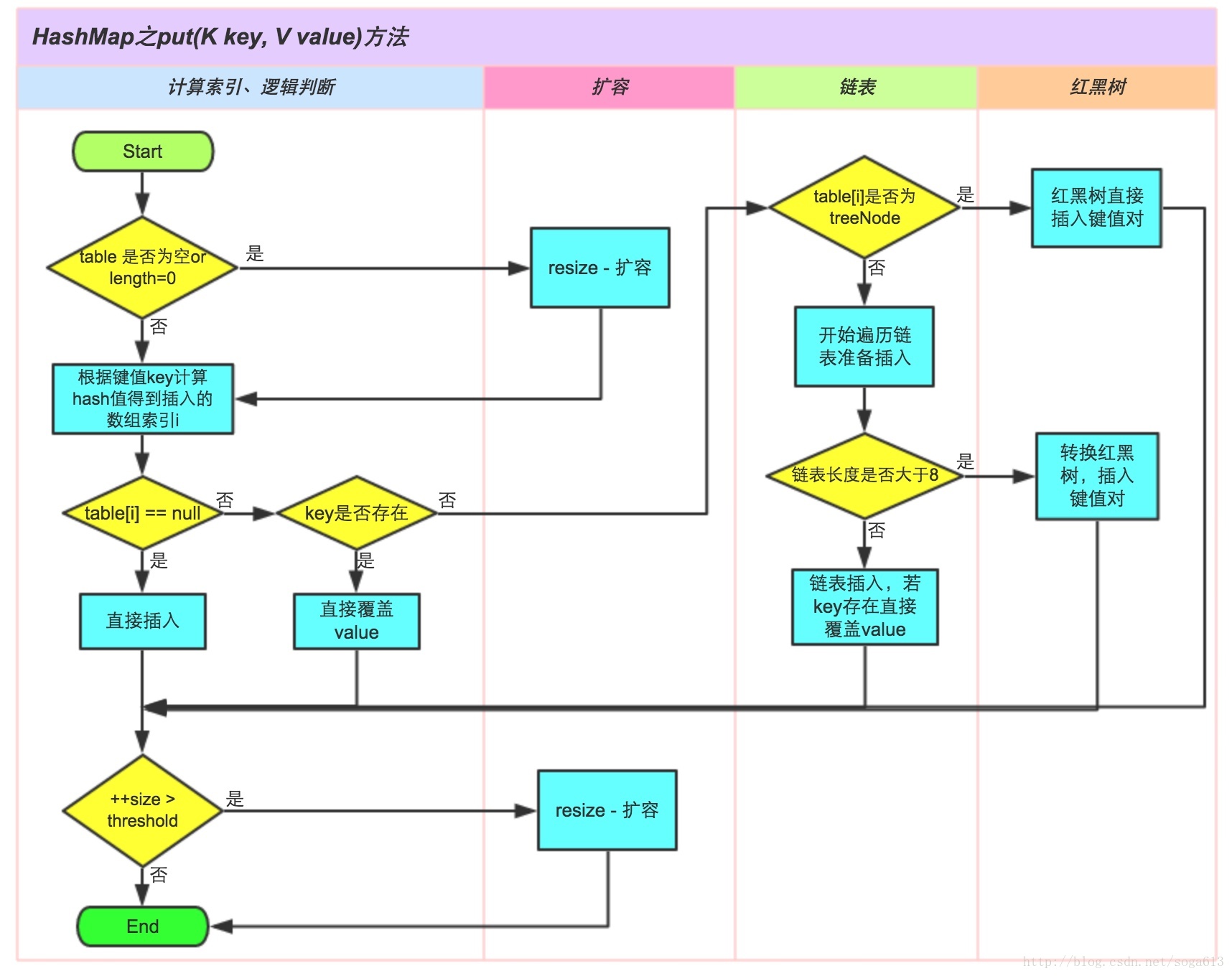
HashMap
实现原理
基于哈希表这种数据结构实现的。哈希冲突(哈希碰撞)的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,HashMap采用了链地址法,也就是数组+链表的方式。
JDK 1.8对HashMap进行了比较大的优化,底层实现由之前的“数组+链表”改为“数组+链表+红黑树”,当链表节点较少时仍然是以链表存在,当链表节点较多时(大于8)会转为红黑树。
源码分析
HashMap的主干是一个Entry(1.8是Node,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode)数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
HashMap有4个构造器,在常规构造器中,没有为数组table分配内存空间(入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组。
JDK 1.8 中 key 的 hash 值取的是
(h = key.hashCode()) ^ (h >>> 16),就是把高16bit和低16bit异或了一下。因为当数组长度较小的时候,hash值参与运算只是低位的值,发生碰撞的可能性比较大。一般情况下,key的分布符合“局部性原理”,低比特位相同的概率大于高低位异或后仍然相同的概率,从而降低了碰撞的概率。【1】计算具体数组位置,使用 key 的 hash 值对数组长度进行取模就可以了。
hash & (length-1);这个方法很简单,简单说就是取 hash 值的低 n 位。如在数组长度为 32 的时候,其实取的就是 key 的 hash 值的低 5 位,作为它在数组中的下标位置。如果key为null的话,hash值为0。当 b = 2^n 时,a % b = a & (b - 1) 例如 a = 18, b = 16 时:
1
2
3
41 0 0 1 0
& 0 1 1 1 1
__________________
0 0 0 1 0 = 2扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
由于是双倍扩容,迁移过程中,会将原来 table[i] 中的链表的所有节点,分拆到新的数组的 newTable[i] 和 newTable[i + oldLength] 位置上。如原来数组长度是 16,那么扩容后,原来 table[0] 处的链表中的所有元素会被分到新数组中 newTable[0] 和 newTable[16] 这两个位置。
通过
Integer.highestOneBit((number - 1) << 1)可以确保capacity为大于或等于 number 的最接近number 的二次幂。Integer.highestOneBit是用来获取最左边的bit(其他bit位为0)所代表的数值。Java7 是先扩容后插入新值的,Java8 先插值再扩容。
HashMap的容量一定保持2的次幂的原因
减少扩容后数据位置的重新hash
在移动元素的时候,不需要重新定位,只需要看原来的hash值新增的那个bit是1还是0就好了,是0的话位置没变,是1的话位置变成“原位置+oldCap”。【2】
使用位运算代替取模运算,即保证了散列的均匀,同时也提升了效率
相对于 put 过程,get 过程是非常简单的。
- 根据 key 计算 hash 值。
- 找到相应的数组下标:hash & (length – 1)。
- 遍历该数组位置处的链表,直到找到相等(==或equals)的 key。
判断元素相等的设计比较经典,利用了bool表达式的短路特性:先比较hash值;如果hash值相等,就通过==比较;如果==不等,再通过equals方法比较。hash是提前计算好的;如果没有重载运算符(通常也不建议这样做),==一般直接比较引用值;equals方法最有可能耗费性能,如String的equals方法需要O(n)的时间,n是字符串长度。一定要记住这里的判断顺序,很能考察对碰撞处理源码的理解。
put 流程:
HashMap 的 key 为什么一般用字符串比较多,能用其他对象,或者自定义的对象吗?为什么?
在使用 String 类型的对象做 key 时我们可以只根据传入的字符串内容就能获得对应存在 map 中的 value 值。
如果你想把自定义的对象作为 key,只需要重写 hashCode() 方法与 equals() 方法即可。
HashMap和Hashtable的区别
父类不同
HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary(已被废弃,详情看源代码)。不过它们都同时实现了map、Cloneable、Serializable这三个接口。
Hashtable比HashMap多提供了elments() 和contains() 两个方法。elments() 方法继承自Hashtable的父类Dictionnary,用于返回此Hashtable中value的枚举。contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。HashMap去掉了contains方法,改成containsValue和containsKey了。null值问题
Hashtable既不支持Null key也不支持Null value。Hashtable的put()方法的注释中有说明 。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
线程安全性
Hashtable是线程安全的,它的每个方法中都加入了Synchronize方法。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步
HashMap不是线程安全的,可以通过
Map map = Collections.synchronizedMap(new HashMap())来达到同步的效果。虽然HashMap不是线程安全的,但是它的效率会比Hashtable要好很多。这样设计是合理的。在我们的日常使用当中,大部分时间是单线程操作的。HashMap把这部分操作解放出来了。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。
遍历方式不同
Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
HashMap的Iterator是fail-fast迭代器。当有其它线程改变了HashMap的结构(增加,删除),将会抛出ConcurrentModificationException。不过,通过Iterator的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
JDK8之前的版本中,Hashtable是没有fast-fail机制的。在JDK8及以后的版本中 ,Hashtable也是使用fast-fail的。(此处可以去看一下1.5和1.8JDK源码的对比)
初始容量不同
Hashtable的初始长度是11,之后每次扩充容量变为之前的2n+1(n为上一次的长度),而HashMap的初始长度为16,之后每次扩充变为原来的两倍。
创建时,如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为2的幂次方大小。
计算哈希值的方法不同
Hashtable直接使用对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数发来获得最终的位置。 然而除法运算是非常耗费时间的。效率很低
HashMap为了提高计算效率,将哈希表的大小固定为了2的幂,这样在取模预算时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。
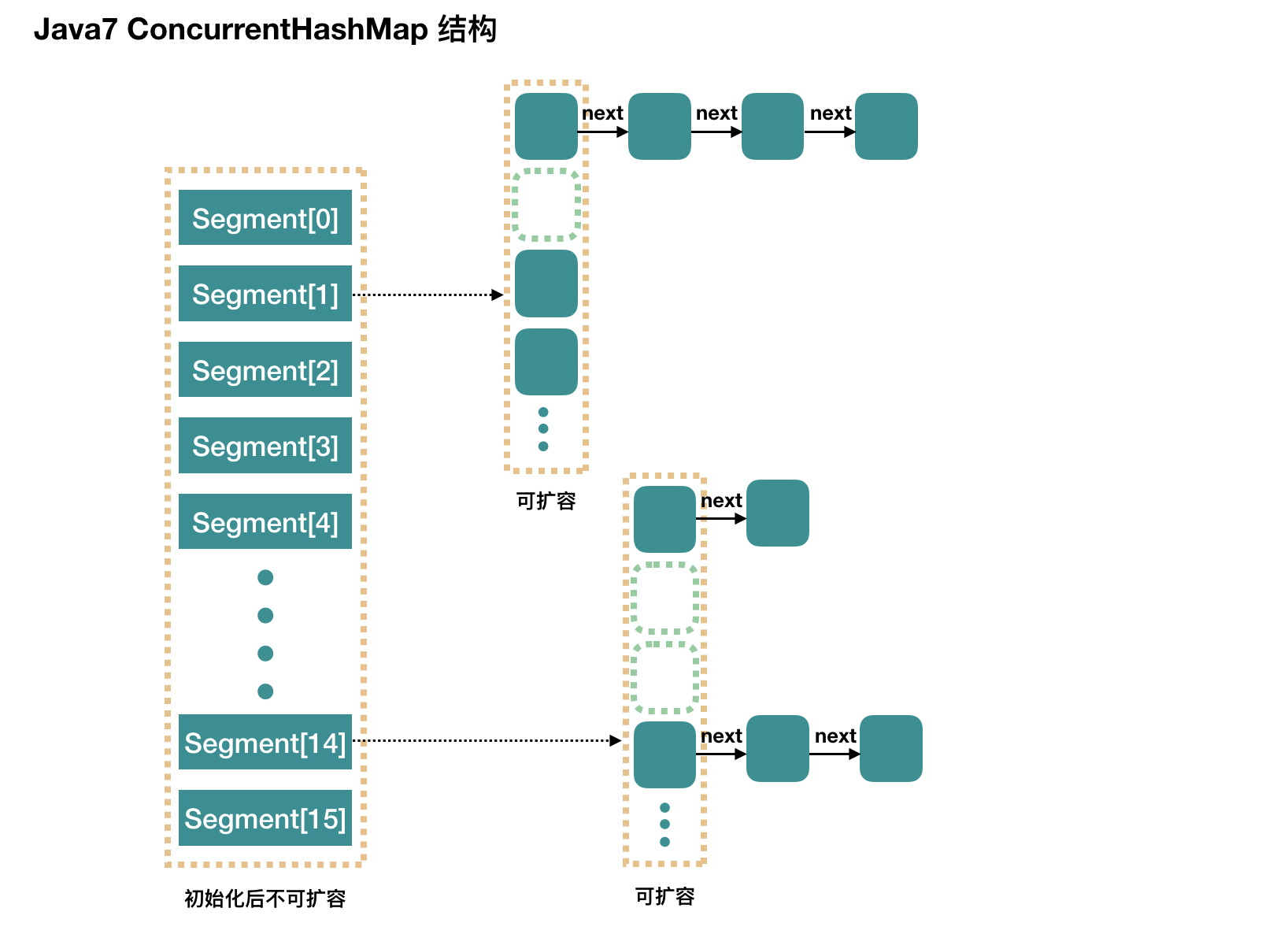
ConcurrentHashMap和Hashtable的区别
ConcurrentHashMap和CopyOnWriteArrayList保留了线程安全的同时,也提供了更高的并发性。
当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。而ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。
简单理解,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
![]()
![]()
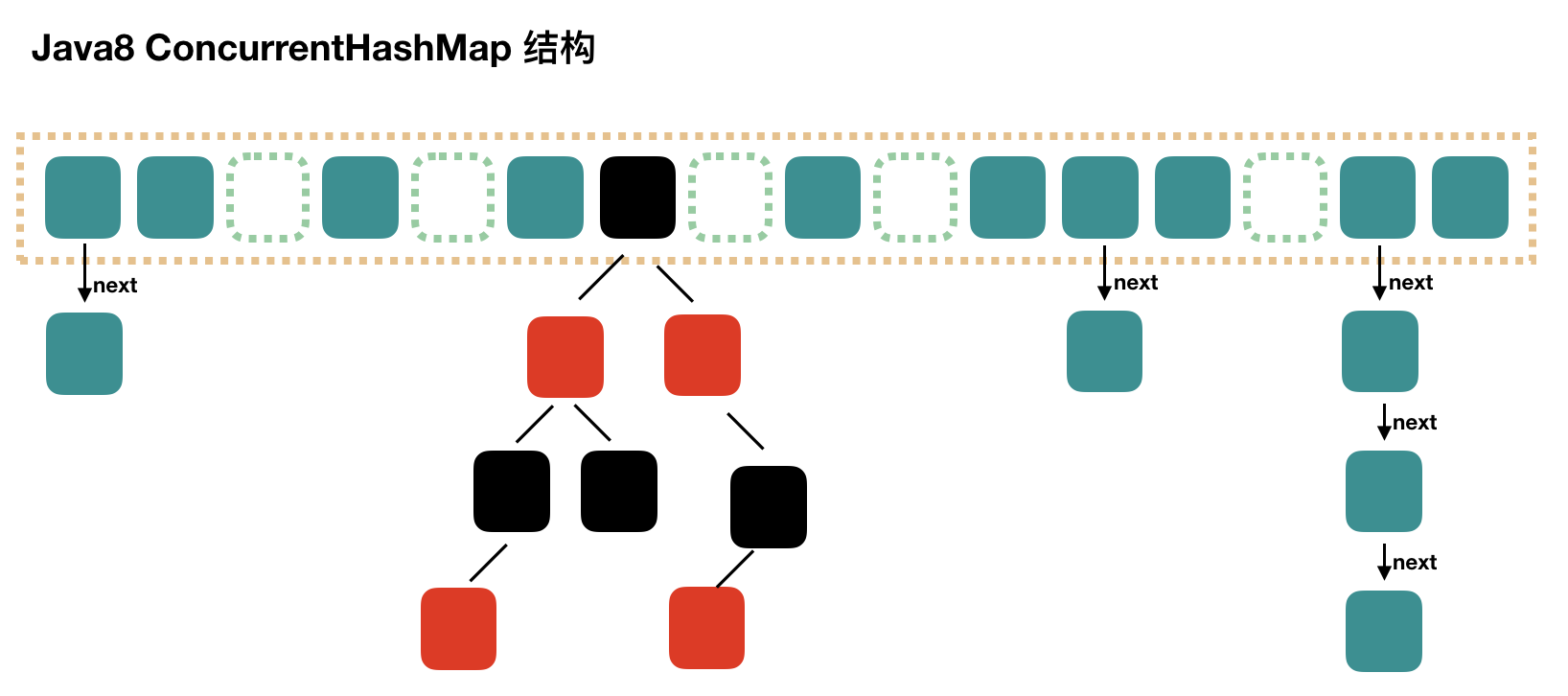
- Hashtable 在 Java 诞生之初时就有了,HashMap 是 JDk1.2 之后有的,而在 JDK1.5 才有ConcurrentHashMap
- HashMap不能保证随着时间的推移Map中的元素次序是不变的
HashSet和HashMap的区别
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值 |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
int 和 Integer 的区别
Integer是int的包装类,int则是java的一种基本数据类型
Integer变量必须实例化后才能使用,而int变量不需要
Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
Integer 的默认值是 null,int 的默认值是 0
由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
1
2
3Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
1
2
3
4
5
6Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false对于第4条的原因:
java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);这就是自动装箱,而java API中对Integer类型的valueOf的定义如下:1
2
3
4
5
6
7public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了,简要的说就是在Integer类中有一个静态内部类IntegerCache,在IntegerCache类中有一个Integer数组,用以缓存当数值范围为-128~127时的Integer对象。
简单来讲:自动装箱就是
Integer.valueOf(int i);自动拆箱就是i.intValue();在java中包装类,比较多的用途是用在于各种数据类型的转化中。
byte
两个byte类型相加,结果是int,也就是需要使用int接收。
JVM
什么是 JVM
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。JVM在执行字节码时,实际上最终还是把字节码解释成具体平台上的机器指令执行。
JVM 体系总体分四大块:
- 类的加载机制
- jvm内存结构
- GC算法 垃圾回收
- GC分析 命令调优

类的加载机制
java程序的执行流程图:
jvm的大致物理结构图:
什么是类的加载
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
类加载器并不需要等到某个类被“首次主动使用”时再加载它,JVM规范允许类加载器在预料某个类将要被使用时就预先加载它,如果在预先加载的过程中遇到了.class文件缺失或存在错误,类加载器必须在程序首次主动使用该类时才报告错误(LinkageError错误)如果这个类一直没有被程序主动使用,那么类加载器就不会报告错误。
加载.class文件的方式:
- 从本地系统中直接加载
- 通过网络下载.class文件
- 从zip,jar等归档文件中加载.class文件
- 从专有数据库中提取.class文件
- 将Java源文件动态编译为.class文件
类的生命周期
一个java类的完整的生命周期会经历加载、连接、初始化、使用、和卸载五个阶段,当然也有在加载或者连接之后没有被初始化就直接被使用的情况。

类的加载过程
类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
Java中的绑定:绑定指的是把一个方法的调用与方法所在的类(方法主体)关联起来,对java来说,绑定分为静态绑定和动态绑定。
静态绑定:即前期绑定。在程序执行前方法已经被绑定,此时由编译器或其它连接程序实现。针对java,简单的可以理解为程序编译期的绑定。java当中的方法只有final,static,private和构造方法是前期绑定的。
动态绑定:即晚期绑定,也叫运行时绑定。在运行时根据具体对象的类型进行绑定。在java中,几乎所有的方法都是后期绑定的。
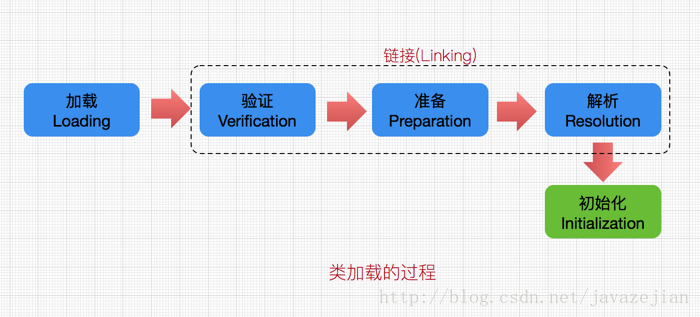
加载
加载是类加载过程的第一个阶段,在加载阶段,虚拟机需要完成以下三件事情:
通过一个类的全限定名来获取其定义的二进制字节流。
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
注意:二进制字节流并不只是单纯地从Class文件中获取,比如它还可以从Jar包中获取、从网络中获取(最典型的应用便是Applet)、由其他文件生成(JSP应用)等。
类加载器
类加载器的任务是根据一个类的全限定名来读取此类的二进制字节流到JVM中,然后转换为一个与目标类对应的java.lang.Class对象实例。类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类的加载阶段。对于任意一个类,都需要由它的类加载器和这个类本身一同确定其在就Java虚拟机中的唯一性,也就是说,即使两个类来源于同一个Class文件,只要加载它们的类加载器不同,那这两个类就必定不相等。这里的“相等”包括了代表类的Class对象的equals()、isAssignableFrom()、isInstance()等方法的返回结果,也包括了使用instanceof关键字对对象所属关系的判定结果。
虚拟机提供了3种类加载器:引导(Bootstrap)类加载器、扩展(Extension)类加载器、系统(System)类加载器(也称应用类加载器)
- 启动类加载器:Bootstrap ClassLoader,跟上面相同。它负责加载存放在JDK\jre\lib(JDK代表JDK的安装目录,下同)下,或被-Xbootclasspath参数指定的路径中的,并且能被虚拟机识别的类库(如rt.jar,所有的java.*开头的类均被Bootstrap ClassLoader加载)。启动类加载器是无法被Java程序直接引用的。
- 扩展类加载器:Extension ClassLoader,该加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载JDK\jre\lib\ext目录中,或者由java.ext.dirs系统变量指定的路径中的所有类库(如javax.*开头的类),开发者可以直接使用扩展类加载器。
- 应用程序类加载器:Application ClassLoader,该类加载器由sun.misc.Launcher$AppClassLoader来实现,它负责加载用户类路径(ClassPath)所指定的类,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
应用程序都是由这三种类加载器互相配合进行加载的,如果有必要,我们还可以加入自定义的类加载器。因为JVM自带的ClassLoader只是懂得从本地文件系统加载标准的java class文件,因此如果编写了自己的ClassLoader,便可以做到如下几点:
1)在执行非置信代码之前,自动验证数字签名。
2)动态地创建符合用户特定需要的定制化构建类。
3)从特定的场所取得java class,例如数据库中和网络中。
事实上当使用Applet的时候,就用到了特定的ClassLoader,因为这时需要从网络上加载java class,并且要检查相关的安全信息,应用服务器也大都使用了自定义的ClassLoader技术。
这几种类加载器的层次关系如下图所示:
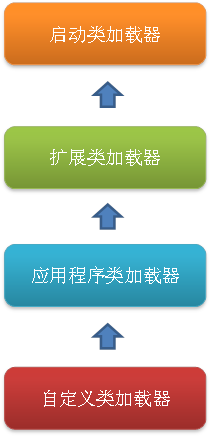
这种层次关系称为类加载器的双亲委派模型。我们把每一层上面的类加载器叫做当前层类加载器的父加载器,当然,它们之间的父子关系并不是通过继承关系来实现的,而是使用组合关系来复用父加载器中的代码。该模型在JDK1.2期间被引入并广泛应用于之后几乎所有的Java程序中,但它并不是一个强制性的约束模型,而是Java设计者们推荐给开发者的一种类的加载器实现方式。
双亲委派模型的工作流程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器在它的搜索范围中没有找到所需的类时,即无法完成该加载,子加载器才会尝试自己去加载该类。
使用双亲委派模型来组织类加载器之间的关系,有一个很明显的好处,就是Java类随着它的类加载器(说白了,就是它所在的目录)一起具备了一种带有优先级的层次关系,这对于保证Java程序的稳定运作很重要。例如,java.lang.Object类存放在JDK\jre\lib下的rt.jar之中,因此无论是哪个类加载器要加载此类,最终都会委派给启动类加载器进行加载,这就保证了Object类在程序中的各种类加载器中都是同一个类。
验证
验证的目的是为了确保Class文件中的字节流包含的信息符合当前虚拟机的要求,不会危害虚拟机自身的安全。
不同的虚拟机对类验证的实现可能会有所不同,但大致都会完成以下四个阶段的验证:文件格式的验证、元数据的验证、字节码验证和符号引用验证。
- 文件格式的验证:验证字节流是否符合Class文件格式的规范,并且能被当前版本的虚拟机处理,该验证的主要目的是保证输入的字节流能正确地解析并存储于方法区之内。经过该阶段的验证后,字节流才会进入内存的方法区中进行存储,后面的三个验证都是基于方法区的存储结构进行的。
- 元数据验证:对类的元数据信息进行语义校验(其实就是对类中的各数据类型进行语法校验),保证不存在不符合Java语法规范的元数据信息。
- 字节码验证:该阶段验证的主要工作是进行数据流和控制流分析,对类的方法体进行校验分析,以保证被校验的类的方法在运行时不会做出危害虚拟机安全的行为。
- 符号引用验证:这是最后一个阶段的验证,它发生在虚拟机将符号引用转化为直接引用的时候(解析阶段中发生该转化),主要是对类自身以外的信息(常量池中的各种符号引用)进行匹配性的校验。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在Java堆中。
这里所设置的初始值通常情况下是数据类型默认的零值(如0、0L、null、false等),而不是被在Java代码中被显式地赋予的值。
假设一个类变量的定义为:
public static int value = 3;那么变量value在准备阶段过后的初始值为0,而不是3,因为这时候尚未开始执行任何Java方法,而把value赋值为3的putstatic指令是在程序编译后,存放于类构造器<clinit>()方法之中的,所以把value赋值为3的动作将在初始化阶段才会执行。下表列出了Java中所有基本数据类型以及reference类型的默认零值:
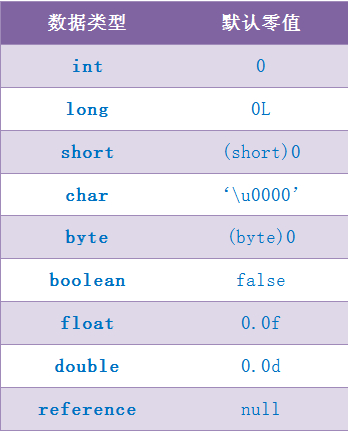
这里还需要注意如下几点:
- 对基本数据类型来说,对于类变量(static)和全局变量,如果不显式地对其赋值而直接使用,则系统会为其赋予默认的零值,而对于局部变量来说,在使用前必须显式地为其赋值,否则编译时不通过。
- 对于同时被static和final修饰的常量,必须在声明的时候就为其显式地赋值,否则编译时不通过;而只被final修饰的常量则既可以在声明时显式地为其赋值,也可以在类初始化时显式地为其赋值,总之,在使用前必须为其显式地赋值,系统不会为其赋予默认零值。
- 对于引用数据类型reference来说,如数组引用、对象引用等,如果没有对其进行显式地赋值而直接使用,系统都会为其赋予默认的零值,即null。
- 如果在数组初始化时没有对数组中的各元素赋值,那么其中的元素将根据对应的数据类型而被赋予默认的零值。
如果类字段的字段属性表中存在ConstantValue属性,即同时被final和static修饰,那么在准备阶段变量value就会被初始化为ConstValue属性所指定的值。
假设上面的类变量value被定义为:
public static final int value = 3;编译时Javac将会为value生成ConstantValue属性,在准备阶段虚拟机就会根据ConstantValue的设置将value赋值为3。
解析
解析阶段是虚拟机将常量池中的符号引用转化为直接引用的过程。
解析阶段可能开始于初始化之前,也可能在初始化之后开始,虚拟机会根据需要来判断,到底是在类被加载器加载时就对常量池中的符号引用进行解析(初始化之前),还是等到一个符号引用将要被使用前才去解析它(初始化之后)。
对同一个符号引用进行多次解析请求时很常见的事情,虚拟机实现可能会对第一次解析的结果进行缓存(在运行时常量池中记录直接引用,并把常量标示为已解析状态),从而避免解析动作重复进行。
解析动作主要针对类或接口、字段、类方法、接口方法四类符号引用进行,分别对应于常量池中的CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info、CONSTANT_InterfaceMethodref_info四种常量类型。
类或接口的解析:判断所要转化成的直接引用是对数组类型,还是普通的对象类型的引用,从而进行不同的解析。
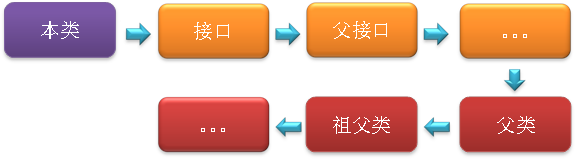
字段解析:对字段进行解析时,会先在本类中查找是否包含有简单名称和字段描述符都与目标相匹配的字段,如果有,则查找结束;如果没有,则会按照继承关系从上往下递归搜索该类所实现的各个接口和它们的父接口,还没有,则按照继承关系从上往下递归搜索其父类,直至查找结束,查找流程如下图所示:
从下面一段代码的执行结果中很容易看出来字段解析的搜索顺序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class Super{
public static int m = 11;
static{
System.out.println("执行了super类静态语句块");
}
}
class Father extends Super{
public static int m = 33;
static{
System.out.println("执行了父类静态语句块");
}
}
class Child extends Father{
static{
System.out.println("执行了子类静态语句块");
}
}
public class StaticTest{
public static void main(String[] args){
System.out.println(Child.m);
}
}执行结果如下:
执行了super类静态语句块
执行了父类静态语句块33
如果注释掉Father类中对m定义的那一行,则输出结果如下:
执行了super类静态语句块
11
分析:static变量发生在静态解析阶段,也即是初始化之前,此时已经将字段的符号引用转化为了内存引用,也便将它与对应的类关联在了一起,由于在子类中没有查找到与m相匹配的字段,那么m便不会与子类关联在一起,因此并不会触发子类的初始化。
注意:理论上是按照上述顺序进行搜索解析,但在实际应用中,虚拟机的编译器实现可能要比上述规范要求的更严格一些。如果有一个同名字段同时出现在该类的接口和父类中,或同时在自己或父类的接口中出现,编译器可能会拒绝编译。如果对上面的代码做些修改,将Super改为接口,并将Child类继承Father类且实现Super接口,那么在编译时会报出如下错误:StaticTest.java:24: 对 m 的引用不明确,Father 中的 变量 m 和 Super 中的 变量 m
都匹配System.out.println(Child.m); ^类方法解析:对类方法的解析与对字段解析的搜索步骤差不多,只是多了判断该方法所处的是类还是接口的步骤,而且对类方法的匹配搜索,是先搜索父类,再搜索接口。
接口方法解析:与类方法解析步骤类似,知识接口不会有父类,因此,只递归向上搜索父接口就行了。
初始化
初始化是类加载过程的最后一步,到了此阶段,才真正开始执行类中定义的Java程序代码。在准备阶段,类变量已经被赋过一次系统要求的初始值,而在初始化阶段,则是根据程序员通过程序指定的主观计划去初始化类变量和其他资源,或者可以从另一个角度来表达:初始化阶段是执行类构造器<clinit>()方法的过程。<clinit>()方法的执行规则:
<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句中可以赋值,但是不能访问。<clinit>()方法与实例构造器<init>()方法(类的构造函数)不同,它不需要显式地调用父类构造器,虚拟机会保证在子类的<clinit>()方法执行之前,父类的<clinit>()方法已经执行完毕。因此,在虚拟机中第一个被执行的<clinit>()方法的类肯定是java.lang.Object。<clinit>()方法对于类或接口来说并不是必须的,如果一个类中没有静态语句块,也没有对类变量的赋值操作,那么编译器可以不为这个类生成<clinit>()方法。- 接口中不能使用静态语句块,但仍然有类变量(final static)初始化的赋值操作,因此接口与类一样会生成
<clinit>()方法。但是接口与类不同的是:执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法,只有当父接口中定义的变量被使用时,父接口才会被初始化。另外,接口的实现类在初始化时也一样不会执行接口的<clinit>()方法。 - 虚拟机会保证一个类的
<clinit>()方法在多线程环境中被正确地加锁和同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的<clinit>()方法,其他线程都需要阻塞等待,直到活动线程执行<clinit>()方法完毕。如果在一个类的<clinit>()方法中有耗时很长的操作,那就可能造成多个线程阻塞,在实际应用中这种阻塞往往是很隐蔽的。
下面给出一个简单的例子,以便更清晰地说明如上规则:
1 | class Father{ |
执行上面的代码,会打印出2,也就是说b的值被赋为了2。
分析:首先在准备阶段为类变量分配内存并设置类变量初始值,这样A和B均被赋值为默认值0,而后再在调用<clinit>() 方法时给他们赋予程序中指定的值。当我们调用Child.b时,触发Child的<clinit>()方法,根据规则2,在此之前,要先执行完其父类Father的<clinit>()方法,又根据规则1,在执行<clinit>()方法时,需要按static语句或static变量赋值操作等在代码中出现的顺序来执行相关的static语句,因此当触发执行Father的<clinit>()方法时,会先将a赋值为1,再执行static语句块中语句,将a赋值为2,而后再执行Child类的<clinit>()方法,这样便会将b的赋值为2.
如果我们颠倒一下Father类中“public static int a = 1;”语句和“static语句块”的顺序,程序执行后,则会打印出1。很明显是根据规则1,执行Father的<clinit>()方法时,根据顺序先执行了static语句块中的内容,后执行了“public static int a = 1;”语句。另外,在颠倒二者的顺序之后,如果在static语句块中对a进行访问(比如将a赋给某个变量),在编译时将会报错,因为根据规则1,它只能对a进行赋值,而不能访问。
总结
整个类加载过程中,除了在加载阶段用户应用程序可以自定义类加载器参与之外,其余所有的动作完全由虚拟机主导和控制。到了初始化才开始执行类中定义的Java程序代码(亦及字节码),但这里的执行代码只是个开端,它仅限于<clinit>()方法。类加载过程中主要是将Class文件(准确地讲,应该是类的二进制字节流)加载到虚拟机内存中,真正执行字节码的操作,在加载完成后才真正开始。
JVM 内存结构
JDK1.7的JVM内存结构

JDK1.8以后的JVM内存结构

以前的方法区(或永久代),用来存放class,Method等元数据信息,但在JDK1.8已经没有了,取而代之的是MetaSpace(元空间),元空间不在虚拟机里面,而是直接使用本地内存。
为什么要用元空间代替永久代?
- 类以及方法的信息比较难确定其大小,因此对于永久代的指定比较困难,太小容易导致永久代溢出,太大容易导致老年代溢出。
- 永久代会给GC带来不需要的复杂度,并且回收效率偏低。
- Oracle可能会将HotSpot和Jrockit合二为一。
在《Java虚拟机规范(Java SE 8)》中描述了JVM运行时内存区域结构如下:
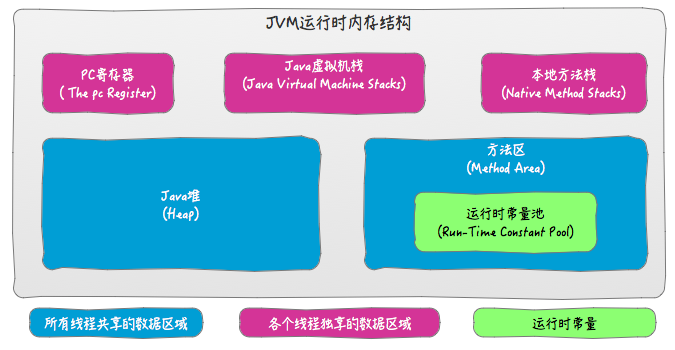
注意:
以上是Java虚拟机规范,不同的虚拟机实现会各有不同,但是一般会遵守规范。
规范中定义的方法区,只是一种概念上的区域,并说明了其应该具有什么功能。但是并没有规定这个区域到底应该处于何处。所以,对于不同的虚拟机实现来说,是由一定的自由度的。
不同版本的方法区所处位置不同,上图中划分的是逻辑区域,并不是绝对意义上的物理区域。因为某些版本的JDK中方法区其实是在堆中实现的。
运行时常量池用于存放编译期生成的各种字面量和符号应用。但是,Java语言并不要求常量只有在编译期才能产生。比如在运行期,String.intern也会把新的常量放入池中。
除了以上介绍的JVM运行时内存外,还有一块内存区域可供使用,那就是直接内存。Java虚拟机规范并没有定义这块内存区域,所以他并不由JVM管理,是利用本地方法库直接在堆外申请的内存区域。
堆和栈的数据划分也不是绝对的,如HotSpot的JIT会针对对象分配做相应的优化。
总结:JVM内存结构,由Java虚拟机规范定义。描述的是Java程序执行过程中,由JVM管理的不同数据区域。各个区域有其特定的功能。
程序计数器(Program Counter Register)
字节码行号指示器,字节码解释器工作时通过改变这个计数值可以选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理和线程恢复等功能都需要依赖这个计数器完成。该内存区域是唯一一个java虚拟机规范没有规定任何OOM (OutOfMemoryError) 情况的区域。
特点
线程私有,因为多线程并发回来后要恢复到当前线程之前执行的位置,所以每个线程都会独立拥有一个 PC
占用空间极小
执行 Java 方法:具体的内容就是指向下一个指令的偏移
执行 Native 方法:计数值为空(undefined)
不会有 OutOfMemoryError
Java 虚拟机栈(Java Stack)
虚拟机栈也就是我们平常所称的栈内存,描述的是Java方法执行的内存模型。每个方法在执行的同时都会创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈和出栈的过程。
在Java虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
设置虚拟机栈的大小:-Xss
例如:-Xss128K
特点:
- 虚拟机栈是线程私有的,它的生命周期与线程相同。
- 以栈帧为单位,进行入栈和出栈
栈帧结构
栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息
局部变量表(Current Variable Table)
局部变量表存放了编译器可知的各种基本数据类型(
boolean、byte、char、short、int、float、long、double)、对象引用(引用指针,并非对象本身),其中64位长度的long和double类型的数据会占用2个局部变量的空间,其余数据类型只占1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量表是完全确定的,在运行期间栈帧不会改变局部变量表的大小空间。操作数栈(Operand Stack)
操作数栈的作用主要用来存储运算结果以及运算的操作数,它不同于局部变量表通过索引来访问,而是压栈和出栈的方式
动态链接(Dynamic Linking)
指向运行时常量池中栈帧所属方法的引用。用来支持方法调用中的动态连接。
常量池的方法的符号引用,一部分在类加载的时候转化为直接引用,被称为静态解析。而动态连接指的是在每一次运行期间转化为直接引用。
返回地址(Return Address)
正常返回时,PC计数器的值作为返回地址保存。异常返回时,通过异常处理表获得返回地址,栈帧一般不会保存这部分信息。
本地方法栈(Native Method Stack)
本地方法栈和虚拟机栈类似,只不过本地方法栈为Native方法服务。线程私有。需要注意的是,由于虚拟机规范对于本地方法栈的具体实现没有做强制要求,所以Sun HotSpot直接把本地方法栈和虚拟机栈合二为一。
Java 堆(Heap)
对于大多数应用来说,Java堆(Java Heap)是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例及数组,几乎所有的对象实例都在这里分配内存。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机,比如 HotSpot 都是按照可扩展来实现的(通过-Xmx和-Xms控制)。
如果在堆中没有内存来完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
特点:
- 线程共享
- 内存最大的一块
- 目的:存放对象实例 和 数组,但随着 JIT 的发展和逃逸分析技术成熟,栈上分配、标量替换,对象实例开始不一定分配在堆上
因为堆是 GC 回收的主要区域,根据 GC 的实现机制,会对堆进行分代:
新生代进行 minor GC,老生代进行 major GC(深度GC)。大部分GC发生在新生代中。
- 新生代(Young Generation)
Eden 新生的对象
Survivor Space 每次GC后还存活的对象,可再细分为 From Survivor 和 To Survivor - 老年代(Old Generation)
Tenured,存放生命周期长的对象
堆内存分配由 -Xmn 来指定。例如:-Xms20m -Xmx20m
- -Xms,初始使用,默认物理内存 1/64
- -Xmx,最大内存,默认物理内存 1/4
虚拟机会根据堆的空闲情况动态调整推大小,空余大于 70%,会减少到 -Xms,空余小于 40%,会增大到 -Xmx
所以服务器如果配置 -Xms = -Xmx,则可以避免堆自动扩展
方法区(Method Area)
方法区与堆一样,是各个线程共享的内存区域。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。用于存储已经被虚拟机加载的类信息(如类名、修饰符、字段和方法等)、常量、静态变量、即时编译器编译后的代码等数据。
在Hotspot虚拟机中,这块区域对应持久代(Permanent Generation),一般来说,方法区上执行GC的情况很少,是方法区被称为持久代的原因之一,但这并不代表方法区上完全没有GC,其上的GC主要针对常量池的回收和已加载类的卸载。在方法区上进行GC,条件相当苛刻而且困难。对于其他虚拟机(J9)等,是没有永久代这个概念的。
运行时常量池(Runtime Constant Pool)是方法区的一部分,用于存储编译器生成的常量和引用。一般来说,常量的分配在编译时就能确定,但也不全是,也可以存储在运行时期产生的常量。比如String类的 intern() 方法,String类维护了一个常量池,如果调用的字符”hello”已经在常量池中,则直接返回常量池中的地址,否则新建一个常量加入池中,并返回地址。
根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
特点:
- 线程共享
- 又称为 Non-Heap,用来和堆进行区分
- HotSpot 虚拟机把 GC 分代收集扩展至方法区,所以在 HotSpot 可以称它为永久代(Permanent Generation)
存储被虚拟机加载的内容有:
- 类信息
- 常量
- 静态变量
- 即时编译器编译后的代码
方法区包含运行时常量池,Class 文件的各种字面量和符号引用,在类加载后会存入到运行时常量池中。直接引用也会存储在运行时常量池。除了类加载阶段,运行时也可以动态加入,比如 String 的 intern() 方法
方法区的大小的分配
- -XX:MaxPermSize 最大值,默认最大值为64MB
- -XX:PermSize 最小值,默认最小值为16MB
例如:-XX:MaxPermSize=10M -XX:PermSize=10M
直接内存
直接内存并不是虚拟机运行时数据区的一部分。jdk1.4中新加入的NIO,引入了一种基于通道和缓冲区的I/O方式,它可以使用native函数直接分配堆外内存,然后通过一个存储在java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。这个堆外内存就是本机内存,不会影响到堆内存的大小。
通过 -XX:MaxDirectMemorySize 设置最大值,默认与java堆最大值一样。
例如:-XX:MaxDirectMemorySize=10M -Xmx20M
对象分配规则
- 对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC。
- 大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
- 长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor区,之后每经过一次Minor GC那么对象的年龄加1,知道达到阀值对象进入老年代。
- 动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
- 空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年代的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC。
在垃圾收集过程中,可能会将对象移动到不同区域:
- 伊甸园(Eden):这是对象最初诞生的区域,并且对大多数对象来说,这里是它们唯一存在过的区域。
- 幸存者乐园(Survivor):从伊甸园幸存下来的对象会被挪到这里。
- 终身颐养园(Tenured):这是足够老的幸存对象的归宿。年轻代收集(Minor-GC)过程是不会触及这个地方的。当年轻代收集不能把对象放进终身颐养园时,就会触发一次完全收集(Major-GC),这里可能还会牵扯到压缩,以便为大对象腾出足够的空间。
垃圾回收器 GC(Garbage Collection)
GC的两个职能:1.检测垃圾、2.回收垃圾。
检测垃圾
引用计数算法(Reference Counting)
原理:给每个对象添加一引用计数器,每当有一个地方引用它,计数器+1 ,引用失效时就-1 。
分析:引用计数算法很简单高效。但是,现在主流的虚拟机没有选用引用计数算法来管理内存,原因是它很难解决对象之间循环引用的问题。
可达性分析算法(Rearchability Analysis)
原理:以根集(GC Roots)对象为起始点进行搜索,如果有对象不可达的话,即是垃圾对象。
Java中可以被作为GC Roots中的对象有:
- 虚拟机栈中的引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中的常量池中引用的对象。
- 本地方法栈(JNI: Java Native Interface)即一般说的Native的引用对象。
可达状态:在一个对象创建后,有一个以上的引用变量引用它,那它就处于可达状态。
可恢复状态:对象不再有任何的引用变量引用它,它将先进入可恢复状态,系统会调用finalize()方法进行资源整理,发现有一个以上引用变量引用该对象,则这个对象又再次变为可达状态,否则会变成不可达状态。不可达状态:当对象的所有引用都被切断,且系统调用 finalize() 方法进行资源整理后该对象依旧没变为可达状态,则这个对象将永久性失去引用并且变成不可达状态,系统才会真正的去回收该对象所占用的资源。
对象的四种引用状态
强引用 :创建一个对象并把这个对象直接赋给一个变量,不管系统资源多么紧张,强引用的对象都不会被回收,即使他以后不会再用到。
软引用 :通过SoftReference修饰的类,内存非常紧张的时候会被回收,其他时候不会被回收,在使用之前要判断是否为null从而判断他是否已经被回收了。
弱引用 :通过WeakReference修饰的类,不管内存是否足够,系统垃圾回收时必定会回收。
虚引用 :不能单独使用,主要是用于追踪对象被垃圾回收的状态。通过PhantomReference修饰和引用队列ReferenceQueue类联合使用实现。
回收垃圾
串行回收和并行回收:串行回收是不管系统有多少个CPU,始终只用一个CPU来执行垃圾回收操作;并行回收就是把整个回收工作拆分成多个部分,每个部分由一个CPU负责,从而让多个CPU并行回收。并行回收的执行效率很高,但更复杂,内存会增加。
程序停止和并发执行 :顾名思义是在执行垃圾回收的同时会导致应用程序的暂停。并发执行垃圾回收虽不会导致应用程序的暂停,但需要解决和应用程序的执行冲突,因此系统开销比较高,执行时需要更多的堆内存。
标记-清除(标记-不压缩)
标记-清除要遍历两次。第一次先从根集开始访问所有可达对象,并将他们标记为可达状态。第二次遍历整个内存区域,对不可达状态的对象进行回收处理。这种回收方式不压缩,不需要额外内存,但要两次遍历,会产生碎片。
标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。在标记阶段首先通过根节点,标记所有从根节点开始的对象,未被标记的对象就是未被引用的垃圾对象。然后,在清除阶段,清除所有未被标记的对象。标记清除算法带来的一个问题是会存在大量的空间碎片,因为回收后的空间是不连续的,这样给大对象分配内存的时候可能会提前触发 full gc。
复制算法
将现有的内存空间分为两快,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。遍历空间成本小效率高,但复制的空间成本大。典型的拿“空间”换“时间”。
现在的商业虚拟机都采用这种收集算法来回收新生代,IBM研究表明新生代中的对象98%是朝夕生死的,所以并不需要按照1:1的比例划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中的一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地拷贝到另外一个Survivor空间上,最后清理掉Eden和刚才用过的Survivor的空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1(可以通过-SurvivorRattio来配置),也就是每次新生代中可用内存空间为整个新生代容量的90%,只有10%的内存会被“浪费”。当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保。
标记整理(标记-压缩)
复制算法的高效性是建立在存活对象少、垃圾对象多的前提下的。这种情况在新生代经常发生,但是在老年代更常见的情况是大部分对象都是存活对象。如果依然使用复制算法,由于存活的对象较多,复制的成本也将很高。
标记-压缩算法是一种老年代的回收算法,它在标记-清除算法的基础上做了一些优化。首先也需要从根节点开始对所有可达对象做一次标记,但之后,它并不简单地清理未标记的对象,而是将所有的存活对象压缩到内存的一端。之后,清理边界外所有的空间。这种方法既避免了碎片的产生,又不需要两块相同的内存空间,因此,其性价比比较高。增量算法
增量算法的基本思想是,如果一次性将所有的垃圾进行处理,需要造成系统长时间的停顿,那么就可以让垃圾收集线程和应用程序线程交替执行。每次,垃圾收集线程只收集一小片区域的内存空间,接着切换到应用程序线程。依次反复,直到垃圾收集完成。使用这种方式,由于在垃圾回收过程中,间断性地还执行了应用程序代码,所以能减少系统的停顿时间。但是,因为线程切换和上下文转换的消耗,会使得垃圾回收的总体成本上升,造成系统吞吐量的下降。
堆内存的分代回收
Java垃圾回收机制的最基本的做法就是分代回收。内存中的区域被划分成不同的世代,对象根据其存活的时间被保存在对应世代的区域中。一般的实现是划分成三个年代:年轻、年老、永久。内存的分配是发生在年轻世代中的。当一个对象存活的时间够久的时候,它就会慢慢变老(被复制到老年代中)。对于不同世代可以使用不同的垃圾回收算法。进行世代划分的出发点是对应用中对象存活时间进行研究之后得出的统计规律。一般来说,一个应用中的大部分对象的存活时间都很短。比如局部变量的存活时间就只在方法的执行过程中。因为年轻世代的对象很快会进入不可达状态,因此要求回收频率高且回收速度快,基于这一点,对于年轻世代的垃圾回收算法就可以很有针对性。
1、年轻代
采用复制式回收算法,划分两个区域,分别是E 区和 S 区。大多数对象先分配到Eden区,内存大的对象会直接被分配到老年代中。S 区又分Form、To两个小区,一个用来保存对象,另一个是空的;每次进行年轻代垃圾回收的时候,就把E大区和From小区中的可达对象都复制到To区域中,一些生存时间长的就直接复制到了老年代。最后,清理回收E大区和From小区的内存空间,原来的To空间变为From空间,原来的From空间变为To空间。
2、老年代
回收机制 :采用标记压缩算法回收。
对象来源 :对象大直接进入老年代、Young代中生存时间长的可达对象。
回收频率 :因为很少对象会死掉,所以执行频率不高,而且需要较长时间来完成。
3、永久代
用 途 :用来装载Class,方法等信息,默认为64M(Android的运行时应用分配的内存),不会被回收。
对象来源 :像Hibernate,Spring这类喜欢AOP动态生成类的框架,往往会生成大量的动态代理类,因此我们经常遇到java.lang.OutOfMemoryError:PermGen space的错误,这就是Permanent代内存耗尽所导致的错误。
回收频率 :不会被回收。
GC垃圾回收器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。Java虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商、版本的虚拟机所提供的垃圾收集器都可能会有很大差别,并且一般都会提供参数供用户根据自己的应用特点和要求组合出各个年代所使用的收集器。接下来讨论的收集器基于JDK1.7 Update 14 之后的HotSpot虚拟机(在此版本中正式提供了商用的G1收集器,之前G1仍处于实验状态),该虚拟机包含的所有收集器如下图所示:

上图展示了7种作用于不同分代的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。虚拟机所处的区域,则表示它是属于新生代收集器还是老年代收集器。Hotspot实现了如此多的收集器,正是因为目前并无完美的收集器出现,只是选择对具体应用最适合的收集器。
相关概念
并行和并发
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行。而垃圾收集程序运行在另一个CPU上。
吞吐量(Throughput)
吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
假设虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
Minor GC 和 Full GC
- 新生代GC(Minor GC):指发生在新生代的垃圾收集动作,因为Java对象大多都具备朝生夕灭的特性,所以Minor GC非常频繁,一般回收速度也比较快。
- 老年代GC(Major GC / Full GC):指发生在老年代的GC,出现了Major GC,经常会伴随至少一次的Minor GC(但非绝对的,在Parallel Scavenge收集器的收集策略里就有直接进行Major GC的策略选择过程)。Major GC的速度一般会比Minor GC慢10倍以上。
新生代收集器
Serial收集器
Serial(串行)收集器是最基本、发展历史最悠久的收集器,它是采用复制算法的新生代收集器,曾经(JDK 1.3.1之前)是虚拟机新生代收集的唯一选择。它是一个单线程收集器,只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集时,必须暂停其他所有的工作线程,直至Serial收集器收集结束为止(“Stop The World”)。这项工作是由虚拟机在后台自动发起和自动完成的,在用户不可见的情况下把用户正常工作的线程全部停掉,这对很多应用来说是难以接收的。
下图展示了Serial 收集器(老年代采用Serial Old收集器)的运行过程:

为了消除或减少工作线程因内存回收而导致的停顿,HotSpot虚拟机开发团队在JDK 1.3之后的Java发展历程中研发出了各种其他的优秀收集器。但是这些收集器的诞生并不意味着Serial收集器已经“老而无用”,实际上到现在为止,它依然是HotSpot虚拟机运行在Client模式下的默认的新生代收集器。它也有着优于其他收集器的地方:简单而高效(与其他收集器的单线程相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得更高的单线程收集效率。
在用户的桌面应用场景中,分配给虚拟机管理的内存一般不会很大,收集几十兆甚至一两百兆的新生代(仅仅是新生代使用的内存,桌面应用基本不会再大了),停顿时间完全可以控制在几十毫秒最多一百毫秒以内,只要不频繁发生,这点停顿时间可以接收。所以,Serial收集器对于运行在Client模式下的虚拟机来说是一个很好的选择。
ParNew 收集器
ParNew收集器就是Serial收集器的多线程版本,它也是一个新生代收集器。除了使用多线程进行垃圾收集外,其余行为包括Serial收集器可用的所有控制参数、收集算法(复制算法)、Stop The World、对象分配规则、回收策略等与Serial收集器完全相同,两者共用了相当多的代码。
ParNew收集器的工作过程如下图(老年代采用Serial Old收集器):

ParNew收集器除了使用多线程收集外,其他与Serial收集器相比并无太多创新之处,但它却是许多运行在Server模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关的重要原因是,除了Serial收集器外,目前只有它能和CMS收集器(Concurrent Mark Sweep)配合工作,CMS收集器是JDK 1.5推出的一个具有划时代意义的收集器。
ParNew 收集器在单CPU的环境中绝对不会有比Serial收集器有更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个CPU的环境中都不能百分之百地保证可以超越。在多CPU环境下,随着CPU的数量增加,它对于GC时系统资源的有效利用是很有好处的。它默认开启的收集线程数与CPU的数量相同,在CPU非常多的情况下可使用-XX:ParallerGCThreads参数设置。
Parallel Scavenge 收集器
Parallel Scavenge收集器也是一个并行的多线程新生代收集器,它也使用复制算法。Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标是达到一个可控制的吞吐量(Throughput)。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。而高吞吐量则可以高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
Parallel Scavenge收集器除了会显而易见地提供可以精确控制吞吐量的参数,还提供了一个参数-XX:+UseAdaptiveSizePolicy,这是一个开关参数,打开参数后,就不需要手工指定新生代的大小(-Xmn)、Eden和Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种方式称为GC自适应的调节策略(GC Ergonomics)。自适应调节策略也是Parallel Scavenge收集器与ParNew收集器的一个重要区别。
另外值得注意的一点是,Parallel Scavenge收集器无法与CMS收集器配合使用,所以在JDK 1.6推出Parallel Old之前,如果新生代选择Parallel Scavenge收集器,老年代只有Serial Old收集器能与之配合使用。
老年代收集器
Serial Old收集器
Serial Old 是 Serial收集器的老年代版本,它同样是一个单线程收集器,使用“标记-整理”(Mark-Compact)算法。
此收集器的主要意义也是在于给Client模式下的虚拟机使用。如果在Server模式下,它还有两大用途:
- 在JDK1.5 以及之前版本(Parallel Old诞生以前)中与Parallel Scavenge收集器搭配使用。
- 作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用。
它的工作流程与Serial收集器相同,这里再次给出Serial/Serial Old配合使用的工作流程图:
Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。前面已经提到过,这个收集器是在JDK 1.6中才开始提供的,在此之前,如果新生代选择了Parallel Scavenge收集器,老年代除了Serial Old以外别无选择,所以在Parallel Old诞生以后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器。Parallel Old收集器的工作流程与Parallel Scavenge相同,这里给出Parallel Scavenge/Parallel Old收集器配合使用的流程图:

CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于“标记-清除”算法实现的。
CMS收集器工作的整个流程分为以下4个步骤:
- 初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”。
- 并发标记(CMS concurrent mark):进行GC Roots Tracing的过程,在整个过程中耗时最长。
- 重新标记(CMS remark):为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。此阶段也需要“Stop The World”。
- 并发清除(CMS concurrent sweep)
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。通过下图可以比较清楚地看到CMS收集器的运作步骤中并发和需要停顿的时间:

优点
CMS是一款优秀的收集器,它的主要优点在名字上已经体现出来了:并发收集、低停顿,因此CMS收集器也被称为并发低停顿收集器(Concurrent Low Pause Collector)。
缺点
- 对CPU资源非常敏感 其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。CMS默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。但是当CPU不足4个时(比如2个),CMS对用户程序的影响就可能变得很大,如果本来CPU负载就比较大,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了50%,其实也让人无法接受。
- 无法处理浮动垃圾(Floating Garbage) 可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生。这一部分垃圾出现在标记过程之后,CMS无法再当次收集中处理掉它们,只好留待下一次GC时再清理掉。这一部分垃圾就被称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
- 标记-清除算法导致的空间碎片 CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象。
G1收集器
G1(Garbage-First)收集器是当今收集器技术发展最前沿的成果之一,它是一款面向服务端应用的垃圾收集器,HotSpot开发团队赋予它的使命是(在比较长期的)未来可以替换掉JDK 1.5中发布的CMS收集器。与其他GC收集器相比,G1具备如下特点:
- 并行与并发 G1 能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短“Stop The World”停顿时间,部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让Java程序继续执行。
- 分代收集 与其他收集器一样,分代概念在G1中依然得以保留。虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但它能够采用不同方式去处理新创建的对象和已存活一段时间、熬过多次GC的旧对象来获取更好的收集效果。
- 空间整合 G1从整体来看是基于“标记-整理”算法实现的收集器,从局部(两个Region之间)上来看是基于“复制”算法实现的。这意味着G1运行期间不会产生内存空间碎片,收集后能提供规整的可用内存。此特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次GC。
- 可预测的停顿 这是G1相对CMS的一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了降低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在GC上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
横跨整个堆内存
在G1之前的其他收集器进行收集的范围都是整个新生代或者老生代,而G1不再是这样。G1在使用时,Java堆的内存布局与其他收集器有很大区别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,而都是一部分Region(不需要连续)的集合。
建立可预测的时间模型
G1收集器之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region(这也就是Garbage-First名称的来由)。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了G1收集器在有限的时间内可以获取尽可能高的收集效率。
避免全堆扫描——Remembered Set
G1把Java堆分为多个Region,就是“化整为零”。但是Region不可能是孤立的,一个对象分配在某个Region中,可以与整个Java堆任意的对象发生引用关系。在做可达性分析确定对象是否存活的时候,需要扫描整个Java堆才能保证准确性,这显然是对GC效率的极大伤害。
为了避免全堆扫描的发生,虚拟机为G1中每个Region维护了一个与之对应的Remembered Set。虚拟机发现程序在对Reference类型的数据进行写操作时,会产生一个Write Barrier暂时中断写操作,检查Reference引用的对象是否处于不同的Region之中(在分代的例子中就是检查是否老年代中的对象引用了新生代中的对象),如果是,便通过CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set之中。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set即可保证不对全堆扫描也不会有遗漏。
如果不计算维护Remembered Set的操作,G1收集器的运作大致可划分为以下几个步骤:
- 初始标记(Initial Marking) 仅仅只是标记一下GC Roots 能直接关联到的对象,并且修改TAMS(Nest Top Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可以的Region中创建对象,此阶段需要停顿线程,但耗时很短。
- 并发标记(Concurrent Marking) 从GC Root 开始对堆中对象进行可达性分析,找到存活对象,此阶段耗时较长,但可与用户程序并发执行。
- 最终标记(Final Marking) 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但是可并行执行。
- 筛选回收(Live Data Counting and Evacuation) 首先对各个Region中的回收价值和成本进行排序,根据用户所期望的GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
通过下图可以比较清楚地看到G1收集器的运作步骤中并发和需要停顿的阶段(Safepoint处):

总结
| 收集器 | 串行、并行or并发 | 新生代/老年代 | 算法 | 目标 | 适用场景 |
|---|---|---|---|---|---|
| Serial | 串行 | 新生代 | 复制算法 | 响应速度优先 | 单CPU环境下的Client模式 |
| Serial Old | 串行 | 老年代 | 标记-整理 | 响应速度优先 | 单CPU环境下的Client模式、CMS的后备预案 |
| ParNew | 并行 | 新生代 | 复制算法 | 响应速度优先 | 多CPU环境时在Server模式下与CMS配合 |
| Parallel Scavenge | 并行 | 新生代 | 复制算法 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| Parallel Old | 并行 | 老年代 | 标记-整理 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| CMS | 并发 | 老年代 | 标记-清除 | 响应速度优先 | 集中在互联网站或B/S系统服务端上的Java应用 |
| G1 | 并发 | both | 标记-整理+复制算法 | 响应速度优先 | 面向服务端应用,将来替换CMS |
调优命令
Sun JDK监控和故障处理命令有jps jstat jmap jhat jstack jinfo
- jps:JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
- jstat:JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
- jmap:JVM Memory Map命令用于生成heap dump文件
- jhat:JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看
- jstack:用于生成java虚拟机当前时刻的线程快照。
- jinfo:JVM Configuration info 这个命令作用是实时查看和调整虚拟机运行参数。
调优工具
常用调优工具分为两类,jdk自带监控工具:jconsole和jvisualvm,第三方有:MAT(Memory Analyzer Tool)、GChisto。
- jconsole:Java Monitoring and Management Console是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存,线程和类等的监控
- jvisualvm:jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化等。
- MAT:Memory Analyzer Tool,一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗
- GChisto:一款专业分析gc日志的工具
面试常见问题
类的实例化顺序
1.首先是父类的静态变量和静态代码块(看两者的书写顺序);
2.第二执行子类的静态变量和静态代码块(看两者的书写顺序);
3.第三执行父类的成员变量赋值
4.第四执行父类类的构造代码块
5.第五执行父类的构造方法
6.执行子类的构造代码块
7.第七执行子类的构造方法
总结,也就是说虽然客户端代码是new 的构造方法,但是构造方法确实是在整个实例创建中的最后一个调用。切记切记!
先是父类,再是子类;
先是类静态变量和静态代码块,再是对象的成员变量和构造代码块,最后才是构造方法。JVM内存结构、Java内存模型、Java对象模型的区别
JVM内存结构,和Java虚拟机的运行时区域有关。
Java内存模型,和Java的并发编程有关。
Java对象模型,和Java对象在虚拟机中的表现形式有关。
如和判断一个对象是否存活?(或者GC对象的判定方法)
判断一个对象是否存活有两种方法: 引用计数法和可达性算法(引用链法)
虽然这些算法可以判定一个对象是否能被回收,但是当满足上述条件时,一个对象比不一定会被回收。当一个对象不可达GC Root时,这个对象并不会立马被回收,而是出于一个死缓的阶段,若要被真正的回收需要经历两次标记, 如果对象在可达性分析中没有与GC Root的引用链,那么此时就会被第一次标记并且进行一次筛选,筛选的条件是是否有必要执行finalize()方法。当对象没有覆盖finalize()方法或者已被虚拟机调用过,那么就认为是没必要的。 如果该对象有必要执行finalize()方法,那么这个对象将会放在一个称为F-Queue的对队列中,虚拟机会触发一个Finalize()线程去执行,此线程是低优先级的,并且虚拟机不会承诺一直等待它运行完,这是因为如果finalize()执行缓慢或者发生了死锁,那么就会造成F-Queue队列一直等待,造成了内存回收系统的崩溃。GC对处于F-Queue中的对象进行第二次被标记,这时,该对象将被移除”即将回收”集合,等待回收。
简述java垃圾回收机制
在java中,程序员是不需要显示的去释放一个对象的内存的,而是由虚拟机自行执行。在JVM中,有一个垃圾回收线程,它是低优先级的,在正常情况下是不会执行的,只有在虚拟机空闲或者当前堆内存不足时,才会触发执行,扫描那些没有被任何引用的对象,并将它们添加到要回收的集合中,进行回收。
符号引用和直接引用的区别和关联
符号引用(Symbolic References)以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义的定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件中。
直接引用(Direct References)可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是和虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在内存中存在。
类加载器双亲委派模型机制
当一个类收到了类加载请求时,不会自己先去加载这个类,而是将其委派给父类,由父类去加载,如果此时父类不能加载,反馈给子类,由子类去完成类的加载。
什么是类加载器,类加载器有哪些?
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。
主要有以下四种类加载器:- 启动类加载器(Bootstrap ClassLoader):用来加载java核心类库,无法被java程序直接引用。
- 扩展类加载器(extensions class loader):用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
- 系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过 ClassLoader.getSystemClassLoader()来获取它。
- 用户自定义类加载器,通过继承 java.lang.ClassLoader类的方式实现。
Minor GC ,Full GC 触发条件
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
调用System.gc时,系统建议执行Full GC,但是不必然执行
老年代空间不足
方法去空间不足
通过Minor GC后进入老年代的平均大小大于老年代的可用内存
由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
JVM 出现 fullGC 很频繁,怎么去线上排查问题
问题
前段时间发现线上的一个dubbo服务Full GC比较频繁,大约每两天就会执行一次Full GC。
Full GC的原因
我们知道Full GC的触发条件大致情况有以下几种情况:程序执行了System.gc() //建议jvm执行fullgc,并不一定会执行
执行了jmap -histo:live pid命令 //这个会立即触发fullgc
在执行minor gc的时候进行的一系列检查
执行Minor GC的时候,JVM会检查老年代中最大连续可用空间是否大于了当前新生代所有对象的总大小。如果大于,则直接执行Minor GC(这个时候执行是没有风险的)。如果小于了,JVM会检查是否开启了空间分配担保机制,如果没有开启则直接改为执行Full GC。如果开启了,则JVM会检查老年代中最大连续可用空间是否大于了历次晋升到老年代中的平均大小,如果小于则执行改为执行Full GC。如果大于则会执行Minor GC,如果Minor GC执行失败则会执行Full GC
使用了大对象 //大对象会直接进入老年代
在程序中长期持有了对象的引用 //对象年龄达到指定阈值也会进入老年代
对于我们的情况,可以初步排除1,2两种情况,最有可能是4和5这两种情况。为了进一步排查原因,我们在线上开启了 -XX:+HeapDumpBeforeFullGC。
注意:JVM在执行dump操作的时候是会发生stop the word事件的,也就是说此时所有的用户线程都会暂停运行。为了在此期间也能对外正常提供服务,建议采用分布式部署,并采用合适的负载均衡算法
JVM参数的设置:
线上这个dubbo服务是分布式部署,在其中一台机子上开启了 -XX:HeapDumpBeforeFullGC,总体JVM参数如下:1
2
3
4
5
6
7
8
9
10
11-Xmx2g
-XX:+HeapDumpBeforeFullGC
-XX:HeapDumpPath=.
-Xloggc:gc.log
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100m
-XX:HeapDumpOnOutOfMemoryErrorDump文件分析
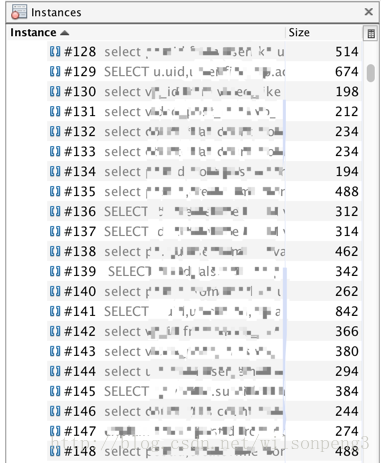
dump下来的文件大约1.8g,用jvisualvm查看,发现用char[]类型的数据占用了41%内存,同时另外一个com.alibaba.druid.stat.JdbcSqlStat类型的数据占用了35%的内存,也就是说整个堆中几乎全是这两类数据。
查看char[]类型数据,发现几乎全是sql语句。
接下来查看char[]的引用情况:
找到了JdbcSqlStat类,在代码中查看这个类的代码,关键代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//构造函数只有这一个
public JdbcSqlStat(String sql){
this.sql = sql;
this.id = DruidDriver.createSqlStatId();
}
//查看这个函数的调用情况,找到com.alibaba.druid.stat.JdbcDataSourceStat#createSqlStat方法:
public JdbcSqlStat createSqlStat(String sql) {
lock.writeLock().lock();
try {
JdbcSqlStat sqlStat = sqlStatMap.get(sql);
if (sqlStat == null) {
sqlStat = new JdbcSqlStat(sql);
sqlStat.setDbType(this.dbType);
sqlStat.setName(this.name);
sqlStatMap.put(sql, sqlStat);
}
return sqlStat;
} finally {
lock.writeLock().unlock();
}
}
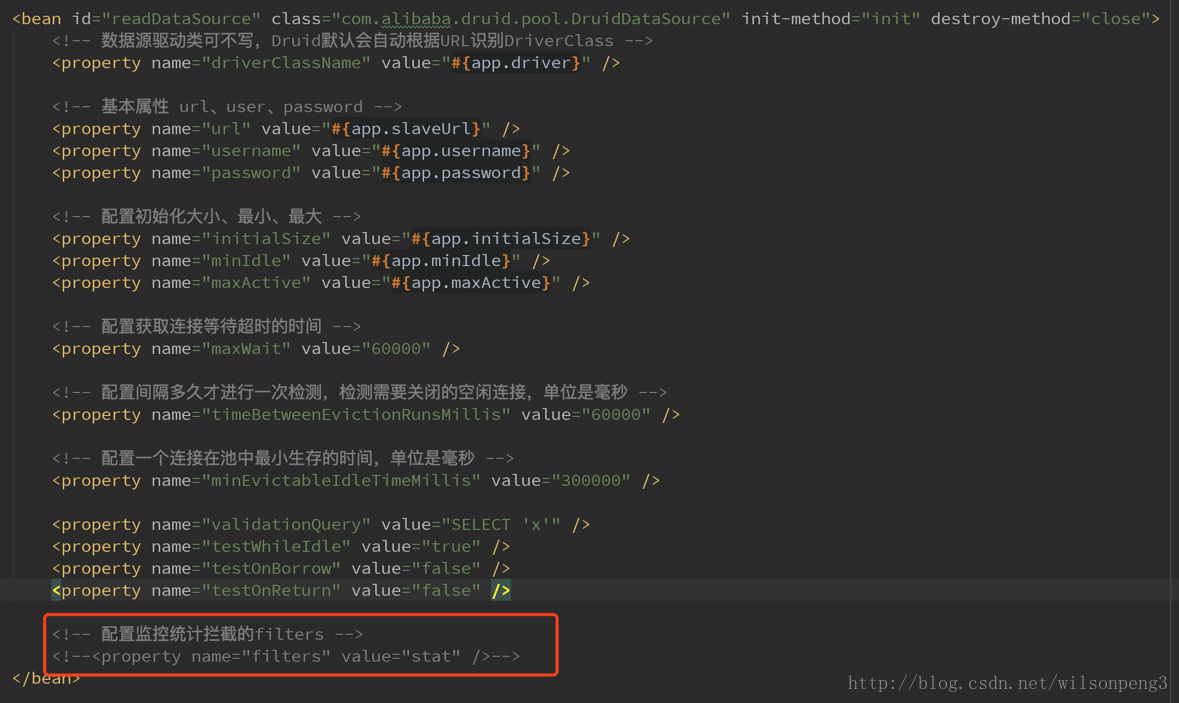
//这里用了一个map来存放所有的sql语句。其实到这里也就知道什么原因造成了这个问题,因为我们使用的数据源是阿里巴巴的druid,这个druid提供了一个sql语句监控功能,同时我们也开启了这个功能。只需要在配置文件中把这个功能关掉应该就能消除这个问题,事实也的确如此,关掉这个功能后到目前为止线上没再触发FullGC
其他
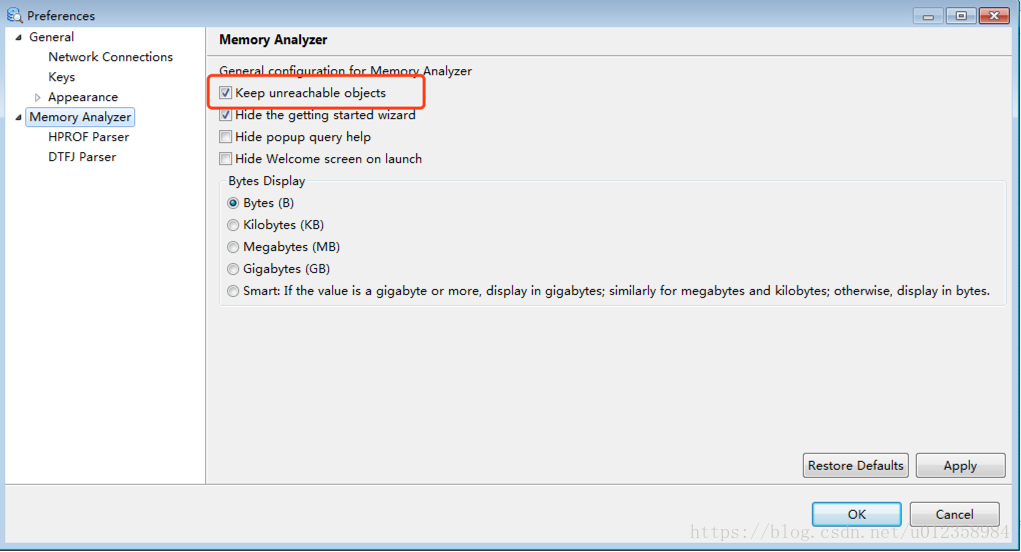
如果用mat工具查看,建议把 “Keep unreachable objects” 勾上,否则mat会把堆中不可达的对象去除掉,这样我们的分析也许会变得没有意义。如下图:Window–>References 。另外jvisualvm对ool的支持不是很好,如果需要oql建议使用mat。什么情况下会出现内存溢出,内存泄漏
内存泄漏memory leak:是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
内存溢出 out of memory:指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即所谓的内存溢出。
Java内存泄漏的根本原因是什么呢?长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是Java中内存泄漏的发生场景。具体主要有如下几大类:
静态集合类引起内存泄漏:
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
例如
1
2
3
4
5
6Static Vector v = new Vector(10);
for(int i = 1; i<100; i++){
Object o = new Object();
v.add(o);
o = null;
}在这个例子中,循环申请Object 对象,并将所申请的对象放入一个Vector 中,如果仅仅释放引用本身(o=null),那么Vector 仍然引用该对象,所以这个对象对GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从Vector 中删除,最简单的方法就是将Vector对象设置为null。
当集合里面的对象属性被修改后,再调用remove()方法时不起作用。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public static void main(String[] args) {
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("唐僧", "pwd1", 25);
Person p2 = new Person("孙悟空", "pwd2", 26);
Person p3 = new Person("猪八戒", "pwd3", 27);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println("总共有:" + set.size() + " 个元素!");
// 结果:总共有:3 个元素!
p3.setAge(2);
// 修改p3的年龄,此时p3元素对应的hashcode值发生改变
set.remove(p3);
// 此时remove不掉,造成内存泄漏
set.add(p3);
// 重新添加,居然添加成功
System.out.println("总共有:" + set.size() + " 个元素!");
//结果:总共有:4 个元素!
for (Person person : set) {
System.out.println(person);
}
}监听器
在java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如addXXXListener()等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
各种连接
比如数据库连接(dataSourse.getConnection()),网络连接(socket)和IO连接,除非其显式的调用了其close() 方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。
内部类和外部模块的引用
内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。此外程序员还要小心外部模块不经意的引用,例如程序员A 负责A 模块,调用了B 模块的一个方法如:
public void registerMsg(Object b);这种调用就要非常小心了,传入了一个对象,很可能模块B就保持了对该对象的引用,这时候就需要注意模块B 是否提供相应的操作去除引用。
单例模式
不正确使用单例模式是引起内存泄漏的一个常见问题,单例对象在初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部的引用,那么这个对象将不能被JVM正常回收,导致内存泄漏,考虑下面的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class A {
public A() {
B.getInstance().setA(this);
}
}
//B类采用单例模式
class B {
private A a;
private static B instance = new B();
private B() {
}
public static B getInstance() {
return instance;
}
}显然B采用singleton模式,它持有一个A对象的引用,而这个A类的对象将不能被回收。
java内存溢出常见的有:
PermGen space
发生这种问题的原意是程序中使用了大量的jar或class,使java虚拟机装载类的空间不够,与Permanent Generation space有关。解决这类问题有以下两种办法:
- 增加java虚拟机中的XX:PermSize和XX:MaxPermSize参数的大小,其中XX:PermSize是初始永久保存区域大小,XX:MaxPermSize是最大永久保存区域大小。如针对tomcat6.0,在catalina.sh 或catalina.bat文件中一系列环境变量名说明结束处(大约在70行左右) 增加一行:
JAVA_OPTS=" -XX:PermSize=64M -XX:MaxPermSize=128m"如果是windows服务器还可以在系统环境变量中设置。感觉用tomcat发布sprint+struts+hibernate架构的程序时很容易发生这种内存溢出错误。 - 清理应用程序中web-inf/lib下的jar,如果tomcat部署了多个应用,很多应用都使用了相同的jar,可以将共同的jar移到 tomcat共同的lib下,减少类的重复加载。
- 增加java虚拟机中的XX:PermSize和XX:MaxPermSize参数的大小,其中XX:PermSize是初始永久保存区域大小,XX:MaxPermSize是最大永久保存区域大小。如针对tomcat6.0,在catalina.sh 或catalina.bat文件中一系列环境变量名说明结束处(大约在70行左右) 增加一行:
Java heap space
发生这种问题的原因是java虚拟机创建的对象太多,在进行垃圾回收之前,虚拟机分配的到堆内存空间已经用满了,与Heap space有关。解决这类问题有两种思路:
- 检查程序,看是否有死循环或不必要地重复创建大量对象。找到原因后,修改程序和算法。 我以前写一个使用K-Means文本聚类算法对几万条文本记录(每条记录的特征向量大约10来个)进行文本聚类时,由于程序细节上有问题,就导致了 Java heap space的内存溢出问题,后来通过修改程序得到了解决。
- 增加Java虚拟机中Xms(初始堆大小)和Xmx(最大堆大小)参数的大小。如:
set JAVA_OPTS= -Xms256m -Xmx1024m
unable to create new native thread
在java应用中,有时候会出现这样的错误:OutOfMemoryError: unable to create new native thread.这种怪事是因为JVM已经被系统分配了大量的内存(比如1.5G),并且它至少要占用可用内存的一半。有人发现,在线程个数很多的情况下, 你分配给JVM的内存越多,那么,上述错误发生的可能性就越大。
那么是什么原因造成这种问题呢?
每一个32位的进程最多可以使用2G的可用内存,因为另外2G被操作系统保留。这里假设使用1.5G给JVM,那么还余下500M可用内存。这 500M内存中的一部分必须用于系统dll的加载,那么真正剩下的也许只有400M,现在关键的地方出现了:当你使用Java创建一个线程,在JVM的内存里也会创建一个Thread对象,但是同时也会在操作系统里创建一个真正的物理线程(参考JVM规范),操作系统会在余下的400兆内存里创建这个物理线程,而不是在JVM的1500M的内存堆里创建。在jdk1.4里头,默认的栈大小是256KB,但是在jdk1.5里头,默认的栈大小为1M每线程, 因此,在余下400M的可用内存里边我们最多也只能创建400个可用线程。
这样结论就出来了,要想创建更多的线程,你必须减少分配给JVM的最大内存。还有一种做法是让JVM宿主在你的 JNI 代码里边。

简述Java线程栈
Java线程栈从线程创建时存在,并且是私有的。线程栈用户存储栈帧,栈帧用于存储局部变量、中间运算结果。所以局部是不存在并发的问题,因为每个栈是私有的。虚拟机只会对Java栈进行二种操作:以栈帧为单位的压栈和出栈。对于执行引擎来说,在活动线程中,只有位于栈顶的栈帧才是有效的,称为当前栈帧(Current Stack Frame),与这个栈帧相关联的方法称为当前方法(Current Method)。执行引擎运行的所有字节码指令都只针对当前栈帧进行操作。(栈帧中各个部分的作用和数据结构详见《深入理解虚拟机》第8章)。
JVM 年轻代到年老代的晋升过程的判断条件是什么呢
虚拟机给每个对象定义一个对象年龄计数器。如果对象在Eden出生并经过第一次Minor GC后仍然存活,并且能被Survivor容纳的话,将被移动到Survivor空间中,并且对象年龄设为1。对象在Survivor区中每“熬过”一次Minor GC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15岁),就将会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
还有一种方式是动态对象年龄判定。为了适应不同程序的内存状况,虚拟机并不是永远地要求对象的年龄必须达到看MaxTenuringThreshold才能晋升老年代,如果Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到MaxTenuringThreshold中要求的年龄。
类加载为什么要使用双亲委派模式,有没有什么场景是打破了这个模式
使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是Java类随着它的加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有使用双亲委派模型,有各个类加载器自行去加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,Java类型体系中最基础的行为也就无法保证,应用程序也将变得一片混乱。
双亲委派模型的实现很简单,实现代码都集中在java.lang.ClassLoader的loadClass()方法之中,逻辑清晰易懂:先检查是否已经被加载过,若没有加载则调用父加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
破坏双亲委派模式的场景:
JDK1.2之前还没有引入双亲委派模式,为了向前兼容,JDK1.2之后的java.lang.ClassLoader添加了一个新的protected方法findClass(),在此之前,用户去继承java.lang.ClassLoader的唯一目的就是重写loadClass()方法,因为虚拟机在进行类加载的时候会调用加载器的私有方法loadClassInternal(),而这个方法的唯一逻辑就是去调用自己的loadClass()。JDK1.2之后已不提倡用户再去覆盖loadClass()方法,而应当把自己的类加载逻辑写到findClass()方法来完成加载,这样就可以保证新写出来的类加载器是符合双亲委派规则的。
JNDI服务的代码有启动类加载器去加载,但JNDI的目的就是对资源进行集中管理和查找,它需要调用有独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者的代码,单启动类加载器不可能“认识”这些代码。为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。JNDI服务使用这个线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载动作,这个行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都是采用这种方式,例如:JNDI、JDBC、JCE、JAXB、和JBI等。
业界“事实上”Java模块化标准的OSGi,它实现模块化热部署的关键就是它自定义的类加载器机制的实现。在OSGi环境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构。具体详见《深入理解虚拟机》第7章。
OOM错误,stackoverflow错误,permgen space错误
OutOfMemoryError异常
除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(OOM)异常的可能,
Java Heap 溢出
一般的异常信息:java.lang.OutOfMemoryError:Java heap spacess
java堆用于存储对象实例,我们只要不断的创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,就会在对象数量达到最大堆容量限制后产生内存溢出异常。
出现这种异常,一般手段是先通过内存映像分析工具(如Eclipse Memory Analyzer)对dump出来的堆转存快照进行分析,重点是确认内存中的对象是否是必要的,先分清是因为内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链。于是就能找到泄漏对象时通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收。
如果不存在泄漏,那就应该检查虚拟机的参数(-Xmx与-Xms)的设置是否适当。
虚拟机栈和本地方法栈溢出
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常
这里需要注意当栈的大小越大可分配的线程数就越少。
运行时常量池溢出
异常信息:java.lang.OutOfMemoryError:PermGen space
如果要向运行时常量池中添加内容,最简单的做法就是使用String.intern()这个Native方法。该方法的作用是:如果池中已经包含一个等于此String的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。由于常量池分配在方法区内,我们可以通过-XX:PermSize和-XX:MaxPermSize限制方法区的大小,从而间接限制其中常量池的容量。
方法区溢出
方法区用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。
异常信息:java.lang.OutOfMemoryError:PermGen space
方法区溢出也是一种常见的内存溢出异常,一个类如果要被垃圾收集器回收,判定条件是很苛刻的。在经常动态生成大量Class的应用中,要特别注意这点。
本机直接内存溢出
直接内存并不是虚拟机运行时数据区的一部分,也不是java虚拟机规范中定义的内存区域,是jvm外部的内存区域,这部分区域也可能导致OutOfMemoryError异常。
由DirectMemory导致的内存溢出,一个明显的特征是在Heap Dump文件中不会看见明显的异常,如果发现OOM之后Dump文件很小,而程序中又直接或间接使用了NIO,那就可以考虑检查一下是不是这方面的原因。
GC日志分析
摘录GC日志一部分(前部分为年轻代gc回收;后部分为full gc回收):
1
2
32016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs]
2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs]通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen属于Parallel收集器。其中PSYoungGen表示gc回收前后年轻代的内存变化;ParOldGen表示gc回收前后老年代的内存变化;PSPermGen表示gc回收前后永久区的内存变化。young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少full gc的次数
回收方法区
方法区回收价值很低,主要回收废弃的常量和无用的类。
如何判断无用的类:
该类所有实例都被回收(Java堆中没有该类的对象)
加载该类的ClassLoader已经被回收
该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方利用反射访问该类
Java对象创建过程
JVM遇到一条新建对象的指令时首先去检查这个指令的参数是否能在常量池中定义到一个类的符号引用。然后加载这个类(类加载过程在后边讲)
为对象分配内存。一种办法“指针碰撞”、一种办法“空闲列表”,最终常用的办法“本地线程缓冲分配(TLAB)”
将除对象头外的对象内存空间初始化为0
对对象头进行必要设置
Java对象结构
Java对象由三个部分组成:对象头、实例数据、对齐填充。
对象头由两部分组成,第一部分存储对象自身的运行时数据:哈希码、GC分代年龄、锁标识状态、线程持有的锁、偏向线程ID(一般占32/64 bit)。第二部分是指针类型,指向对象的类元数据类型(即对象代表哪个类)。如果是数组对象,则对象头中还有一部分用来记录数组长度。
实例数据用来存储对象真正的有效信息(包括父类继承下来的和自己定义的)
对齐填充:JVM要求对象起始地址必须是8字节的整数倍(8字节对齐)
Java对象的定位方式
句柄池、直接指针。
JVM的永久代中会发生垃圾回收么?
垃圾回收不会发生在永久代,如果永久代满了或者是超过了临界值,会触发完全垃圾回收(Full GC)。如果你仔细查看垃圾收集器的输出信息,就会发现永久代也是被回收的。这就是为什么正确的永久代大小对避免Full GC是非常重要的原因。请参考下Java8:从永久代到元数据区 (注:Java8中已经移除了永久代,新加了一个叫做元数据区的native内存区)
与垃圾回收相关的JVM参数:
命令 说明 -Xms / -Xmx 堆的初始大小 / 堆的最大大小 -Xmn 堆中年轻代的大小 -XX:-DisableExplicitGC 让System.gc()不产生任何作用 -XX:+PrintGCDetails 打印GC的细节 -XX:+PrintGCDateStamps 打印GC操作的时间戳 -XX:NewSize / XX:MaxNewSize 设置新生代大小/新生代最大大小 -XX:NewRatio 可以设置老生代和新生代的比例 -XX:PrintTenuringDistribution 设置每次新生代GC后输出幸存者乐园中对象年龄的分布 -XX:InitialTenuringThreshold 设置老年代阀值的初始值 -XX:MaxTenuringThreshold 设置老年代阀值的最大值 -XX:TargetSurvivorRatio 设置幸存区的目标使用率
Linux
常用命令
显示目录内容
ls -a显示当前目录下的所有文件及目录 (ls内定将文件名或目录名称开头为”.”的视为隐藏档,不会列出)ls -ltr s*列出当前目录下所有名称以 s 开头的文件,越新的排越后面
查看文本文件内容
cat
从第一行开始显示全部的文本内容;
tac
从最后一行开始,倒序显示全部分文本内容,与cat相反;
nl
显示文本时,可以输出行号;
more
按页显示文本内容;
- 按一下空格则往下翻一页
- 按一下Enter则往下翻一行
- 按一下B键往上翻一页
- 不能往上一行一行的翻回去了
- :f 可以显示文件名和现在的行数
- q退出
less
与more差不多,也是按页显示文本内容,区别是less可以一行一行的回退,more回退只能一页一页回退;
- more命令的所有按键less都支持
- ↑↓箭头可以实现一行一行的上下翻
- PageDown/PageUp可以实现一页一页的上下翻
head
从头开始显示文件指定的行数;
默认只显示文件的前10行文本内容
tail
显示文件指定的结尾的行数,但每一行的位置还是原文件中的位置,不会像tac那样与原文件相反。
默认只显示从文件最后一行开始的10行文本内容
tail -100f test.log: 实时监控100行日志
查找文件
find -name "filename"在当前目录下查找指定文件find path -name "filename"在指定目录下查找指定文件find path -name "prefix*"在指定目录下查找以prefix为前缀的文件find path -iname "prefix*"在指定目录下查找以prefix为前缀的文件,忽略大小写。man find查看find命令的帮助文档
检索文件内容:grep
grep 'partial\[true\]' test.log在test.log文件中检索包含patrial[true]的行grep -o 'engine\[[0-9a-z]*\]'筛选出能够匹配指定正则表达式的内容,如engine[d93kd93nfut48]grep -v 'abc'过滤掉包含指定字符串的内容(反向查找)
查看进程状态:ps
ps -ef|grep java查找特定进程
文本分析工具:awk
awk '{print $1,$4}' test.txt每行按空格或TAB分割,输出文本中的1、4项awk -F ',' $1,$4}' test.txt每行按逗号分割,输入文本的1、4项awk '$1 == "tcp" && $2 == 1 {print $0}' test.txt输出第一项为tcp,第二项为1的行
IO
概念
流
流(Stream),输入或输出管道中一串连续不断的有序数据。平常我们说的输入流与输出流指的就是输入流管道和输出流管道。与输入流管道相连的盛放数据的媒介就是流的源头,用于提供输入流管道抽取的流;与输出流管道相连的就是流的目的地,就是接收输出流管道中流的媒介,这些媒介可以是内存、磁盘、网络等。
一个流可以理解为一个数据的序列。输入流表示从一个源读取数据,输出流表示向一个目标写数据。
序列化
Java序列化是指把Java对象保存为二进制字节码的过程,Java反序列化是指把二进制码重新转换成Java对象的过程。
为什么需要序列化呢?
一般情况下Java对象的声明周期都比Java虚拟机的要短,实际应用中我们希望在JVM停止运行之后能够持久化指定的对象,这时候就需要把对象进行序列化之后保存。
需要把Java对象通过网络进行传输的时候。因为数据只能够以二进制的形式在网络中进行传输,因此当把对象通过网络发送出去之前需要先序列化成二进制数据,在接收端读到二进制数据之后反序列化成Java对象。
序列化及反序列化相关知识
在Java中,只要一个类实现了
java.io.Serializable接口,那么它就可以被序列化。通过
ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是
private static final long serialVersionUID)序列化并不保存静态变量。
要想将父类对象也序列化,就需要让父类也实现
Serializable接口。Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
serialVersionUID
serialVersionUID 表示可序列化类的版本,在反序列化对象时,用来确认序列化与反序列化该对象所使用的类的版本是否兼容。 如果类的版本不一致,那么反序列化将不能正常进行,抛出InvalidClassException。
如果一个可序列化的类没有包含serialVersionUID,运行时会根据这个类的特征自动计算出一个serialVersionUID。 那么,为什么不能用默认的这个实现呢,似乎更省事? 因为不同的编译器实现会导致同一个类的源代码文件,被计算出不同的serialVersionUID.
分类
按流方向分类
从流的方向上可分为两类(在java中是站在程序角度来区分流的方向,将数据读取到程序中就是输入流;反之,将程序中的数据写出去就是输出流):- 输入流: 从数据源中将数据读取到程序中的流。
- 输出流:程序将数据写入到目的地的流。
按流的数据类型分类
- 字节流: 以8位的字节形式来读写的流。他们的标志是名称以Stream结尾。InputStream与OutputStream分别是所有字节输入流与字节输出流的抽象父类。
- 字符流: 以字符形式来读写的流。它们的标志是名称以Reader或者Writer结尾。并且Reader和Writer分别是所有字符输入流与字符输出流的抽象父类。
按照实现功能分类
- 节点流:程序用于直接操作目标设备所对应的类叫节点流。
- 处理流:程序通过一个间接流类去调用节点流类,以达到更加灵活方便地读写各种类型的数据,这个间接流类就是处理流。
流分类 使用分类 字节输入流 字节输出流 字符输入流 字符输出流 抽象基类 InputStream OutputStream Reader Writer 节点流 访问文件 FileInputStream FileOutStream FileReader FileWriter 访问数值 CharArrayReader CharArrayWriter 访问管道 PipedInputStream PipedOutStream PipedReader PipedWriter 访问字符串 StringReader StringWriter 处理流 缓冲流 BufferedInputStream BufferedReader BufferedWriter 转换流 InputStreamReader OutputStreamWriter 对象流 ObjectInputStream ObjectOutputStream FilterInputStream FilterOutputStream FilterReader FilterWriter 打印流 PrintStream PrintWriter PushbackInputStream PushbackReader 特殊流 DataInputStream DataOutputStream
Java IO体系架构图
java IO流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java IO流的40多个类都是从如下4个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
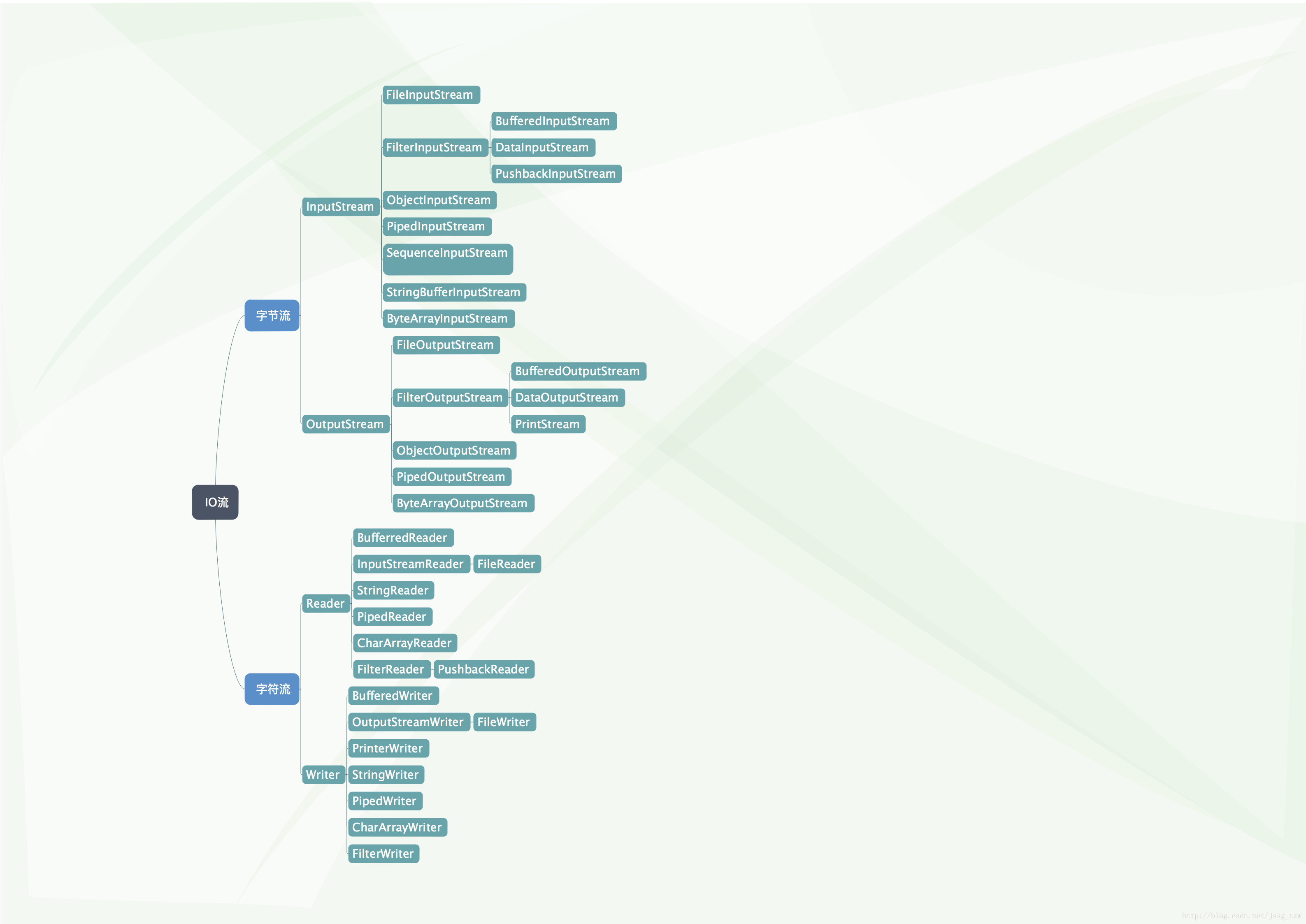
(1) 按操作方式分类结构图:

(2)按操作对象分类结构图

常用IO流
IO体系的基类(InputStream/Reader,OutputStream/Writer)
字节流和字符流的操作方式基本一致,只是操作的数据单元不同——字节流的操作单元是字节,字符流的操作单元是字符。
InputStream和Reader是所有输入流的抽象基类,本身并不能创建实例来执行输入,但它们将成为所有输入流的模板,所以它们的方法是所有输入流都可使用的方法。
在InputStream里面包含如下3个方法。
int read();从输入流中读取单个字节(相当于从水管中取出一滴水),返回所读取的字节数据(字节数据可直接转换为int类型)。int read(byte[] b)从输入流中最多读取b.length个字节的数据,并将其存储在字节数组b中,返回实际读取的字节数。int read(byte[] b,int off,int len);从输入流中最多读取len个字节的数据,并将其存储在数组b中,放入数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字节数。
在Reader中包含如下3个方法。
int read();从输入流中读取单个字符(相当于从水管中取出一滴水),返回所读取的字符数据(字节数据可直接转换为int类型)。int read(char[] b)从输入流中最多读取b.length个字符的数据,并将其存储在字节数组b中,返回实际读取的字符数。int read(char[] b,int off,int len);从输入流中最多读取len个字符的数据,并将其存储在数组b中,放入数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字符数。
对比InputStream和Reader所提供的方法,就不难发现这两个基类的功能基本是一样的。InputStream和Reader都是将输入数据抽象成水管,所以程序即可以通过read()方法每次读取一个”水滴“,也可以通过read(char[] chuf)或者read(byte[] b)方法来读取多个“水滴”。当使用数组作为read()方法中的参数, 我们可以理解为使用一个“竹筒”到水管中取水,read(char[] cbuf)方法的参数可以理解成一个”竹筒“,程序每次调用输入流read(char[] cbuf)或read(byte[] b)方法,就相当于用“竹筒”从输入流中取出一筒“水滴”,程序得到“竹筒”里面的”水滴“后,转换成相应的数据即可;程序多次重复这个“取水”过程,直到最后。程序如何判断取水取到了最后呢?直到read(char[] chuf)或者read(byte[] b)方法返回-1,即表明到了输入流的结束点。

InputStream和Reader提供的一些移动指针的方法:
void mark(int readAheadLimit);在记录指针当前位置记录一个标记(mark)。boolean markSupported();判断此输入流是否支持mark()操作,即是否支持记录标记。void reset();将此流的记录指针重新定位到上一次记录标记(mark)的位置。long skip(long n);记录指针向前移动n个字节/字符。
OutputStream和Writer:
OutputStream和Writer的用法也非常相似,两个流都提供了如下三个方法:
void write(int c);将指定的字节/字符输出到输出流中,其中c即可以代表字节,也可以代表字符。void write(byte[]/char[] buf);将字节数组/字符数组中的数据输出到指定输出流中。void write(byte[]/char[] buf, int off,int len );将字节数组/字符数组中从off位置开始,长度为len的字节/字符输出到输出流中。
因为字符流直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组,即以String对象作为参数。Writer里面还包含如下两个方法。
void write(String str);将str字符串里包含的字符输出到指定输出流中。void write (String str, int off, int len);将str字符串里面从off位置开始,长度为len的字符输出到指定输出流中。
IO体系的基类文件流的使用(FileInputStream/FileReader ,FileOutputStream/FileWriter)
前面说过InputStream和Reader都是抽象类,本身不能创建实例,但它们分别有一个用于读取文件的输入流:FileInputStream和FileReader,它们都是节点流——会直接和指定文件关联。下面程序示范使用FileInputStream和FileReader。
使用FileInputStream读取文件:
1 | public class MyClass { |
注:上面程序最后使用了fis.close()来关闭该文件的输入流,与JDBC编程一样,程序里面打开的文件IO资源不属于内存的资源,垃圾回收机制无法回收该资源,所以应该显示的关闭打开的IO资源。Java 7改写了所有的IO资源类,它们都实现了AntoCloseable接口,因此都可以通过自动关闭资源的try语句来关闭这些IO流。
使用FileReader读取文件:
1 | public class FileReaderTest { |
可以看出使用FileInputStream和FileReader进行文件的读写并没有什么区别,只是操作单元不同而且。
FileOutputStream/FileWriter是IO中的文件输出流,下面介绍这两个类的用法。
FileOutputStream的用法:
1 | public class FileOutputStreamTest { |
运行程序可以看到输出流指定的目录下多了一个文件:newTest.txt, 该文件的内容和Test.txt文件的内容完全相同。FileWriter的使用方式和FileOutputStream基本类似,这里就带过。
注: 使用java的io流执行输出时,不要忘记关闭输出流,关闭输出流除了可以保证流的物理资源被回收之外,可能还可以将输出流缓冲区中的数据flush到物理节点中里(因为在执行close()方法之前,自动执行输出流的flush()方法)。java很多输出流默认都提供了缓存功能,其实我们没有必要刻意去记忆哪些流有缓存功能,哪些流没有,只有正常关闭所有的输出流即可保证程序正常。
缓冲流的使用(BufferedInputStream/BufferedReader, BufferedOutputStream/BufferedWriter):
下面介绍字节缓存流的用法(字符缓存流的用法和字节缓存流一致就不介绍了):
1 | public class BufferedStreamTest { |
可以看到使用字节缓存流读取和写入数据的方式和文件流(FileInputStream,FileOutputStream)并没有什么不同,只是把处理流套接到文件流上进行读写。
上面代码中我们使用了缓存流和文件流,但是我们只关闭了缓存流。这个需要注意一下,当我们使用处理流套接到节点流上的使用的时候,只需要关闭最外层的处理就可以了。java会自动帮我们关闭下层的节点流。
转换流的使用(InputStreamReader/OutputStreamWriter)
下面以获取键盘输入为例来介绍转换流的用法。java使用System.in代表输入。即键盘输入,但这个标准输入流是InputStream类的实例,使用不太方便,而且键盘输入内容都是文本内容,所以可以使用InputStreamReader将其包装成BufferedReader,利用BufferedReader的readLine()方法可以一次读取一行内容,如下代码所示:
1 | public class InputStreamReaderTest { |
上面程序将System.in包装成BufferedReader,BufferedReader流具有缓存功能,它可以一次读取一行文本——以换行符为标志,如果它没有读到换行符,则程序堵塞。等到读到换行符为止。运行上面程序可以发现这个特征,当我们在控制台执行输入时,只有按下回车键,程序才会打印出刚刚输入的内容。
对象流的使用(ObjectInputStream/ObjectOutputStream)的使用
写入对象:
1 | public static void writeObject(){ |
读取对象:
1 | /** |
使用对象流的一些注意事项
读取顺序和写入顺序一定要一致,不然会读取出错。
在对象属性前面加transient关键字,则该对象的属性不会被序列化。
Java NIO
Java NIO 是 java 1.4 之后新出的一套IO接口,NIO中的N可以理解为Non-blocking,不单纯是New。
我们使用InputStream从输入流中读取数据时,如果没有读取到有效的数据,程序将在此处阻塞该线程的执行。其实传统的输入里和输出流都是阻塞式的进行输入和输出。 不仅如此,传统的输入流、输出流都是通过字节的移动来处理的(即使我们不直接处理字节流,但底层实现还是依赖于字节处理),也就是说,面向流的输入和输出一次只能处理一个字节,因此面向流的输入和输出系统效率通常不高。
从JDk1.4开始,java提供了一系列改进的输入和输出处理的新功能,这些功能被统称为新IO(NIO)。新增了许多用于处理输入和输出的类,这些类都被放在java.nio包及其子包下,并且对原io的很多类都以NIO为基础进行了改写。新增了满足NIO的功能。
NIO采用了内存映射对象的方式来处理输入和输出,NIO将文件或者文件的一块区域映射到内存中,这样就可以像访问内存一样来访问文件了。通过这种方式来进行输入/输出比传统的输入和输出要快的多。
Java NIO 概览
主要内容:
- NIO简介:Java NIO 是 java 1.4, 之后新出的一套IO接口NIO中的N可以理解为Non-blocking,不单纯是New。
- NIO的特性/NIO与IO区别:
- 1)IO是面向流的,NIO是面向缓冲区的;
- 2)IO流是阻塞的,NIO流是不阻塞的;
- 3)NIO有选择器,而IO没有。
- 读数据和写数据方式:
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
- NIO核心组件简单介绍
- Channels
- Buffers
- Selectors
Java NIO 之 Buffer(缓冲区)
主要内容:
Buffer(缓冲区)介绍:
- Java NIO Buffers用于和NIO Channel交互。 我们从Channel中读取数据到buffers里,从Buffer把数据写入到Channels;
- Buffer本质上就是一块内存区;
- 一个Buffer有三个属性是必须掌握的,分别是:capacity容量、position位置、limit限制。
Buffer的常见方法
- Buffer clear()
- Buffer flip()
- Buffer rewind()
- Buffer position(int newPosition)
Buffer的使用方式/方法介绍:
分配缓冲区(Allocating a Buffer):
1
ByteBuffer buf = ByteBuffer.allocate(28); //以ByteBuffer为例子
写入数据到缓冲区(Writing Data to a Buffer)
写数据到Buffer有两种方法:
1.从Channel中写数据到Buffer
1
int bytesRead = inChannel.read(buf); //read into buffer.
2.通过put写数据:
1
buf.put(127);
Buffer常用方法测试
说实话,NIO编程真的难,通过后面这个测试例子,你可能才能勉强理解前面说的Buffer方法的作用。
Java NIO 之 Channel(通道)
主要内容:
- Channel(通道)介绍
- 通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
- NIO Channel通道和流的区别:
- FileChannel的使用
- SocketChannel和ServerSocketChannel的使用
- ️DatagramChannel的使用
- Scatter / Gather
- Scatter: 从一个Channel读取的信息分散到N个缓冲区中(Buufer).
- Gather: 将N个Buffer里面内容按照顺序发送到一个Channel.
- 通道之间的数据传输
- 在Java NIO中如果一个channel是FileChannel类型的,那么他可以直接把数据传输到另一个channel。
- transferFrom() :transferFrom方法把数据从通道源传输到FileChannel
- transferTo() :transferTo方法把FileChannel数据传输到另一个channel
Java NIO之Selector(选择器)
主要内容:
Selector(选择器)介绍
- Selector 一般称 为选择器 ,当然你也可以翻译为 多路复用器 。它是Java NIO核心组件中的一个,用于检查一个或多个NIO Channel(通道)的状态是否处于可读、可写。如此可以实现单线程管理多个channels,也就是可以管理多个网络链接。
- 使用Selector的好处在于: 使用更少的线程来就可以来处理通道了, 相比使用多个线程,避免了线程上下文切换带来的开销。
Selector(选择器)的使用方法介绍
- Selector的创建
1
Selector selector = Selector.open();
- 注册Channel到Selector(Channel必须是非阻塞的)
1
2channel.configureBlocking(false);
SelectionKey key = channel.register(selector, Selectionkey.OP_READ);SelectionKey介绍
一个SelectionKey键表示了一个特定的通道对象和一个特定的选择器对象之间的注册关系。
从Selector中选择channel(Selecting Channels via a Selector)
选择器维护注册过的通道的集合,并且这种注册关系都被封装在SelectionKey当中.
停止选择的方法
wakeup()方法 和close()方法。
模板代码
有了模板代码我们在编写程序时,大多数时间都是在模板代码中添加相应的业务代码。
客户端与服务端简单交互实例
Java NIO之拥抱Path和Files
主要内容
一 文件I/O基石:Path:
- 创建一个Path
- File和Path之间的转换,File和URI之间的转换
- 获取Path的相关信息
- 移除Path中的冗余项
二 拥抱Files类:
- Files.exists() 检测文件路径是否存在
- Files.createFile() 创建文件
- Files.createDirectories()和Files.createDirectory()创建文件夹
- Files.delete()方法 可以删除一个文件或目录
- Files.copy()方法可以吧一个文件从一个地址复制到另一个位置
- 获取文件属性
- 遍历一个文件夹
- Files.walkFileTree()遍历整个目录
五种IO模型
在《Unix网络编程》一书中提到了五种IO模型,分别是:阻塞IO、非阻塞IO、多路复用IO、信号驱动IO以及异步IO。
阻塞IO模型
最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。
典型的阻塞IO模型的例子为:
data = socket.read();如果数据没有就绪,就会一直阻塞在read方法。
非阻塞IO模型
当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
典型的非阻塞IO模型一般如下:
1
2
3
4
5
6
7while(true){
data = socket.read();
if(data!= error){
处理数据
break;
}
}但是对于非阻塞IO就有一个非常严重的问题,在while循环中需要不断地去询问内核数据是否就绪,这样会导致CPU占用率非常高,因此一般情况下很少使用while循环这种方式来读取数据。
多路复用IO模型
多路复用IO模型是目前使用得比较多的模型。Java NIO实际上就是多路复用IO。
在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket读写事件进行时,才会使用IO资源,所以它大大减少了资源占用。
在Java NIO中,是通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。
也许有朋友会说,我可以采用 多线程+ 阻塞IO 达到类似的效果,但是由于在多线程 + 阻塞IO 中,每个socket对应一个线程,这样会造成很大的资源占用,并且尤其是对于长连接来说,线程的资源一直不会释放,如果后面陆续有很多连接的话,就会造成性能上的瓶颈。而多路复用IO模式,通过一个线程就可以管理多个socket,只有当socket真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用IO比较适合连接数比较多的情况。
另外多路复用IO为何比非阻塞IO模型的效率高是因为在非阻塞IO中,不断地询问socket状态是通过用户线程去进行的,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。
不过要注意的是,多路复用IO模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用IO模型来说,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
信号驱动IO模型
在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
异步IO模型
异步IO模型才是最理想的IO模型,在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个asynchronous read之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
也就说在异步IO模型中,IO操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。用户线程中不需要再次调用IO函数进行具体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用IO函数进行实际的读写操作;而在异步IO模型中,收到信号表示IO操作已经完成,不需要再在用户线程中调用IO函数进行实际的读写操作。
注意,异步IO是需要操作系统的底层支持,在Java 7中,提供了Asynchronous IO。
前面四种IO模型实际上都属于同步IO,只有最后一种是真正的异步IO,因为无论是多路复用IO还是信号驱动模型,IO操作的第2个阶段都会引起用户线程阻塞,也就是内核进行数据拷贝的过程都会让用户线程阻塞。
两种高性能IO设计模式
在传统的网络服务设计模式中,有两种比较经典的模式:一种是多线程,一种是线程池。
对于多线程模式,也就是说来了client,服务器就会新建一个线程来处理该client的读写事件,如下图所示:

这种模式虽然处理起来简单方便,但是由于服务器为每个client的连接都采用一个线程去处理,使得资源占用非常大。因此,当连接数量达到上限时,再有用户请求连接,直接会导致资源瓶颈,严重的可能会直接导致服务器崩溃。为了解决这种一个线程对应一个客户端模式带来的问题,提出了采用线程池的方式,也就说创建一个固定大小的线程池,来一个客户端,就从线程池取一个空闲线程来处理,当客户端处理完读写操作之后,就交出对线程的占用。因此这样就避免为每一个客户端都要创建线程带来的资源浪费,使得线程可以重用。
但是线程池也有它的弊端,如果连接大多是长连接,因此可能会导致在一段时间内,线程池中的线程都被占用,那么当再有用户请求连接时,由于没有可用的空闲线程来处理,就会导致客户端连接失败,从而影响用户体验。因此,线程池比较适合大量的短连接应用。
因此便出现了下面的两种高性能IO设计模式:Reactor和Proactor。
在Reactor模式中,会先对每个client注册感兴趣的事件,然后有一个线程专门去轮询每个client是否有事件发生,当有事件发生时,便顺序处理每个事件,当所有事件处理完之后,便再转去继续轮询,如下图所示:
![image.png]()
从这里可以看出,上面的五种IO模型中的多路复用IO就是采用Reactor模式。注意,上面的图中展示的是顺序处理每个事件,当然为了提高事件处理速度,可以通过多线程或者线程池的方式来处理事件。
在Proactor模式中,当检测到有事件发生时,会新起一个异步操作,然后交由内核线程去处理,当内核线程完成IO操作之后,发送一个通知告知操作已完成,可以得知,异步IO模型采用的就是Proactor模式。

常见面试问题
什么是比特(Bit),什么是字节(Byte),什么是字符(Char),它们长度是多少,各有什么区别
Bit:最小的二进制单位 ,是计算机的操作部分 取值0或者1
Byte:是计算机操作数据的最小单位由8位bit组成 取值(-128-127)
Char:是用户的可读写的最小单位,在Java里面由16位bit组成 取值(0-65535)Bit 是最小单位 计算机 只认识 0或者1
8个字节 是给计算机看的
字符 是看到的东西 一个字符=二个字节
PrintStream、BufferedWriter、PrintWriter的比较?
- PrintStream类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成PrintStream后进行输出。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过 checkError 方法测试的内部标志。另外,为了自动刷新,可以创建一个 PrintStream
- BufferedWriter:将文本写入字符输出流,缓冲各个字符从而提供单个字符,数组和字符串的高效写入。通过write()方法可以将获取到的字符输出,然后通过newLine()进行换行操作。BufferedWriter中的字符流必须通过调用flush方法才能将其刷出去。并且BufferedWriter只能对字符流进行操作。如果要对字节流操作,则使用BufferedInputStream。
- PrintWriter的println方法自动添加换行,不会抛异常,若关心异常,需要调用checkError方法看是否有异常发生,PrintWriter构造方法可指定参数,实现自动刷新缓存(autoflush);
System.out.println()是什么?println是PrintStream的一个方法。out是一个静态PrintStream类型的成员变量,System是一个java.lang包中的类,用于和底层的操作系统进行交互。什么是Filter流?
Filter Stream主要作用是用来对存在的流增加一些额外的功能,像给目标文件增加源文件中不存在的行数,或者增加拷贝的性能。有哪些可用的Filter流?
在java.io包中主要由4个可用的filter Stream。两个字节filter stream,两个字符filter stream. 分别是FilterInputStream, FilterOutputStream, FilterReader and FilterWriter.这些类是抽象类,不能被实例化。有些Filter流的子类:
- LineNumberInputStream:给目标文件增加行号
- DataInputStream:有些特殊的方法如
readInt(),readDouble()和readLine()等可以读取一个 int, double和一个string一次性的。 - BufferedInputStream:增加性能
- PushbackInputStream:推送要求的字节到系统中
SequenceInputStream的作用?
SequenceInputStream 合并流:能够将两个流合并成一个流。在拷贝多个文件到一个目标文件的时候是非常有用的。可用使用很少的代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class TwoFiles {
public static void main(String args[]) throws IOException
{
FileInputStream fistream1 = new FileInputStream("/Users/aihe/Desktop/Songshu/code/java8source/src/main/resources/A.txt"); // first source file
FileInputStream fistream2 = new FileInputStream("/Users/aihe/Desktop/Songshu/code/java8source/src/main/resources/B.txt"); //second source file
SequenceInputStream sistream = new SequenceInputStream(fistream1, fistream2);
FileOutputStream fostream = new FileOutputStream("C.txt"); // destination file
int temp;
while( ( temp = sistream.read() ) != -1)
{
System.out.print( (char) temp ); // to print at DOS prompt
fostream.write(temp); // to write to file
}
fostream.close();
sistream.close();
fistream1.close();
fistream2.close();
}
}说说管道流(Piped Stream)
有四种管道流, PipedInputStream, PipedOutputStream, PipedReader 和 PipedWriter,用于不同线程之间的相互通信。java的管道输入与输出实际上使用的是一个循环缓冲数组来实现,这个数组默认大小为1024字节。输入流PipedInputStream从这个循环缓冲数组中读数据,输出流PipedOutputStream往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流PipedOutputStream所在的线程将阻塞;当这个缓冲数组首次为空的时候,输入流PipedInputStream所在的线程将阻塞。
Java在它的jdk文档中提到不要在一个线程中同时使用PipeInpuStream和PipeOutputStream,这会造成死锁。
NIO与IO区别
IO是面向流的,NIO是面向缓冲区的;
IO流是阻塞的,NIO流是不阻塞的;
NIO有选择器,而IO没有。
说说File类
它不属于 IO流,也不是用于文件操作的,它主要用于知道一个文件的属性,读写权限,大小等信息。
说说RandomAccessFile?
它在java.io包中是一个特殊的类,既不是输入流也不是输出流,它两者都可以做到。他是Object的直接子类。通常来说,一个流只有一个功能,要么读,要么写。但是RandomAccessFile既可以读文件,也可以写文件。 DataInputStream 和 DataOutStream有的方法,在RandomAccessFile中都存在。
把包括基本类型在内的数据和字符串按顺序输出到数据源,或者按照顺序从数据源读入,一般用哪两个流
DataInputStream DataOutputStream
File类型中定义了什么方法来创建一级目录?
File类的mkdir方法根据抽象路径创建目录;File类的mkdirs方法根据抽象路径创建目录,包括创建必需但不存在的父目录
在unix服务器 www.openlab.com.cn 上提供了基于TCP的时间服务应用,该应用使用port为13。创建连接到此服务器的语句是:(A )
A Socket s = new Socket(“www.openlab.com.cn”, 13);
B Socket s = new Socket(“www.openlab.com.cn :13”);
C Socket s = accept(“www.openlab.com.cn”, 13);创建一个TCP客户程序的顺序是:(DACBE )
A 获得I/O流
B 关闭I/O流
C 对I/O流进行读写操作
D 建立socket
E 关闭socket创建一个TCP服务程序的顺序是:(BCADEGF )
A 创建一个服务线程处理新的连接
B 创建一个服务器socket
C 从服务器socket接受客户连接请求
D 在服务线程中,从socket中获得I/O流
E 对I/O流进行读写操作,完成与客户的交互
F 关闭socket
G 关闭I/O流Java UDP编程主要用到的两个类型是:( BD)
A UDPSocket
B DatagramSocket
C UDPPacket
D DatagramPacket说说File类
它不属于 IO流,也不是用于文件操作的,它主要用于知道一个文件的属性,读写权限,大小等信息。
说说RandomAccessFile?
它在java.io包中是一个特殊的类,既不是输入流也不是输出流,它两者都可以做到。他是Object的直接子类。通常来说,一个流只有一个功能,要么读,要么写。但是RandomAccessFile既可以读文件,也可以写文件。 DataInputStream 和 DataOutStream有的方法,在RandomAccessFile中都存在。
集合框架
List
ArrayList
ArrayList直接通过transient Object[] elementData一个Object的数组存储数据,默认初始容量是 10。每次扩容采用半倍扩容 newCapacity = oldCapacity + (oldCapacity >> 1);。
1 | public class ArrayList<E> extends AbstractList<E> |
LinkedList
LinkedList是靠一个名为Node的数据结构来存储数据和前后元素的指针,和双向链表类似。first和last分别存储了第一个和最后一个元素
1 | public class LinkedList<E> |
ArrayList 和 LinkedList 遍历时的时间复杂度
1
2
3
4
5
6public void loopList(List<Integer> lists) {
for (int i=0; i< lists.size(); i++) {
Integer integer = lists.get(i);
// TODO 处理数据
}
}List for 循环时间复杂度 get(i)时间复杂度 总时间复杂度 ArrayList O(n) O(1) O(n) LinkedList O(n) O(n) O(n2) 在数据量为 10000 的情况下,for 循环的用时分别是 20ms 和 648ms,而使用迭代器和 ForEach 遍历时用时均在 4-6ms 之间。
ForEach 循环底层使用的也是迭代器,所以和迭代器性能类似。
使用 迭代器(Iterator) 和 ForEach 遍历 List,不要使用传统的 For 循环。
LinkedList迭代器的next函数只是通过next指针快速得到下一个元素并返回。而get方法会从头遍历直到index下标。
泛型
定义
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。
语法
泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
泛型的类型参数可以有多个
不能创建一个确切的泛型类型的数组,但可以创建通配符类型的泛型数组
编译错误:
List<String>[] list = new List<String>[10];编译通过:
List<?>[] list = new List<?>[10];不能利用类型参数直接创建实例(
E = new E();)不能对确切的泛型类型使用
instanceof关键字编译错误:
list instanceof ArrayList<Integer>编译通过:
list instanceof ArrayList<?>静态方法无法访问类上定义的泛型,所以静态方法要使用泛型的话,必须定义成泛型方法。
多接口限制:
<T extends SomeClass & interface1 & interface2 & interface3>
类型擦除
Java泛型只能用于在编译期间的静态类型检查,编译器生成的代码会擦除相应的类型信息,到了运行期间实际上JVM知道泛型所代表的具体类型。这样做的原因是因为Java泛型是1.5之后才被引入的,为了保持向下的兼容性,所以只能做类型擦除来兼容以前的非泛型代码。
对于泛型代码,Java编译器实际上还会帮我们实现一个Bridge method。
一条规律,”Producer Extends, Consumer Super”:
- “Producer Extends” – 如果你需要一个只读List,用它来produce T,那么使用
? extends T。 - “Consumer Super” – 如果你需要一个只写List,用它来consume T,那么使用
? super T。 - 如果需要同时读取以及写入,那么我们就不能使用通配符了。
- “Producer Extends” – 如果你需要一个只读List,用它来produce T,那么使用
方法上是否定义泛型和类上是否定义没有必然的联系
在Java集合类框架中泛型被广泛应用
反射
什么是反射
JAVA反射机制是在运行状态中,对于任意一个实体类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
Java反射机制的实现要借助于4个类:Class,Constructor,Field,Method。
反射就是把java类中的各种成分映射成一个个的Java对象。
反射:程序在运行状态中,可以动态加载一个只有名称的类,加载完类之后,在堆内存中,就产生了一个 Class 类型的对象,这个对象就包含了这个类完整的结构信息,通过这个对象我们可以看到类的结构。这个对象就像一面镜子,所以我们形象的称之为——反射
反射能做什么?
代码可以在运行时装配,无需在组件之间进行源代码链接,降低代码的耦合度;还有动态代理的实现等等,JDBC原生代码注册驱动,hibernate 的实体类,Spring 的 AOP 等等都有反射的实现。通过反射运行配置文件内容,通过反射越过泛型检查。
- RTTI(Run-Time Type Identification 运行时类型识别)和反射之间的区别在于,RTTI 编译器在编译时打开和检查.class文件,反射在运行时打开和检查.class文件
- 获取 Class 类对象有三种方法,使用 Class.forName 静态方法、使用 .class 方法、使用类对象的 getClass() 方法。
- 通过反射创建类对象主要有两种方式:通过 Class 对象的 newInstance() 方法、通过 Constructor 对象的 newInstance() 方法。
- Method 类的 invoke 方法内部有两种实现方式,一种是 native 原生的实现方式,一种是 Java 实现方式Native 版本一开始启动快,但是随着运行时间变长,速度变慢。Java 版本一开始加载慢,但是随着运行时间变长,速度变快。正是因为两种存在这些问题,所以第一次加载的时候我们会发现使用的是NativeMethodAccessorImpl 的实现,而当反射调用次数超过 15 次之后,则使用 MethodAccessorGenerator 生成的 MethodAccessorImpl 对象去实现反射。
接口
接口设计规范
字段类型统一使用 String 类型,参数和返回值都使用 String 类型。Boolean类型一律使用1/0来表示。
使用此接口的用户,对方可能是Java,也可能是VB6,也可能是C#,不要使用某种编程语言的特定类型,比较好的一种方式是,参数和返回值都使用string类型,这样基本上的编程语言都能支持。
响应数据统一格式:code、msg、data。
接口路径中需要加入版本号信息(使用 v1、v2 依次递推)
分页数据中必须包含:
recordCount: 当前页记录数
totalCount: 总记录数
pageNo: 当前页码
pageSize: 每页大小
totalPage: 总页数
支付接口的设计
聚合支付平台的核心,就是怎么合理的去管理接入的各种支付SDK,从官网下载的 SDK,不做任何逻辑修改,就直接放到项目的目录中使用,这样做虽然开发成本很低,但弊端颇多:
- 首先要说的就是不易维护,各支付SDK代码结构、风格不一样,后期维护成本高;
- 代码各自为政,没有统一的调用方法;
- 配置分散,无法集中维护系统配置项;
- 无法提供统一有效的日志数据等
因此,首先定义一个Interface,然后每次接入新的支付方式的过程,其实就是实现该Interface的过程。
通常情况下,一种支付方式有一个class来实现,但面对一种支付方式提供了多种支付场景,比如微信(提供了公众号支付、APP支付、扫码支付、H5支付、小程序支付、微信免密代扣等)、中国银联(提供了PC网关支付、WAP支付、APP支付、银联云闪付等),建议针对每种不同的支付场景,都有单独的class来实现,理由如下:
- 不同的支付场景,程序执行的流程也不一样,比如中国银联PC网关支付,是需要将支付报文通过客户端浏览器表单POST给银联支付网关,跳转至银联支付网页进行支付,而银联APP支付则是通过curl将支付报文提交给银联支付网关,再将其返回的tn码返回给商户APP,商户APP凭该tn码发起支付交易;
- 对订单系统的订单支付方式展示更加准确,分配给商户不同购物平台(PC端、H5端、APP)的支付方式id是唯一的。如果商户系统不同支付场景所申请的商户号不一样,则需要在推送至财务系统的支付方式也不能重复,否则无法对账;
- 支付类的代码逻辑只关注于自身的支付逻辑处理,不引入额外的判断流程。
那么这时候就有一个很头疼的问题,代码冗余。大部分第三方支付,虽然提供了不同支付场景,但基础接口都是一样的,只是部分参数不同,或支付流程上面的少许差别。这时候就要考虑好以第三方支付平台为单位来封装一个支付抽象类,实现对第三方支付平台的所有api对接,不涉及到商户系统的业务流程,比如微信支付,创建一个WechatDriver抽象类
有了支付抽象类,针对每一种支付方法,都可以继承该抽象类,并拥有自己的独立的支付流程,比如:微信app支付,可以创建一个 WechatAppDriver 支付子类,支付子类调用抽象类提供的各种底层api,来实现支付、查询、退款等功能。
支付Interface、支付抽象类、支付子类三种支付类,它们之间的关系如下:
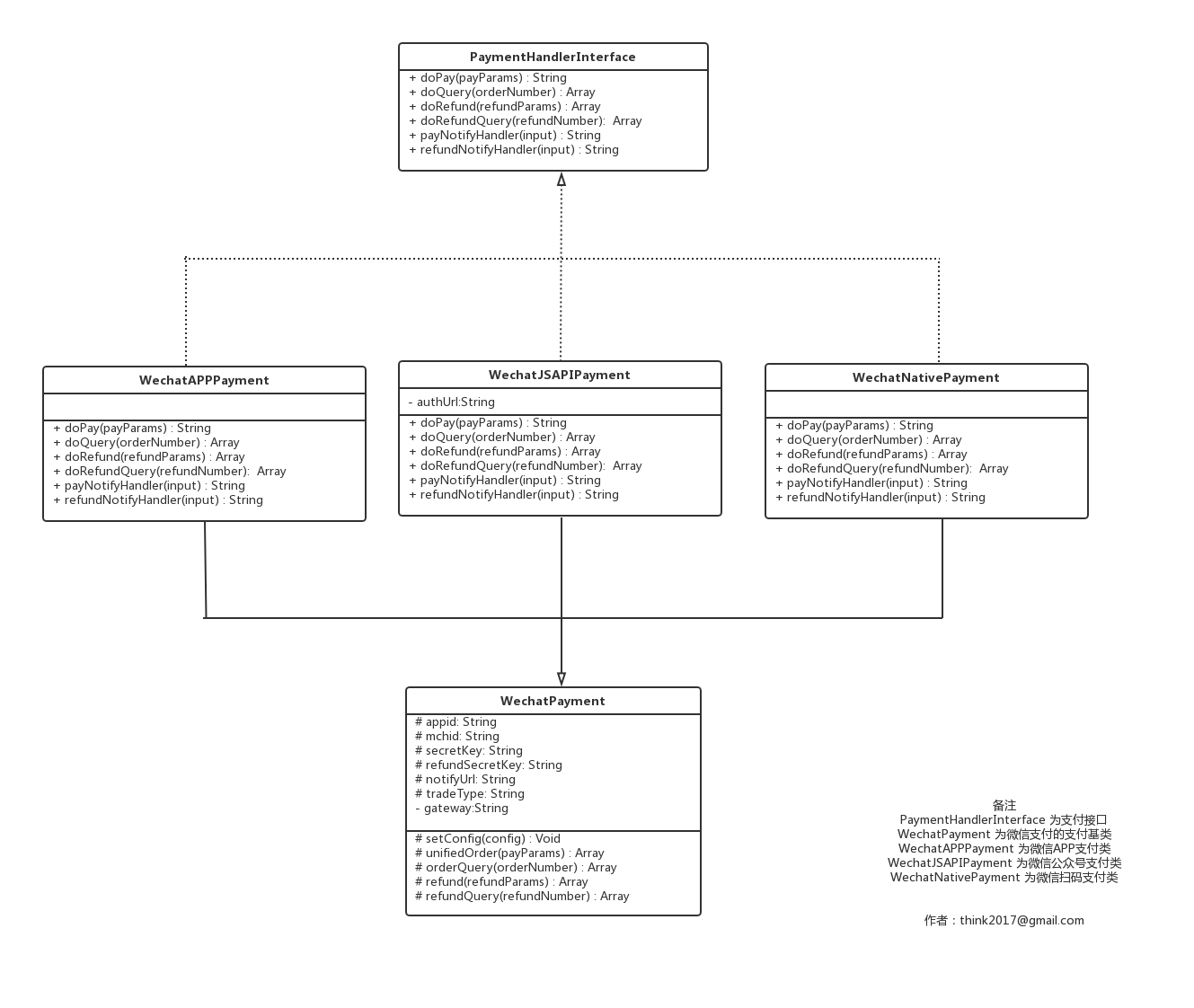
对上图做简要说明,PaymentHandlerInterface是所有支付类的接口,WechatPayment是所有微信支付类的基类,WechatAPPPayment、WechatJSAPIPayment、WechatNativePayment都是提供支付服务的支付类,都需要继承WechatPayment并实现PaymentHandlerInterface接口。同理,系统如果需要接入银联在线支付,那么就需要按照开发文档实现一个ChinaPayPayment做为银联在线支付的基类,然后分别开发出具体支付场景的支付类,比如ChinaPayAPPPayment(银联app支付)、ChinaPayWAPPayment(银联wap支付)、ChinaPayPCPayment(银联pc支付),这三个支付类需要继承ChinaPayPayment并实现PaymentHandlerInterface接口。
数据库
数据库设计
无限级数据库设计
采用邻接表的设计方式
1 | create table user( |
查询一个节点的所有后代
方式一:定义 SQL 函数递归查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE FUNCTION `getChildList`(rootId INT)
RETURNS VARCHAR(1000)
BEGIN
DECLARE idList VARCHAR(1000);
DECLARE idTemp VARCHAR(1000);
SET idTemp = CAST(rootId AS CHAR);
WHILE idTemp IS NOT NULL DO
IF (idList IS NOT NULL) THEN
SET idList = CONCAT(idList,',',idTemp);
ELSE
SET idList = CONCAT(idTemp);
END IF;
SELECT GROUP_CONCAT(id) INTO idTemp FROM `user` WHERE FIND_IN_SET(parentid,idTemp)>0;
END WHILE;
RETURN idList;
END;注意:
group_concat 是有长度限制的,超过限制时会导致数据不全。
方式二:使用共用表表达式递归查询(8.0 的版本才支持 WITH)
1
2
3
4
5
6
7WITH RECURSIVE cte(id, parentid, username, `level`) AS (
SELECT id, parentid, username, 0 AS `level` FROM `user` WHERE parentid = 4
UNION ALL
SELECT u.id, u.parentid, u.username, ce.`level` + 1 FROM `user` AS u
INNER JOIN cte AS ce
ON u.parentid = ce.id
)SELECT * FROM cte;查询一个节点的祖先节点
方式一:定义 SQL 函数递归查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE FUNCTION `getParentList`(rootId INT)
RETURNS varchar(1000)
BEGIN
DECLARE idList varchar(1000);
DECLARE idTemp varchar(1000);
SET idTemp = CAST(rootId as CHAR);
WHILE idTemp is not null DO
IF (idList is not null) THEN
SET idList = concat(idTemp,',',idList);
ELSE
SET idList = concat(idTemp);
END IF;
SELECT group_concat(parentid) INTO idTemp FROM user_role where FIND_IN_SET(id,idTemp)>0;
END WHILE;
RETURN idList;
END;方式二:使用共用表表达式递归查询(8.0 的版本才支持 WITH)
1
2
3
4
5
6
7WITH RECURSIVE RECURSIVE cte(id, parentid, username, `level`) AS (
SELECT id, parentid, username, 0 AS `level` FROM `user` WHERE id = 6
UNION ALL
SELECT u.id, u.parentid, u.username, ce.`level` - 1 FROM `user` AS u
INNER JOIN COMMENT_CTE AS ce
ON ce.parentid = u.id where ce.id <> ce.parentid
)SELECT * FROM cte;
路径枚举
路径枚举是一个由连续的直接层级关系组成的完整路径。如”1/4/7”,其中 1 是 4 的直接父亲,这也就意味着 1 是 7 的祖先。
1 | create table user( |
查询一个节点的所有后代
1
SELECT * FROM `user` AS u WHERE u.path LIKE '1/%';
查询一个节点的祖先节点
1
SELECT * FROM `user` AS u WHERE '1/3/5/7/' LIKE u.path + '%';
路径枚举的缺点:
1、数据库不能确保路径的格式总是正确或者路径中的节点确实存在(中间节点被删除的情况,没外键约束)。
2、要依赖高级程序来维护路径中的字符串,并且验证字符串的正确性的开销很大。
3、VARCHAR的长度很难确定。无论VARCHAR的长度设为多大,都存在不能够无限扩展的情况。
路径枚举的优点:
1、 查询父子节点的 SQL 语句简单
2、 能够很方便地根据节点的层级排序,因为通过比较字符串长度就能知道层级的深浅
嵌套集
嵌套集解决方案是存储子孙节点的信息,而不是节点的直接祖先。我们使用两个数字来编码每个节点,表示这个信息。可以将这两个数字称为nsleft和nsright。这些数字和 当前节点的主键ID 的值并没有任何关联。
nsleft值的确定:nsleft 的数值小于该节点所有后代的nsleft和nsright。
nsright值的确定:nsright 的值大于该节点所有后代的nsleft和nsright。
也就是当前节点的(nsleft,nsright)要包含其所有子孙节点的(nsleft,nsright)
确定值的方式是对树进行一次深度优先遍历,在逐层深入的过程中依次递增地分配nsleft的值,并在返回时依次递增地分配nsright的值。
查询一个节点的所有后代
1
SELECT u2.* FROM `user` AS u1 JOIN `user` AS u2 ON u2.neleft BETWEEN u1.nsleft AND u1.nsright WHERE u1.id = 1;
查询一个节点的祖先节点
1
SELECT u2.* FROM `user` AS u1 JOIN `user` AS u2 ON u1.nsleft BETWEEN u2.nsleft AND u2.nsright WHERE u1.id = 7;
嵌套集的优点:
1、 查询父子节点的 SQL 语句简单
2、 当删除一个节点造成数值不连续时,并不会对树的结构产生任何影响。
嵌套集的缺点:
1、插入操作比较麻烦
闭包表
闭包表是解决分层存储一个简单而又优雅的解决方案,它记录了表中所有的节点关系,并不仅仅是直接的父子关系。在闭包表的设计中,额外创建了一张tree_paths的表(空间换取时间),它包含祖先,后代两列。
可以优化闭包表来使它更方便地查询直接父亲节点或者子节点: 在 tree_paths 表中添加一个 path_length 字段。一个节点的自我引用的path_length 为0,到它直接子节点的path_length 为1,再下一层为2,以此类推。
1 | create table tree_paths ( |
查询一个节点的所有后代
1
SELECT u.* FROM `user` AS u INNER JOIN tree_paths t on c.id = t.descendant WHERE t.ancestor = 4;
查询一个节点的祖先节点
1
SELECT u.* FROM `user` AS u INNER JOIN tree_paths t on c.id = t.ancestor WHERE t.descendant = 4;
插入新节点
要插入一个新的叶子节点,比如 6 的一个子节点,应首先插入一条自己到自己的关系,然后搜索 tree_paths 表中后代是 6 的节点,增加这些节点和新插入节点的“祖先一后代”关系(假设新节点 ID 为8)。
1
INSERT INTO tree_paths (ancestor, descendant) SELECT t.ancestor, 8 FROM tree_paths AS t WHERE t.descendant = 6 UNION ALL SELECT 8, 8;
要删除一颗完整的子树,比如 4 和它所有的后代,可删除所有在 tree_paths 表中后代为 4 的行,以及那些以4 的后代为后代的行。
总结
| 设计 | 表数量 | 查询子 | 查询树 | 插入 | 删除 | 引用完整性 |
|---|---|---|---|---|---|---|
| 邻接表 | 1 | 简单 | 简单 | 简单 | 简单 | 是 |
| 枚举路径 | 1 | 简单 | 简单 | 简单 | 简单 | 否 |
| 嵌套集 | 1 | 困难 | 简单 | 困难 | 困难 | 否 |
| 闭包表 | 2 | 简单 | 简单 | 简单 | 简单 | 是 |
1、邻接表是最方便的设计,并且很多软件开发者都了解它。并且在递归查询的帮助下,使得邻接表的查询更加高效。
2、枚举路径能够很直观地展示出祖先到后代之间的路径,但由于不能确保引用完整性,使得这个设计比较脆弱。枚举路径也使得数据的存储变得冗余。
3、嵌套集是一个聪明的解决方案,但不能确保引用完整性,并且只能使用于查询性能要求较高,而其他要求一般的场合使用它。
4、闭包表是最通用的设计,并且最灵活,易扩展,并且一个节点能属于多棵树,能减少冗余的计算时间。但它要求一张额外的表来存储关系,是一个空间换取时间的方案。
MySQL中派生表、临时表、公共表、子查询的区别
公用表表达式CTE(Common Table Expression)是一个命名的临时结果集,仅在单个SQL语句(例如SELECT,INSERT,UPDATE或DELETE)的执行范围内存在。
1
2
3
4
5
6
7
8
9
10
11
12
13WITH customers_in_usa AS (
SELECT
customerName, state
FROM
customers
WHERE
country = 'USA'
) SELECT
customerName
FROM
customers_in_usa
WHERE
state = 'CA';派生表是从SELECT语句返回的虚拟表。与子查询不同,派生表必须具有别名,以便稍后在查询中引用其名称。
1
2
3
4
5
6
7
8
9SELECT
customerName
FROM
(SELECT
customerName, state
FROM
user
WHERE country = 'USA') customers_in_usa
WHERE state = 'CA';临时表是一种特殊类型的表,它允许您存储一个临时结果集,可以在单个会话中多次重用。
1
2
3
4
5
6
7
8CREATE TEMPORARY TABLE customers_in_usa
SELECT
customerName, state
FROM
user
WHERE country = 'USA';
DROP TEMPORARY TABLE customers_in_usa;子查询是嵌套在另一个查询(如SELECT,INSERT,UPDATE或DELETE)中的查询。
1
2
3
4
5
6
7
8
9
10SELECT
customerName
FROM
customers
WHERE state = 'CA' AND id IN (
SELECT
id
FROM
customers
WHERE country = 'USA');
执行计划
什么是数据库执行计划
执行计划,简单的来说,是SQL语句在数据库中执行时的表现情况,即数据库是如何执行SQL语句的。通常用于SQL性能分析、优化等场景。在MySQL使用 explain 关键字来查看SQL的执行计划。
字段含义
Table 8.1 EXPLAIN Output Columns
| Column | Meaning |
|---|---|
id |
查询顺序 |
select_type |
查询类型,用于区分普通查询、联合查询、子查询等复杂的查询 |
table |
查询的表 |
partitions |
使用的哪个分区,需要结合表分区才能看到 |
type |
访问类型 |
possible_keys |
可能用到的索引,如果是多个索引以逗号隔开 |
key |
实际用到的索引,保存的是索引的名称,如果是多个索引以逗号隔开 |
key_len |
索引长度,表示索引所使用的字节数 |
ref |
和索引做比较的列,全表扫描的话,值为null |
rows |
扫描行数 |
filtered |
满足条件的记录数占总记录数的百分比。 |
Extra |
额外信息 |
id
id越大优先级越高,越先被执行。id相同时,从上至下顺序执行。
select_type
| select_type | description | |
|---|---|---|
| 1 | SIMPLE | 简单查询,不使用union或子查询等 |
| 2 | PRIMARY | 包含任何复杂的子部分时,最外层查询就显示为 PRIMARY |
| 3 | SUBQUERY | 在select或 where字句中包含的子查询 |
| 4 | DERIVED | from字句中包含的查询,derived:衍生,派生 |
| 5 | UNION | 若第二个SELECT出现在UNION之后,则被标记为UNION; 若UNION包含在 FROM子句的子查询中,外层SELECT将被标记为:DERIVED |
| 6 | UNION RESULT | 从UNION表获取结果的SELECT被标记为:UNION RESULT |
type
访问类型,SQL查询优化中一个很重要的指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
| type | description | |
|---|---|---|
| 1 | ALL | 全表扫描 |
| 2 | index | 使用扫描,index与ALL区别为index类型只遍历索引树 |
| 3 | range | 索引范围扫描 常见于between、<、>,IN等的查询 |
| 4 | ref | 非唯一索引扫描 |
| 5 | eq_ref | 唯一索引扫描 通常出现在多表的 join 查询 表示对于前表的每一个结果, 都只能匹配到后表的一行结果 |
| 6 | const | 使用主键或者唯一索引,匹配的结果只有一条记录。 |
| 7 | system | 表中只有一行记录(等于系统表),这是const类型的特例 |
| 8 | NULL | 不用访问表或者索引就可以直接得到结果 |
eq_ref
此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高:
1 | select * from t3,t4 where t3.id=t4.accountid; |
Extra
这个列可以显示的信息非常多,有几十种,常用的有:
- Using index 使用覆盖索引
- Using where 使用了where子句来过滤结果集
- Using filesort 使用文件排序,排序时无法使用到索引时,就会出现这个。MySQL无法利用索引完成的顺序操作称为“文件排序”。常见于order by和group by语句中 。
- Using temporary 使用了临时表,一般出现于排序, 分组和多表join的情况, 查询效率不高, 建议优化.
总结
对查询性能影响最大的几个列是:
- select_type:查询类型
- type:连接使用了何种类型
- rows:查询数据需要查询的行
- key:查询真正使用到的索引
- extra:额外的信息
尽量让自己的SQL用上索引,避免让extra里面出现file sort(文件排序),using temporary(使用临时表)。
实例
对索引列进行了运算,无法使用索引。由于MySQL不像Oracle那样支持函数索引,即使函数内字段有索引,也会直接全表扫描。
1
2
3SELECT ID FROM SENDLOG WHERE TO_DAYS(NOW())-TO_DAYS(GMT_CREATE) > 7;
-- 优化后sql:
select id from sendlog where gmt_create < now() - 7;数据类型不一致,导致没法用索引
1
2
3SELECT * FROM SENDLOG where result = 1;
-- 优化后sql:
SELECT * FROM SENDLOG where result = '1';
索引
索引建立原则
最左匹配原则
在组合索引中,b+树的数据项是复合的数据结构,比如(name,age,sex),b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了。
经常需要排序、分组和联合操作的字段需要建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,需要建立索引。
选择区分度高的列作为索引
区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少
面试问题
为什么加索引能够优化查询速度?
因为索引的本质就是一种优化查询速度的数据结构,MySQL中使用B+树实现。
MySQL为什么使用B+树来实现索引?
常见的能够提高查询速度的数据结构有:哈希表,完全平衡二叉树,B树,B+树。
哈希表对于范围查找的情况不理想,而对于树的情况,由于树的高度越低,所需要的磁盘IO次数就越少,故B+树性能更好,而且对于范围查找也适用。
对于B+树,一个节点所含元素的个数一般是操作系统中一页的大小的倍数。一般一页的大小为4kb,MySQL InnoDB的页大小为16kb
为什么不建议写 select *,结合索引给出优化案例
B+树非叶子节点只存索引值,叶子节点既存索引值也存数据值。当需要查找的字段添加了索引后,查找到索引后即可得到其数据值,不用再查找对应的记录来获取数据值了。
第一,如果仅仅需要获取一个字段值,并且这个值有索引,比如用户的Id主键索引,就不需要查询两次表,直接获取就行了。
第二,对于不必要的字段,比如文章内容这种占用空间比较大的字段会占用较大的网络带宽。
如何清空一张一百万级数据表里的一个字段?
使用主键索引分批执行。
如何对一张一百万级数据表进行快速分页查询?
利用覆盖索引,查询的语句中只包含索引列
1
SELECT * FROM product WHERE id >= (select id from product limit 866613, 1) limit 20
事务
什么是事务
事务是数据库中的一个单独的执行单元。是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。
事务的四大特性 ACID
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务执行前后,数据库系统保持一致性状态。即系统从一个一致的状态转换到另一个一致状态。
一致性是指数据处于一种语义上的有意义且正确的状态。一致性是对数据可见性的约束,保证在一个事务中的多次操作的数据中间状态对其他事务是不可见的。
原子性和一致性的的侧重点不同:原子性关注状态,要么全部成功,要么全部失败,不存在部分成功的状态。而一致性关注数据的可见性,中间状态的数据对外部不可见,只有最初状态和最终状态的数据对外可见。
在未提交读的隔离级别下,会造成脏读,这就是因为一个事务读到了另一个事务操作内部的数据。ACID中的一致性描述的是一个最理想的事务应该是怎样的,是一个强一致性状态,如果要做到这点,需要使用排它锁把事务排成一队,即 Serializable 的隔离级别,这样性能就大大降低了。现实是骨感的,所以使用不同隔离级别来破坏一致性,以获取更好的性能。
隔离性(Isolation)
多个事务并发访问时,事务之间是隔离的,一个事务不影响其它事务的执行。
持久性(Durability)
事务一旦提交,对数据库数据的修改便是永久性的。即使系统或介质发生故障时,其修改也将持久化保存在数据库中。
事务的并发问题
赃读(Dirty Read)
一个事务读取到了另外一个事务没有提交的数据。
不可重复读(Nonrepeatable Read)
在同一事务中,两次读取同一数据,得到不同内容。
幻读(Phantom Read)
同一事务中,用同样的操作读取两次,得到的记录数不相同。
丢失更新(Lost Update)
- 第一类丢失更新: A事务撤销时, 把已经提交的B事务的更新数据覆盖了。
- 第二类丢失更新: A事务覆盖B事务已经提交的数据,造成B事务所做跟新丢失。
不可重复读的重点是修改,幻读的重点在于新增或者删除。
不可重复读主要是说多次读取一条记录, 发现该记录中某些列值被修改过。
幻读主要是说多次读取一个范围内的记录(包括直接查询所有记录结果或者做聚合统计), 发现结果不一致(标准档案一般指记录增多, 记录的减少应该也算是幻读)。(可以参考MySQL官方文档对 Phantom Rows 的介绍)
事务的隔离级别
READ_UNCOMMITTED(读未提交)
读事务不阻塞其他读事务和写事务,未提交的写事务阻塞其他写事务但不阻塞读事务。
可以防止更新丢失,但不能防止脏读、不可重复读、幻读。
可以通过“排他写锁”实现。
READ_COMMITTED (读已提交)
- 读事务不阻塞其他读事务和写事务,未提交的写事务阻塞其他读事务和写事务。
- 可以防止更新丢失、脏读,但不能防止不可重复读、幻读。
- 可以通过“瞬间共享读锁”和“排他写锁”实现。
REPEATABLE_READ(可重复读)
- 以操作同一行数据为前提,读事务阻塞其他写事务但不阻塞读事务,未提交的写事务阻塞其他读事务和写事务。
- 可以防止更新丢失、脏读、不可重复读,但不能防止幻读。
- 可以通过“共享读锁”和“排他写锁”实现。
SERIALIZABLE(可序列化)
- 事务序列化执行,只能一个接着一个地执行,不能并发执行。
- 可以防止更新丢失、脏读、不可重复读、幻读。
- 如果仅仅通过“行级锁”是无法实现事务序列化的,需使用“表级锁”。
事务隔离级别 回滚覆盖 脏读 不可重复读 提交覆盖 幻读 读未提交 x 可能发生 可能发生 可能发生 可能发生 读已提交 x x 可能发生 可能发生 可能发生 可重复读 x x x x 可能发生 串行化 x x x x x 隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读,而且具有较好的并发性能。尽管它会导致不可重复读、幻读和第二类丢失更新这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。
MySQL 默认的事务隔离级别为 REPEATABLE_READ
Spring声明式事务管理
Spring五个事务隔离级别
| 隔离级别 | 说明 |
|---|---|
| ISOLATION_DEFAULT | 使用数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别,Oracle 默认采用的 READ_COMMITTED隔离级别。 |
| ISOLATION_READ_UNCOMMITTED | 读未提交 |
| ISOLATION_READ_COMMITTED | 读已提交 |
| ISOLATION_REPEATABLE_READ | 可重复度 |
| ISOLATION_SERIALIZABLE | 序列化 |
Spring七个事务传播行为
| 事务传播行为类型 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 |
事务传播行为定义的是事务的控制范围,事务隔离级别定义的是事务在数据库读写方面的控制范围。
超时时间
TransactionDefinition 接口中定义了1个表示超时时间的常量TIMEOUT_DEFAULT 默认是30秒,使用getTimeout()方法可以获取到超时时间,单位是秒。Spring事务超时时间,是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。
是否只读
事务管理的只读属性是指对事务性资源进行只读操作或者是可读写操作。所谓事务性资源就是指那些被事务管理的资源,如数据源、JMS 资源,以及自定义的事务性资源等。如果确定只对事务性资源进行只读操作,那么我们可以将事务标志为只读的,以提高事务处理的性能。在TransactionDefinition 中以 boolean 类型来表示该事务是否只读,使用方法isReadOnly()来判断事务是否是只读的。
回滚规则
通常情况下,如果在事务中抛出了未检查异常(继承自 RuntimeException 的异常),则默认将回滚事务。如果没有抛出任何异常,或者抛出了已检查异常,则正常提交事务。我们可以根据需要人为控制事务在抛出某些未检查异常时仍然提交事务,或者在抛出某些已检查异常时回滚事务。
Transactional注解中有4个属性通过设置系统异常类和自定义异常类来自定义回滚规则。
- @Transactional(rollbackFor=RuntimeException.class)
用于设置需要进行回滚的异常类数组,当方法中抛出指定异常数组中的异常时,则事务回滚。 - @Transactional(rollbackForClassName=”RuntimeException”)
用于设置需要进行回滚的异常类名称数组,当方法中抛出指定异常名称数组中的异常时,则进行事务回滚 - @Transactional(noRollbackFor=RuntimeException.class)
用于设置不需要进行回滚的异常类数组,当方法中抛出指定异常数组中的异常时,不进行事务回滚 - @Transactional(noRollbackForClassName=RuntimeException.class)
用于设置不需要进行回滚的异常类名称数组,当方法中抛出指定异常名称数组中的异常时,不进行事务回滚
其他
@Transactional 只能被应用到public方法上, 对于其它非public的方法,如果标记了@Transactional也不会报错,但方法没有事务功能
可以在接口上使用 @Transactional 注解,但是只有当你设置了基于接口的代理时它才生效。因为注解是不能继承的。
当你在Spring中配置了
<aop:aspectj-autoproxy></aop:aspectj-autoproxy>时,那么代理类就是基于接口的代理。当你在Spring中配置了
<aop:aspectj-autoproxy proxy-target-class="true"/>时,那么代理类就是基于类的代理。事务传播机制只适用于不同bean之间方法的调用,如果一个bean中的两个方法互相调用并不会使用到事务传播。
原因解释:spring的事物管理通过AOP代理来实现, 根据aop的思想,不可能在具体类上直接处理事务,而是通过代理类来处理,代理类在调用具体类的方法来实现,methodA通过this调用methodB,那么此时相当于调用methodB时是没有经过代理类的调用,因此spring无法对事物的传播行为做处理。
@Transactional 失效的情况
@Transactional 只能应用到 public 方法才有效
在 Spring 的 AOP 代理下,只有目标方法由外部调用,目标方法才由 Spring 生成的代理对象来管理,这会造成自调用问题:
若同一类中的其他没有@Transactional 注解的方法内部调用有@Transactional 注解的方法,有@Transactional 注解的方法的事务被忽略。
数据库的锁机制
分类
按锁类型划分,可分为共享锁、排他锁
按锁的粒度划分,可分为表级锁、行级锁、页级锁
按使用机制划分,可分为乐观锁、悲观锁
共享锁与排他锁
共享锁(Shared locks, S-locks)
也叫读锁、S锁。在没有检测到排他锁时才可以加共享锁,其他事务可以并发读取该数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。
用法:SELECT ... LOCK IN SHARE MODE;
排他锁(Exclusive locks, X-locks)
也叫写锁、X锁。在没有加任何锁时才可以加排他锁,加上排他锁后,其他事务不能再加任何类型的锁,直到已释放该排他锁。
用法:SELECT ... FOR UPDATE;
InnoDB还有两个表锁:
意向共享锁(IS):表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):表示事务准备给数据行加入排他锁,事务在一个数据行加排他锁前必须先取得该表的IX锁。
意向锁是InnoDB自动加的,不需要用户干预。
级锁、行级锁、页级锁
表级锁:直接锁定整张表,在锁定期间,其他进程无法对该表进行写操作。如果你是写锁,则其他进程读也不允许。特点是:开销小、加锁快,不会出现死锁。锁定粒度最大,发生锁冲突的概率最高,并发度最低。
MYISAM存储引擎采用的就是表级锁。
行级锁:仅对指定的记录进行加锁,这样其他进程还是可以对同一个表中的其他记录进行操作。特点:开销大,加锁慢,会出现死锁。锁定的粒度最小,发生锁冲突的概率最低,并发度也最高。
InnoDB存储引擎既支持行级锁,也支持表级锁,但默认情况下是采用行级锁。
页级锁:一次锁定相邻的一组记录。开销和加锁时间介于表级锁和行级锁之间;会出现死锁;锁定粒度也介于表级锁和行级锁之间,并发度一般。
乐观锁、悲观锁
无论是悲观锁还是乐观锁,都是人们定义出来的概念,可以认为是一种思想。不要把乐观并发控制和悲观并发控制狭义的理解为DBMS中的概念,更不要把他们和数据中提供的锁机制(行锁、表锁、排他锁、共享锁)混为一谈。其实,在DBMS中,悲观锁正是利用数据库本身提供的锁机制来实现的。
悲观并发控制(又名“悲观锁”,Pessimistic Concurrency Control,缩写“PCC”)是一种并发控制的方法。锁如其名,它指的是对数据被外界修改持悲观态度,即假定当前事务操纵数据资源时,肯定还会有其他事务同时访问该数据资源。因此,为了避免当前事务的操作受到干扰,先锁定资源。悲观锁需使用数据库的锁机制实现,如使用行级排他锁或表级排它锁。
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,增加产生死锁的机会;另外,在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还会降低了并行性。
乐观并发控制(又名“乐观锁”,Optimistic Concurrency Control,缩写“OCC”)是一种并发控制的方法。它对数据被外界修改持乐观态度,即假定当前事务操纵数据资源时,不会有其他事务同时访问该数据资源,因此不在数据库层次上锁定,乐观锁使用由程序逻辑控制的技术来避免可能出现的并发问题。
乐观锁的实现方式有两种,第一种是使用版本号,第二种是使用时间戳。
基于数据版本记录机制的实现:即每行数据多一个版本字段,当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,将数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
使用时间戳的实现:依然是为每条数据增加一个时间戳字段,在更新提交的时候,将当前数据库中数据的时间戳与第一次读取的时间戳进行比对,如果一致则更新,否则认为是过期数据。
乐观锁不能解决脏读的问题,因此仍需要数据库至少启用“读已提交”的事务隔离级别。
MVCC
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多写少的应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,这也是为什么现阶段,几乎所有的RDBMS,都支持了MVCC。
在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
在一个支持MVCC并发控制的系统中,哪些读操作是快照读?哪些操作又是当前读呢?以MySQL InnoDB为例:
快照读:简单的select操作,属于快照读,不加锁。
select * from table where ?;
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
1 | select * from table where ? lock in share mode; |
除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)。
三级加锁协议、两段锁协议
三级加锁协议也称为三级封锁协议,是为了保证正确的调度事务的并发操作,事务在对数据库对象加锁、解锁时必须遵守的一种规则。在运用X锁和S锁对数据对象加锁时,还需要约定一些规则 ,例如何时申请X锁或S锁、持锁时间、何时释放等。称这些规则为封锁协议(Locking Protocol)。对封锁方式规定不同的规则,就形成了各种不同的封锁协议。
一级封锁协议
事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
一级封锁协议可以防止丢失修改,并保证事务T是可恢复的。使用一级封锁协议可以解决丢失修改问题。
在一级封锁协议中,如果仅仅是读数据不对其进行修改,是不需要加锁的,它不能保证可重复读和不读“脏”数据。
二级封锁协议
一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后方可释放S锁。
二级封锁协议除防止了丢失修改,还可以进一步防止读“脏”数据。但在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
三级封锁协议
一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
三级封锁协议除防止了丢失修改和不读“脏”数据外,还进一步防止了不可重复读。
上述三级协议的主要区别在于什么操作需要申请封锁,以及何时释放。
两段锁协议
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。
两段锁协议规定在对任何数据进行读写操作之前,事务首先要获得对该数据的封锁;而且在释放一个封锁之后,事务不再获得任何其他封锁。就是说加锁和解锁分为两个阶段进行。
事务遵循两段锁协议是保证可串行化调度的充分条件。例如以下操作满足两段锁协议,它是可串行化调度。
Xlock(A)…Slock(B)…Slock(C)…unlock(A)…unlock(C)…unlock(B)
但不是必要条件,例如以下操作不满足两段锁协议,但是它还是可串行化调度:
Xlock(A)…unlock(A)…Slock(B)…unlock(B)…Slock(C)…unlock(C)
| 事务隔离级别 | 加锁协议 |
|---|---|
| 读未提交 | 一级加锁协议 |
| 读已提交 | 二级加锁协议 |
| 可重复读 | 三级加锁协议 |
| 串行化 | 两段锁协议 |
注:封锁协议和隔离级别并不是严格对应的。
MySQL 的 InnoDB 存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。
死锁
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
避免死锁
(1) 按同一顺序访问对象。(注:避免出现循环)
(2) 避免事务中的用户交互。(注:减少持有资源的时间,较少锁竞争)
(3) 保持事务简短并处于一个批处理中。(注:减少持有资源的时间)
(4) 使用较低的隔离级别。(注:使用较低的隔离级别比使用较高的隔离级别持有共享锁的时间更短)
(5) 使用基于行版本控制的隔离级别。
(6) 使用绑定连接。
多线程
定义
线程和进程一样分为五个阶段(状态):创建、就绪、运行、阻塞、终止。
多进程是指操作系统能同时运行多个任务(程序)。
多线程是指在同一程序中有多个顺序流在执行。
名词解释
- 主线程:JVM调用程序main()所产生的线程。
- 当前线程:这个是容易混淆的概念。一般指通过Thread.currentThread()来获取的进程。
- 后台线程:指为其他线程提供服务的线程,也称为守护线程。JVM的垃圾回收线程就是一个后台线程。用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束
- 前台线程:是指接受后台线程服务的线程,其实前台后台线程是联系在一起,就像傀儡和幕后操纵者一样的关系。傀儡是前台线程、幕后操纵者是后台线程。由前台线程创建的线程默认也是前台线程。可以通过isDaemon()和setDaemon()方法来判断和设置一个线程是否为后台线程。
多线程的实现方式
在 java 中要想实现多线程,一般有 3 种手段:继承 Thread 类、实现 Runnable 接口和实现 Callable 接口。
推荐使用 Runnable 方式的原因:
- 可以避免 java 单继承的限制
- 线程池只能放入实现 Runable 或 callable 类线程,不能直接放入继承 Thread 的类
注意:
start() 方法调用后并不是立即执行多线程代码,而是使得该线程变为可运行态(Runnable),什么时候运行是由操作系统决定的。
start 方法重复调用的话,会出现java.lang.IllegalThreadStateException异常。
启动线程的唯一方法就是通过 Thread 类的 start() 方法,所有的多线程代码都是通过运行Thread的start()方法来运行的。
Thread 类实际上也是实现了 Runnable 接口的类。
main 方法其实也是一个线程,是程序的主线程。
在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程。因为每当使用java命令执行一个类的时候,实际上都会启动一个JVM,每一个JVM实际上就是在操作系统中启动了一个进程。
多线程同步的实现方式
Java 中提供了 3 中实现同步机制的方法:
synchronized 关键字
Java 中每个对象都有一个对象锁与之相关联。
synchronized 关键字主要有两种用法:同步方法和同步代码块。此外,该关键字还可以作用于静态方法,类或者某个实例
wait 与 notify 方法
在 synchronized 代码被执行期间,线程可以调用对象的 wait 方法,释放对象锁,进入等待状态,并且可以调用 notify 方法或者 notifyAll 方法通知正在等待的其他线程。
Lock 接口
JDK 5 增加了 Lock 接口以及它的一个实现类 ReentrantLock(重入锁),提供了一系列方法来实现多线程的同步。
lock()
以阻塞的方式获取锁,也就是说,如果获取到了锁,立即放回;如果别的线程持有锁,当前线程等待,知道获取锁后返回。
unlock()
释放锁。
tryLock()
以非阻塞的方式获取锁。只是尝试性地去获取一下锁,如果获取到锁,立即返回 true,否则,立即返回 false。
tryLock(long tieout, TimeUnit unit)
如果获取了锁,立即返回 true,否则会等待参数给定的时间单元,在等待的过程中,如果获取了锁,就返回 true,如果等待超时,返回 false。
lockInterruptibly()
如果获取了锁,立即返回;如果没有获取到锁,当前线程处于休眠状态,知道获取锁,或者当前线程被别的线程中断(会收到 InterruptedException 异常)。它与 lock() 方法最大的区别在于如果 lock() 方法获取不到锁,会一直处于阻塞状态,且会忽略 interrupt() 方法。
synchronized 与 Lock 的区别
| 类别 | synchronized | Lock |
|---|---|---|
| 存在层次 | Java的关键字 托管给JVM执行,故为隐士锁 |
是一个接口 代码控制,故为显示锁 |
| 锁的获取 | 阻塞式获取 假设A线程获得锁,B线程等待。 如果A线程阻塞,B线程会一直等待 |
可非阻塞式获取 Lock有多个锁获取的方式 可以尝试获得锁,线程可以不用一直等待 |
| 锁的释放 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常时,jvm会让线程释放锁 |
在finally中必须释放锁,不然容易造成线程死锁 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可重入 不可中断 非公平 |
可重入 可中断 可公平可非公平 |
| 性能 | 少量同步时性能较高 | 大量同步时性能高 |
锁类型
| 类型 | 说明 |
|---|---|
| 可重入锁 | 广义上的可重入锁指的是可重复可递归调用的锁, 在外层使用锁之后,在内层仍然可以使用,并且不发生死锁 (前提得是同一个对象或者class),这样的锁就叫做可重入锁。 究竟什么是可重入锁? |
| 可中断锁 | 在等待获取锁过程中可中断 |
| 公平锁 | 按等待获取锁的线程的等待时间进行获取, 等待时间长的具有优先获取锁权利 |
| 读写锁 | 对资源读取和写入的时候拆分为2部分处理, 读的时候可以多线程一起读,写的时候必须同步地写 |
synchronized 在JavaSE1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。
当竞争不是很激烈的时候Synchronized使用的是轻量级锁或者偏向锁,这两种锁都能有效减少轮询或者阻塞的发生,相比与Lock仍旧要将未获得锁的线程放入等待队列阻塞带来的上下文切换的开销,此时Synchronized效率会高些,当竞争激烈的时候Synchronized会升级为重量级锁,由于Synchronized的出队速度相比Lock要慢,所以Lock的效率会更高些。一般对于数据结构设计或者框架的设计都倾向于使用Lock而非Synchronized。
Lock是基于AQS(AbstractQueuedSynchronizer)实现的,AQS的基础又是CAS。
AQS
AQS(AbstractQueuedSynchronizer 队列同步器),AQS是JDK下提供的一套用于实现基于FIFO等待队列的阻塞锁和相关的同步器的一个同步框架。它使用了一个int成员变量表示同步状态,使用 CAS 设置当前状态。CountDownLatch、FutureTask、Semaphore、ReentrantLock等都有一个内部类是这个抽象类的子类。AQS是JUC同步器的基石。
CAS
CAS(Compare And Swap 比较并交换)指的是现代 CPU 广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。这个指令会对内存中的共享数据做原子的读写操作。JVM中的CAS操作是利用了处理器提供的CMPXCHG指令实现的。简单介绍一下这个指令的操作过程:CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。首先,CPU 会将内存中将要被更改的数据与期望的值做比较。然后,当这两个值相等时,CPU 才会将内存中的数值替换为新的值。否则便不做操作。最后,CPU 会将旧的数值返回。这一系列的操作是原子的。它们虽然看似复杂,但却是 Java 5 并发机制优于原有锁机制的根本。简单来说,CAS 的含义是“我认为原有的值应该是什么,如果是,则将原有的值更新为新值,否则不做修改,并告诉我原来的值是多少”。(这段描述引自《Java并发编程实践》)
CAS的目的:利用CPU的CAS指令,同时借助JNI(Java Native Interface)来完成Java的非阻塞算法。其它原子操作都是利用类似的特性完成的。而整个J.U.C(java.util.concurrent)都是建立在CAS之上的,因此相对于synchronized阻塞算法,J.U.C在性能上有了很大的提升。
要实现无锁(lock-free)的非阻塞算法有多种实现方法,其中CAS(比较与交换,Compare and swap)是一种有名的无锁算法。CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
接下来通过源代码来看 AtomicInteger 具体是如何实现的原子操作。
首先看 value 的声明:
1
private volatile int value;
volatile 修饰的 value 变量,保证了变量的可见性。
incrementAndGet() 方法,下面是具体的代码:
1
2
3
4
5
6
7
8public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}通过源码,可以知道,这个方法的做法为先获取到当前的 value 属性值,然后将 value 加 1,赋值给一个局部的 next 变量,然而,这两步都是非线程安全的,但是内部有一个死循环,不断去做 compareAndSet 操作,直到成功为止,也就是修改的根本在 compareAndSet 方法里面,compareAndSet()方法的代码如下:
1
2
3public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}compareAndSet()方法调用的compareAndSwapInt()方法的声明如下,是一个native方法。
1
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, intvar5);
compareAndSet 传入的为执行方法时获取到的 value 属性值,next 为加 1 后的值, compareAndSet 所做的为调用 Sun 的 UnSafe 的 compareAndSwapInt 方法来完成,此方法为 native 方法,compareAndSwapInt 基于的是 CPU 的 CAS 指令来实现的。所以基于 CAS 的操作可认为是无阻塞的,一个线程的失败或挂起不会引起其它线程也失败或挂起。并且由于 CAS 操作是 CPU 原语,所以性能比较好。
类似的,还有 decrementAndGet() 方法。它和 incrementAndGet() 的区别是将 value 减 1,赋值给next 变量。
AtomicInteger 中还有 getAndIncrement() 和 getAndDecrement() 方法,他们的实现原理和上面的两个方法完全相同,区别是返回值不同,前两个方法返回的是改变之后的值,即 next。而这两个方法返回的是改变之前的值,即 current。还有很多的其他方法,就不列举了。
状态转换
- 新建状态(New):新创建了一个线程对象。
- 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待 OS 调度以获取CPU的使用权。
- 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
- 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
- 等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。(wait会释放持有的锁)
- 同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
- 其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。(注意,sleep是不会释放持有的锁)
- 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
线程调度
调整线程优先级:Java线程有优先级,优先级高的线程会获得较多的运行机会。
Java线程的优先级用整数表示,取值范围是1~10,Thread类有以下三个静态常量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14/**
* The minimum priority that a thread can have.
*/
public final static int MIN_PRIORITY = 1;
/**
* The default priority that is assigned to a thread.
*/
public final static int NORM_PRIORITY = 5;
/**
* The maximum priority that a thread can have.
*/
public final static int MAX_PRIORITY = 10;Thread类的setPriority()和getPriority()方法分别用来设置和获取线程的优先级。
每个线程都有默认的优先级。主线程的默认优先级为Thread.NORM_PRIORITY。
线程的优先级有继承关系,比如A线程中创建了B线程,那么B将和A具有相同的优先级。
JVM提供了10个线程优先级,但与常见的操作系统都不能很好的映射。如果希望程序能移植到各个操作系统中,应该仅仅使用Thread类中的三个静态常量作为优先级,这样能保证同样的优先级采用了同样的调度方式。线程睡眠:
Thread.sleep(long millis)方法,使线程转到阻塞状态。millis参数设定睡眠的时间,以毫秒为单位。当睡眠结束后,就转为就绪(Runnable)状态。sleep() 平台移植性好。线程等待:Object 类中的 wait() 方法,导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 唤醒方法。这个两个唤醒方法也是 Object 类中的方法,行为等价于调用 wait(0) 。
线程让步:
Thread.yield()方法,暂停当前正在执行的线程对象,把执行机会让给相同或者更高优先级的线程。线程加入:join()方法,等待其他线程终止。在当前线程中调用另一个线程的 join() 方法,则当前线程转入阻塞状态,直到另一个进程运行结束,当前线程再由阻塞转为就绪状态。
线程唤醒:Object 类中的 notify() 方法,唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权或劣势。类似的方法还有一个 notifyAll(),唤醒在此对象监视器上等待的所有线程。
终止线程的方法
stop() 方法
使用 Thread.stop() 方法(已废弃)来终止线程时,它会释放已经锁定的所有监视资源。这可能会导致程序执行的不确定性,并且这种问题很难定位。
使用退出标志终止线程
设一个boolean类型的推出标志 exit,并通过设置这个标志为true或false来控制while循环是否退出,并使用 volatile,这个关键字的目的是使exit同步,也就是说在同一时刻只能由一个线程来修改exit的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MyThread implements Runnable {
private volatile Boolean exit = false;
public void stop(){
exit = true;
}
public void run() {
while (!exit){
……
}
}
}注:虽然通过调用上例中的 stop 方法可以终止线程,但当线程处于非运行状态时,这种方式就不可用了。
使用 interrupt() 方法
当 interrupt 方法被调用时,会抛出 InterruptedException 异常,可以通过在 run() 方法中捕获这个异常来让线程安全退出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MyThread implements Runnable {
public void run() {
try {
……
if (Thread.interrupted()) {
throw new InterruptedException();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
线程池
Java通过Executors提供四种线程池,分别为:
newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
阿里巴巴Java开发手册中不允许通过Executors静态工厂构建,使用Executors创建线程池,由于底层使用的是阻塞队列 LinkedBlockingQueue,当创建的线程过多时,会导致OOM(OutOfMemory ,内存溢出),所以一般直接调用ThreadPoolExecutor构造一个就可以了。Java中线程池,你真的会用吗?
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。

如上图,最顶层的接口 Executor 仅声明了一个方法execute。ExecutorService 接口在其父类接口基础上,声明了包含但不限于shutdown、submit、invokeAll、invokeAny 等方法。至于 ScheduledExecutorService 接口,则是声明了一些和定时任务相关的方法,比如 schedule和scheduleAtFixedRate。线程池的核心实现是在 ThreadPoolExecutor 类中,我们使用 Executors 调用newFixedThreadPool、newSingleThreadExecutor和newCachedThreadPool等方法创建线程池均是 ThreadPoolExecutor 类型。
比较重要的几个类:
ExecutorService:
真正的线程池接口。
ScheduledExecutorService:
能和Timer/TimerTask类似,解决那些需要任务重复执行的问题。
ThreadPoolExecutor:
ExecutorService的默认实现。
ScheduledThreadPoolExecutor:
继承ThreadPoolExecutor的ScheduledExecutorService接口实现,周期性任务调度的实现类。
核心类 ThreadPoolExecutor
1 | public ThreadPoolExecutor(int corePoolSize, |
如上所示,核心构造方法的参数即核心参数。
| 参数 | 说明 |
|---|---|
| corePoolSize | 核心线程数。当线程数小于该值时,线程池会优先创建新线程来执行新任务 |
| maximumPoolSize | 线程池所能维护的最大线程数 |
| keepAliveTime | 空闲线程的存活时间 |
| unit | 参数keepAliveTime的时间单位,有7种取值,对应在TimeUnit类中有7种静态属性 天、小时、分钟、秒、毫秒、微妙、纳秒 |
| workQueue | 任务队列,用于缓存未执行的任务 |
| threadFactory | 线程工厂。可通过工厂为新建的线程设置更有意义的名字 |
| handler | 拒绝策略。当线程池和任务队列均处于饱和状态时,使用拒绝策略处理新任务。默认是 AbortPolicy,即直接抛出异常 |
线程创建规则
在 Java 线程池实现中,线程池所能创建的线程数量受限于 corePoolSize 和 maximumPoolSize 两个参数值。线程的创建时机则和 corePoolSize 以及 workQueue 两个参数有关。下面列举一下线程创建的4个规则(线程池中无空闲线程),如下:
| 序号 | 条件 | 动作 |
|---|---|---|
| 1 | 线程数 < corePoolSize | 创建新线程 |
| 2 | 线程数 ≥ corePoolSize,且 workQueue 未满 | 缓存新任务 |
| 3 | corePoolSize ≤ 线程数 < maximumPoolSize,且 workQueue 已满 | 创建新线程 |
| 4 | 线程数 ≥ maximumPoolSize,且 workQueue 已满 | 使用拒绝策略处理 |
资源回收
考虑到系统资源是有限的,对于线程池超出 corePoolSize 数量的空闲线程应进行回收操作。进行此操作存在一个问题,即回收时机。目前的实现方式是当线程空闲时间超过 keepAliveTime 后,进行回收。除了核心线程数之外的线程可以进行回收,核心线程内的空闲线程也可以进行回收。回收的前提是 allowCoreThreadTimeOut 属性被设置为 true,通过public void allowCoreThreadTimeOut(boolean) 方法来设置该属性。
排队策略
如线程创建规则2所说,当线程数量大于等于 corePoolSize,workQueue 未满时,则缓存新任务。这里要考虑使用什么类型的容器缓存新任务,通过 JDK 文档介绍,我们可知道有3中类型的容器可供使用,分别是同步队列,有界队列和无界队列。对于有优先级的任务,这里还可以增加优先级队列。以上所介绍的4中类型的队列,对应的实现类如下:
| 实现类 | 类型 | 说明 |
|---|---|---|
| SynchronousQueue | 同步队列 | 该队列不存储元素 每个插入操作必须等待另一个线程调用移除操作 否则插入操作会一直阻塞 |
| ArrayBlockingQueue | 有界队列 | 基于数组的阻塞队列,按照 FIFO 原则对元素进行排序 |
| LinkedBlockingQueue | 无界队列 | 基于链表的阻塞队列,按照 FIFO 原则对元素进行排序 |
| PriorityBlockingQueue | 优先级队列 | 具有优先级的阻塞队列 |
拒绝策略
当线程数量大于等于 maximumPoolSize,且 workQueue 已满,则使用拒绝策略处理新任务。Java 线程池提供了4 种拒绝策略实现类,如下:
| 实现类 | 说明 |
|---|---|
| AbortPolicy | 丢弃新任务,并抛出 RejectedExecutionException |
| DiscardPolicy | 不做任何操作,直接丢弃新任务 |
| DiscardOldestPolicy | 丢弃队列队首的元素,并执行新任务 |
| CallerRunsPolicy | 由调用线程执行新任务 |
以上4个拒绝策略中,AbortPolicy 是线程池实现类 ThreadPoolExecutor 所使用的策略。我们也可以通过方法public void setRejectedExecutionHandler(RejectedExecutionHandler)修改线程池拒绝策略。
线程的创建与复用
在线程池的实现上,线程的创建是通过线程工厂接口ThreadFactory的实现类来完成的。默认情况下,线程池使用Executors.defaultThreadFactory()方法返回的线程工厂实现类。当然,我们也可以通过
public void setThreadFactory(ThreadFactory)方法进行动态修改。具体细节这里就不多说了,并不复杂,大家可以自己去看下源码。
在线程池中,线程的复用是线程池的关键所在。这就要求线程在执行完一个任务后,不能立即退出。对应到具体实现上,工作线程在执行完一个任务后,会再次到任务队列获取新的任务。如果任务队列中没有任务,且 keepAliveTime 也未被设置,工作线程则会被一致阻塞下去。通过这种方式即可实现线程复用。
说完原理,再来看看线程的创建和复用的相关代码(基于 JDK 1.8),如下:
1 | +----ThreadPoolExecutor.Worker.java |
提交任务
通常情况下,我们可以通过线程池的submit方法提交任务。被提交的任务可能会立即执行,也可能会被缓存或者被拒绝。任务的处理流程如下图所示:

上面的流程图不是很复杂,下面再来看看流程图对应的代码,如下:
1 | +---- AbstractExecutorService.java |
线程池的状态
这些状态都和线程的执行密切相关:

RUNNING自然是运行状态,指可以接受任务执行队列里的任务SHUTDOWN指调用了shutdown()方法,不再接受新任务了,但是队列里的任务得执行完毕。STOP指调用了shutdownNow()方法,不再接受新任务,同时抛弃阻塞队列里的所有任务并中断所有正在执行任务。TIDYING所有任务都执行完毕,在调用shutdown()/shutdownNow()中都会尝试更新为这个状态。TERMINATED终止状态,当执行terminated()后会更新为这个状态。

execute() 方法的处理流程:

- 获取当前线程池的状态。
- 当前线程数量小于 coreSize 时创建一个新的线程运行。
- 如果当前线程处于运行状态,并且写入阻塞队列成功。
- 双重检查,再次获取线程状态;如果线程状态变了(非运行状态)就需要从阻塞队列移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
- 如果当前线程池为空就新创建一个线程并执行。
- 如果在第三步的判断为非运行状态,尝试新建线程,如果失败则执行拒绝策略。
这里借助《聊聊并发》的一张图来描述这个流程:

关闭线程池
我们可以通过shutdown和shutdownNow两个方法关闭线程池。两个方法的区别在于,shutdown 会将线程池的状态设置为SHUTDOWN,同时该方法还会中断空闲线程。shutdownNow 则会将线程池状态设置为STOP,并尝试中断所有的线程。中断线程使用的是Thread.interrupt方法,未响应中断方法的任务是无法被中断的。最后,shutdownNow 方法会将未执行的任务全部返回。
调用 shutdown 和 shutdownNow 方法关闭线程池后,就不能再向线程池提交新任务了。对于处于关闭状态的线程池,会使用拒绝策略处理新提交的任务。
Spring Boot 中使用线程池
既然用了 SpringBoot ,那自然得发挥 Spring 的特性,所以需要 Spring 来帮我们管理线程池:
1 |
|
使用时:
1 | (name = "consumerQueueThreadPool") |
其实也挺简单,就是创建了一个线程池的 bean,在使用时直接从 Spring 中取出即可。
其他
- 线程池本质是一个hashSet。多余的任务会放在阻塞队列中。
常见方法
interrupt():不要以为它是中断某个线程!它只是线程发送一个中断信号,让线程在无限等待时(如死锁时)能抛出异常,从而结束线程,但是如果你吃掉了这个异常,那么这个线程还是不会中断的!
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException 。
wait()
Object.wait(),与 Object.notify() 必须要与 synchronized(Obj) 一起使用,也就是wait与notify是针对已经获取了Obj锁进行操作,从语法角度来说就是Obj.wait(),Obj.notify必须在synchronized(Obj){…}语句块内,否则会在运行时抛出”java.lang.IllegalMonitorStateException“异常。。从功能上来说wait就是说线程在获取对象锁后,主动释放对象锁,同时本线程休眠。直到有其它线程调用对象的notify()唤醒该线程,才能继续获取对象锁,并继续执行。相应的notify()就是对对象锁的唤醒操作。但有一点需要注意的是notify()调用后,并不是马上就释放对象锁的,而是在相应的synchronized(){}语句块执行结束,自动释放锁后,JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。这样就提供了在线程间同步、唤醒的操作。Thread.sleep()与Object.wait()二者都可以暂停当前线程,释放CPU控制权,主要的区别在于Object.wait()在释放CPU同时,释放了对象锁的控制。
常见业务场景
应用世界自动跳转的实现
一个业务逻辑有很多次的循环,每次循环之间没有影响,比如验证1万条url路径是否存在,正常情况要循环1万次,逐个去验证每一条URL,这样效率会很低,假设验证一条需要1分钟,总共就需要1万分钟,有点恐怖。这时可以用多线程,将1万条URL分成50等份,开50个线程,没个线程只需验证200条,这样所有的线程执行完是远小于1万分钟的。
需要知道一个任务的执行进度,比如我们常看到的进度条,实现方式可以是在任务中加入一个整型属性变量(这样不同方法可以共享),任务执行一定程度就给变量值加1,另外开一个线程按时间间隔不断去访问这个变量,并反馈给用户。
面试常见问题
进程和线程的区别
进程:每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含多个线程。(进程是资源分配的最小单位)
线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)
同步和异步的区别
同步是阻塞模式,异步是非阻塞模式。
同步就是:如果有多个任务或者事件要发生,这些任务或者事件必须逐个地进行,一个事件或者任务的执行会导致整个流程的暂时等待,这些事件没有办法并发地执行;
异步就是:如果有多个任务或者事件发生,这些事件可以并发地执行,一个事件或者任务的执行不会导致整个流程的暂时等待。这就是同步和异步。
事实上,同步和异步是一个非常广的概念,它们的重点在于多个任务和事件发生时,一个事件的发生或执行是否会导致整个流程的暂时等待。可以将同步和异步与Java中的synchronized关键字联系起来进行类比。当多个线程同时访问一个变量时,每个线程访问该变量就是一个事件,对于同步来说,就是这些线程必须逐个地来访问该变量,一个线程在访问该变量的过程中,其他线程必须等待;而对于异步来说,就是多个线程不必逐个地访问该变量,可以同时进行访问。
同步和异步可以表现在很多方面,但是记住其关键在于多个任务和事件发生时,一个事件的发生或执行是否会导致整个流程的暂时等待。一般来说,可以通过多线程的方式来实现异步,但是千万记住不要将多线程和异步画上等号,异步只是宏观上的一个模式,采用多线程来实现异步只是一种手段,并且通过多进程的方式也可以实现异步。
什么是阻塞?什么是非阻塞?
阻塞就是:当某个事件或者任务在执行过程中,它发出一个请求操作,但是由于该请求操作需要的条件不满足,那么就会一直在那等待,直至条件满足;
非阻塞就是:当某个事件或者任务在执行过程中,它发出一个请求操作,如果该请求操作需要的条件不满足,会立即返回一个标志信息告知条件不满足,不会一直在那等待。
这就是阻塞和非阻塞的区别。也就是说阻塞和非阻塞的区别关键在于当发出请求一个操作时,如果条件不满足,是会一直等待还是返回一个标志信息。
同步和异步分别与阻塞和非阻塞是两组完全不同的概念。同步和异步着重点在于多个任务的执行过程中,一个任务的执行是否会导致整个流程的暂时等待;而阻塞和非阻塞着重点在于发出一个请求操作时,如果进行操作的条件不满足是否会返会一个标志信息告知条件不满足。理解阻塞和非阻塞可以同线程阻塞类比地理解,当一个线程进行一个请求操作时,如果条件不满足,则会被阻塞,即在那等待条件满足。
什么是同步IO?什么是异步IO?
在《Unix网络编程》一书中对同步IO和异步IO的定义是这样的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
An asynchronous I/O operation does not cause the requesting process to be blocked.
从字面的意思可以看出,同步IO:即如果一个线程请求进行IO操作,在IO操作完成之前,该线程会被阻塞;而异步IO为:如果一个线程请求进行IO操作,IO操作不会导致请求线程被阻塞。
事实上,同步IO和异步IO模型是针对用户线程和内核的交互来说的:
对于同步IO:当用户发出IO请求操作之后,如果数据没有就绪,需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户线程;
而异步IO:只有IO请求操作的发出是由用户线程来进行的,IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成。也就是说在异步IO中,不会对用户线程产生任何阻塞。
同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。
注意同步IO和异步IO与阻塞IO和非阻塞IO是不同的两组概念。阻塞IO和非阻塞IO是反映在当用户请求IO操作时,如果数据没有就绪,是用户线程一直等待数据就绪,还是会收到一个标志信息这一点上面的。也就是说,阻塞IO和非阻塞IO是反映在IO操作的第一个阶段,在查看数据是否就绪时是如何处理的。而同步IO和异步IO模型是针对用户线程和内核的交互来说的。
wait和sleep的区别
- sleep() 是 Thread 类的方法,而 wait() 是 Object 的方法。
- sleep方法没有释放锁,而wait方法释放了锁。
- wait,notify 和 notifyAll 只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
sleep() 和 yield() 的区别
sleep()使当前线程进入阻塞状态,所以执行sleep()的线程在指定的时间内肯定不会被执行;yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
sleep 方法使当前运行中的线程睡眼一段时间,进入不可运行状态,这段时间的长短是由程序设定的,yield 方法使当前线程让出 CPU 占有权,但让出的时间是不可设定的。实际上,yield()方法对应了如下操作:先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把 CPU 的占有权交给此线程,否则,继续运行原来的线程。所以yield()方法称为“退让”,它把运行机会让给了同等优先级的其他线程。
另外,sleep 方法允许较低优先级的线程获得运行机会,但 yield() 方法执行时,当前线程仍处在可运行状态,所以,不可能让出较低优先级的线程些时获得 CPU 占有权。在一个运行系统中,如果较高优先级的线程没有调用 sleep 方法,又没有受到 I\O 阻塞,那么,较低优先级线程只能等待所有较高优先级的线程运行结束,才有机会运行。
sleep 方法声明抛出 InterruptedException,而 yield 方法没有声明任何异常。
Thread.sleep() 与 Object.wait() 的区别
原理不同
sleep 方法是 Thread 类的静态方法,是线程用来控制自身流程的。它会使此线程暂停执行一段时间,等到计时时间一到,此线程会自动“苏醒”。
wait 方法是 Object 类的方法,用于线程间的通信,它会使拥有该对象锁的进程等待,知道其他进程调用 notify 方法是才“醒来”。
对锁的处理机制不同
二者都可以暂停当前线程,释放CPU控制权,主要的区别在于Object.wait()在释放CPU同时,释放了对象锁的控制;而sleep方法只是释放了对 CPU 的控制器,并不会释放锁。
使用区域不同
wait、notify 等方法必须在同步控制方法或者同步代码块中使用,而 sleep 可以在任何地方使用。
三线程打印ABC
题目:建立三个线程,A线程打印10次A,B线程打印10次B,C线程打印10次C,要求线程同时运行,交替打印10次ABC。
思路:这个问题用Object的wait(),notify()就可以很方便的解决。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51package com.multithread.wait;
public class MyThreadPrinter2 implements Runnable {
private String name;
private Object prev;
private Object self;
private MyThreadPrinter2(String name, Object prev, Object self) {
this.name = name;
this.prev = prev;
this.self = self;
}
public void run() {
int count = 10;
while (count > 0) {
synchronized (prev) {
synchronized (self) {
System.out.print(name);
count--;
self.notify();
}
try {
prev.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
Object a = new Object();
Object b = new Object();
Object c = new Object();
MyThreadPrinter2 pa = new MyThreadPrinter2("A", c, a);
MyThreadPrinter2 pb = new MyThreadPrinter2("B", a, b);
MyThreadPrinter2 pc = new MyThreadPrinter2("C", b, c);
new Thread(pa).start();
Thread.sleep(100); //确保按顺序A、B、C执行
new Thread(pb).start();
Thread.sleep(100);
new Thread(pc).start();
Thread.sleep(100);
}
}从大的方向上来讲,该问题为三线程间的同步唤醒操作,主要的目的就是ThreadA->ThreadB->ThreadC->ThreadA循环执行三个线程。为了控制线程执行的顺序,那么就必须要确定唤醒、等待的顺序,所以每一个线程必须同时持有两个对象锁,才能继续执行。一个对象锁是prev,就是前一个线程所持有的对象锁。还有一个就是自身对象锁。主要的思想就是,为了控制执行的顺序,必须要先持有prev锁,也就前一个线程要释放自身对象锁,再去申请自身对象锁,两者兼备时打印,之后首先调用self.notify()释放自身对象锁,唤醒下一个等待线程,再调用prev.wait()释放prev对象锁,终止当前线程,等待循环结束后再次被唤醒。运行上述代码,可以发现三个线程循环打印ABC,共10次。程序运行的主要过程就是A线程最先运行,持有C,A对象锁,后释放A,C锁,唤醒B。线程B等待A锁,再申请B锁,后打印B,再释放B,A锁,唤醒C,线程C等待B锁,再申请C锁,后打印C,再释放C,B锁,唤醒A。看起来似乎没什么问题,但如果你仔细想一下,就会发现有问题,就是初始条件,三个线程按照A,B,C的顺序来启动,按照前面的思考,A唤醒B,B唤醒C,C再唤醒A。但是这种假设依赖于JVM中线程调度、执行的顺序。
两个线程交替打印出100以内的奇数和偶数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46package com.dubbo.worldCup.utils;
public class SynchronizedTest {
private static int cnt = 1;
private static class MyThread implements Runnable {
public void run() {
while (true) {
synchronized (this) {
if (cnt <= 100) {
System.out.println(Thread.currentThread().getName() + ":" + cnt++);
this.notify();
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
return;
}
}
}
}
}
public static void main(String[] args) {
MyThread myThread = new MyThread();
new Thread(myThread).start();
new Thread(myThread).start();
}
}
----------------------------------------------
Thread-0:1
Thread-1:2
Thread-0:3
Thread-1:4
Thread-0:5
…………………………
Thread-1:96
Thread-0:97
Thread-1:98
Thread-0:99
Thread-1:100
设计模式

单例模式
一般有 8 种:饿汉式(静态常量)、饿汉式(静态代码块)、懒汉式(线程不安全)、懒汉式(线程安全,同步方法)、懒汉式(线程安全,同步代码块)、双重校验锁、静态内部类、枚举
| 实现方式 | 线程安全 | 延迟加载 | 抵御反射攻击 |
|---|---|---|---|
| 饿汉式(静态常量) | Y | N | N |
| 饿汉式(静态代码块) | Y | N | N |
| 懒汉式(线程不安全) | Y | Y | N |
| 懒汉式(线程安全,同步方法) | Y | Y | N |
| 懒汉式(线程安全,同步代码块) | N | Y | N |
| 双重校验锁 | Y | Y | N |
| 静态内部类 | Y | Y | N |
| 枚举 | Y | Y | Y |
饿汉式(静态常量)
1 | public class Singleton { |
优点:基于 classloader 机制避免了多线程的同步问题。没有加锁,执行效率会提高。
缺点:类加载时就初始化,浪费内存。
饿汉式(静态代码块)
1 | public class Singleton { |
优点:基于 classloader 机制避免了多线程的同步问题。没有加锁,执行效率会提高。
缺点:类加载时就初始化,浪费内存。
懒汉式(线程不安全)
1 | public class Singleton { |
优点:懒加载。
缺点:线程不安全。
懒汉式(线程安全,同步方法)
1 | public class Singleton { |
优点:懒加载, 线程安全。
缺点:加锁影响效率。
懒汉式(线程安全,同步代码块)
1 | public class Singleton { |
优点:懒加载, 解决效率问题。
缺点:存在线程安全问题。
双重校验锁(DCL,即 double-checked locking)
1 | public class Singleton { |
优点:线程安全且在多线程情况下能保持高性能。
缺点:由于JVM编译器的指令重排可能会导致线程不安全。使用 volatile 修饰 singleton 可避免此问题。
静态内部类
1 | public class Singleton { |
优点:利用类加载机制避免了线程不安全,相对饿汉式增加了延迟加载能力,效率高。
枚举
1 | public enum Singleton { |
优点:利用 enum 语法糖,JVM 会阻止获取枚举类的私有构造方法。使用枚举实现的单例模式,不但可以防止利用反射强行构建单例对象,而且可以在枚举类对象被反序列化的时候,保证反序列的返回结果是同一对象
缺点:非懒加载。
工厂模式
简单工厂
定义
简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。
实例
应用
JDK类库中广泛使用了简单工厂模式,如工具类java.text.DateFormat,它用于格式化一个本地日期或者时间。
1
2
3
4public final static DateFormat getDateInstance();
public final static DateFormat getDateInstance(int style);
public final static DateFormat getDateInstance(int style,Locale
locale);Java加密技术
获取不同加密算法的密钥生成器:
1
KeyGenerator keyGen=KeyGenerator.getInstance("DESede");
创建密码器:
1
Cipher cp=Cipher.getInstance("DESede");
优点:
1、屏蔽产品的具体实现,调用者只关心产品的接口。
2、实现简单
缺点:
1、增加产品,需要修改工厂类,不符合开放-封闭原则
2、工厂类集中了所有实例的创建逻辑,违反了高内聚责任分配原则
工厂方法
定义
工厂方法模式(Factory Method Pattern)又称为工厂模式,也叫虚拟构造器(Virtual Constructor)模式或者多态工厂(Polymorphic Factory)模式,它属于类创建型模式。在工厂方法模式中,工厂父类负责定义创建产品对象的公共接口,而工厂子类则负责生成具体的产品对象,这样做的目的是将产品类的实例化操作延迟到工厂子类中完成,即通过工厂子类来确定究竟应该实例化哪一个具体产品类。
在工厂方法模式中,核心的工厂类不再负责所有产品的创建,而是将具体创建工作交给子类去做。这个核心类仅仅负责给出具体工厂必须实现的接口,而不负责哪一个产品类被实例化这种细节,这使得工厂方法模式可以允许系统在不修改工厂角色的情况下引进新产品。这一特点无疑使得工厂方法模式具有超越简单工厂模式的优越性,更加符合“开闭原则”。
实例
应用
Collection中的iterator方法
java.util.Collection接口中定义了一个抽象的iterator()方法,该方法就是一个工厂方法。对于
iterator()方法来说Collection就是一个根抽象工厂,下面还有List等接口作为抽象工厂,再往下有ArrayList等具体工厂。java.util.Iterator接口是根抽象产品,下面有ListIterator等抽象产品,还有ArrayListIterator等作为具体产品。使用不同的具体工厂类中的
iterator方法能得到不同的具体产品的实例。
优点:
1、继承了简单工厂模式的优点
2、符合开放-封闭原则
缺点:
1、增加产品,需要增加新的工厂类,导致系统类的个数成对增加,在一定程度上增加了系统的复杂性。
抽象工厂
定义
抽象工厂模式(Abstract Factory Pattern):提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,属于对象创建型模式。
抽象工厂是生产一整套有产品的(至少要生产两个产品),这些产品必须相互是有关系或有依赖的,而工厂方法中的工厂是生产单一产品的工厂。
实例
应用
jdk 中的数据库链接
![]()
抽象工厂:Connection
具体工厂:MysqlCollectionImpl
抽象产品:Statement、PreparedStatement、CallableStatement、ResultSet
具体产品:MysqlStatement、MysqlPreparedStatement、MysqlCallableStatement、MysqlResultSet
在很多软件系统中需要更换界面主题,要求界面中的按钮、文本框、背景色等一起发生改变时,可以使用抽象工厂模式进行设计。例如UIManager(swing外观)
适配器模式
定义
适配器模式(Adapter Pattern) :将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。
结构
适配器模式包含如下角色:
- Target:目标抽象类
- Adapter:适配器类
- Adaptee:适配者类
- Client:客户类
适配器模式有对象适配器和类适配器两种实现:
实例
类的适配器模式
创建Target接口(目标抽象类)
1
2
3
4public interface Target {
//这是源类Adapteee没有的方法
public void Request();
}
创建源类 Adaptee(适配者类)
1
2
3
4public class Adaptee {
public void SpecificRequest(){
}
}
创建适配器类 Adapter(适配器类)
1
2
3
4
5
6
7
8
9
10
11
12//适配器Adapter继承自Adaptee,同时又实现了目标(Target)接口。
public class Adapter extends Adaptee implements Target {
//目标接口要求调用Request()这个方法名,但源类Adaptee没有方法Request()
//因此适配器补充上这个方法名
//但实际上Request()只是调用源类Adaptee的SpecificRequest()方法的内容
//所以适配器只是将SpecificRequest()方法作了一层封装,封装成Target可以调用的Request()而已
public void Request() {
this.SpecificRequest();
}
}定义具体使用目标类,并通过Adapter类调用所需要的方法从而实现目标(客户类)
1
2
3
4
5
6
7public class AdapterPattern {
public static void main(String[] args){
Target mAdapter = new Adapter();
mAdapter.Request();
}
}
- 背景:小成买了一个进口的电视机
- 冲突:进口电视机要求电压(110V)与国内插头标准输出电压(220V)不兼容
- 解决方案:设置一个适配器,将插头输出的220V转变成110V
创建Target接口,期待得到的插头能将 220V 转换成 110V(目标抽象类)
1
2
3
4public interface Target {
//将220V转换成110V(原有插头(Adaptee)没有的)
public void Convert_110v();
}创建源类,原有的插头(适配者类)
1
2
3
4
5class PowerPort220V{
//原有插头只能接收220V
public void Receive_220v(){
}
}创建适配器类
1
2
3
4
5
6
7
8
9
10class Adapter220V extends PowerPort220V implements Target{
//期待的插头要求调用 Convert_110v(),但原有插头没有
//因此适配器补充上这个方法名
//但实际上Convert_110v()只是调用原有插头的Receive_220v()方法的内容
//所以适配器只是将Receive_220v()作了一层封装,封装成Target可以调用的Convert_110v()而已
public void Convert_110v(){
this.Receive_220v;
}
}定义具体使用目标类,并通过Adapter类调用所需要的方法从而实现目标(客户类)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22//进口机器类
class ImportedMachine {
public void Work() {
System.out.println("进口机器正常运行");
}
}
//通过Adapter类调用所需要的方法
public class AdapterPattern {
public static void main(String[] args){
Target mAdapter220V = new Adapter220V();
ImportedMachine mImportedMachine = new ImportedMachine();
//用户拿着进口机器插上适配器(调用Convert_110v()方法)
//再将适配器插上原有插头(Convert_110v()方法内部调用Receive_220v()方法接收220V)
//适配器只是个外壳,对外提供110V,但本质还是220V进行供电
mAdapter220V.Convert_110v();
mImportedMachine.Work();
}
}
对象的适配器模式
与类的适配器模式不同的是,对象的适配器模式不是使用继承关系连接到Adaptee类,而是使用委派关系连接到Adaptee类。
创建Target接口
1
2
3
4public interface Target {
//这是源类Adapteee没有的方法
public void Request();
}创建源类(Adaptee)
1
2
3
4public class Adaptee {
public void SpecificRequest(){
}
}创建适配器类(Adapter)(不用继承而是委派)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Adapter implements Target{
// 直接关联被适配类
private Adaptee adaptee;
// 可以通过构造函数传入具体需要适配的适配者对象
public Adapter (Adaptee adaptee) {
this.adaptee = adaptee;
}
public void Request() {
// 这里是使用委托的方式完成特殊功能
this.adaptee.SpecificRequest();
}
}定义具体使用目标类,并通过Adapter类调用所需要的方法从而实现目标。
1
2
3
4
5
6
7
8public class AdapterPattern {
public static void main(String[] args){
//需要先创建一个适配者的对象作为参数
Target mAdapter = new Adapter(new Adaptee());
mAdapter.Request();
}
}
应用
Sun公司在1996年公开了Java语言的数据库连接工具JDBC,JDBC使得Java语言程序能够与数据库连接,并使用SQL语言来查询和操作数据。JDBC给出一个客户端通用的抽象接口,每一个具体数据库引擎(如SQL Server、Oracle、MySQL等)的JDBC驱动软件都是一个介于JDBC接口和数据库引擎接口之间的适配器软件。抽象的JDBC接口和各个数据库引擎API之间都需要相应的适配器软件,这就是为各个不同数据库引擎准备的驱动程序。
装饰模式
定义
装饰模式(Decorator Pattern) :动态地给一个对象增加一些额外的职责(Responsibility),就增加对象功能来说,装饰模式比生成子类实现更为灵活。其别名也可以称为包装器(Wrapper),与适配器模式的别名相同,但它们适用于不同的场合。根据翻译的不同,装饰模式也有人称之为“油漆工模式”,它是一种对象结构型模式。
在阎宏博士的《JAVA与模式》一书中开头是这样描述装饰(Decorator)模式的:
装饰模式又名包装(Wrapper)模式。装饰模式以对客户端透明的方式扩展对象的功能,是继承关系的一个替代方案。
结构
装饰模式包含如下角色:
- Component: 抽象构件
- ConcreteComponent: 具体构件
- Decorator: 抽象装饰类
- ConcreteDecorator: 具体装饰类
实例
齐天大圣的例子:孙悟空有七十二般变化,他的每一种变化都给他带来一种附加的本领。他变成鱼儿时,就可以到水里游泳;他变成鸟儿时,就可以在天上飞行。
本例中,Component的角色便由鼎鼎大名的齐天大圣扮演;ConcreteComponent的角色属于大圣的本尊,就是猢狲本人;Decorator的角色由大圣的七十二变扮演。而ConcreteDecorator的角色便是鱼儿、鸟儿等七十二般变化。

抽象构件角色“齐天大圣”接口定义了一个move()方法,这是所有的具体构件类和装饰类必须实现的。
1
2
3
4//大圣的尊号
public interface TheGreatestSage {
public void move();
}具体构件角色“大圣本尊”猢狲类
1
2
3
4
5
6
7
8public class Monkey implements TheGreatestSage {
public void move() {
//代码
System.out.println("Monkey Move");
}
}抽象装饰角色“七十二变”
1
2
3
4
5
6
7
8
9
10
11
12
13public class Change implements TheGreatestSage {
private TheGreatestSage sage;
public Change(TheGreatestSage sage){
this.sage = sage;
}
public void move() {
// 代码
sage.move();
}
}具体装饰角色“鱼儿”
1
2
3
4
5
6
7
8
9
10
11
12public class Fish extends Change {
public Fish(TheGreatestSage sage) {
super(sage);
}
public void move() {
// 代码
System.out.println("Fish Move");
}
}具体装饰角色“鸟儿”
1
2
3
4
5
6
7
8
9
10
11
12public class Bird extends Change {
public Bird(TheGreatestSage sage) {
super(sage);
}
public void move() {
// 代码
System.out.println("Bird Move");
}
}客户端类
1
2
3
4
5
6
7
8
9
10
11
12
13public class Client {
public static void main(String[] args) {
TheGreatestSage sage = new Monkey();
// 第一种写法
TheGreatestSage bird = new Bird(sage);
TheGreatestSage fish = new Fish(bird);
// 第二种写法
//TheGreatestSage fish = new Fish(new Bird(sage));
fish.move();
}
}
“大圣本尊”是ConcreteComponent类,而“鸟儿”、“鱼儿”是装饰类。要装饰的是“大圣本尊”,也即“猢狲”实例。
上面的例子中,系统把大圣从一只猢狲装饰成了一只鸟儿(把鸟儿的功能加到了猢狲身上),然后又把鸟儿装饰成了一条鱼儿(把鱼儿的功能加到了猢狲+鸟儿身上,得到了猢狲+鸟儿+鱼儿)。

如上图所示,大圣的变化首先将鸟儿的功能附加到了猢狲身上,然后又将鱼儿的功能附加到猢狲+鸟儿身上。
透明性的要求
装饰模式对客户端的透明性要求程序不要声明一个ConcreteComponent类型的变量,而应当声明一个Component类型的变量。
用孙悟空的例子来说,必须永远把孙悟空的所有变化都当成孙悟空来对待,而如果把老孙变成的鱼儿当成鱼儿,而不是老孙,那就被老孙骗了,而这是不应当发生的。
下面的做法是对的:
1 | TheGreatestSage sage = new Monkey(); |
而下面的做法是不对的:
1 | Monkey sage = new Monkey(); |
半透明的装饰模式
然而,纯粹的装饰模式很难找到。装饰模式的用意是在不改变接口的前提下,增强所考虑的类的性能。在增强性能的时候,往往需要建立新的公开的方法。即便是在孙大圣的系统里,也需要新的方法。比如齐天大圣类并没有飞行的能力,而鸟儿有。这就意味着鸟儿应当有一个新的fly()方法。再比如,齐天大圣类并没有游泳的能力,而鱼儿有,这就意味着在鱼儿类里应当有一个新的swim()方法。
这就导致了大多数的装饰模式的实现都是“半透明”的,而不是完全透明的。换言之,允许装饰模式改变接口,增加新的方法。这意味着客户端可以声明ConcreteDecorator类型的变量,从而可以调用ConcreteDecorator类中才有的方法:
1 | TheGreatestSage sage = new Monkey(); |
半透明的装饰模式是介于装饰模式和适配器模式之间的。适配器模式的用意是改变所考虑的类的接口,也可以通过改写一个或几个方法,或增加新的方法来增强或改变所考虑的类的功能。大多数的装饰模式实际上是半透明的装饰模式,这样的装饰模式也称做半装饰、半适配器模式。
装饰模式和适配器模式都是“包装模式(Wrapper Pattern)”,它们都是通过封装其他对象达到设计的目的的,但是它们的形态有很大区别。
理想的装饰模式在对被装饰对象进行功能增强的同时,要求具体构件角色、装饰角色的接口与抽象构件角色的接口完全一致。而适配器模式则不然,一般而言,适配器模式并不要求对源对象的功能进行增强,但是会改变源对象的接口,以便和目标接口相符合。
装饰模式有透明和半透明两种,这两种的区别就在于装饰角色的接口与抽象构件角色的接口是否完全一致。透明的装饰模式也就是理想的装饰模式,要求具体构件角色、装饰角色的接口与抽象构件角色的接口完全一致。相反,如果装饰角色的接口与抽象构件角色接口不一致,也就是说装饰角色的接口比抽象构件角色的接口宽的话,装饰角色实际上已经成了一个适配器角色,这种装饰模式也是可以接受的,称为“半透明”的装饰模式,如下图所示。

在适配器模式里面,适配器类的接口通常会与目标类的接口重叠,但往往并不完全相同。换言之,适配器类的接口会比被装饰的目标类接口宽。
显然,半透明的装饰模式实际上就是处于适配器模式与装饰模式之间的灰色地带。如果将装饰模式与适配器模式合并成为一个“包装模式”的话,那么半透明的装饰模式倒可以成为这种合并后的“包装模式”的代表。
InputStream类型中的装饰模式
InputStream类型中的装饰模式是半透明的。为了说明这一点,不妨看一看作装饰模式的抽象构件角色的InputStream的源代码。这个抽象类声明了九个方法,并给出了其中八个的实现,另外一个是抽象方法,需要由子类实现。
1 | public abstract class InputStream implements Closeable { |
下面是作为装饰模式的抽象装饰角色FilterInputStream类的源代码。可以看出,FilterInputStream的接口与InputStream的接口是完全一致的。也就是说,直到这一步,还是与装饰模式相符合的。
1 | public class FilterInputStream extends InputStream { |
下面是具体装饰角色PushbackInputStream的源代码。
1 | public class PushbackInputStream extends FilterInputStream { |
查看源码,你会发现,这个装饰类提供了额外的方法unread(),这就意味着PushbackInputStream是一个半透明的装饰类。换言之,它破坏了理想的装饰模式的要求。如果客户端持有一个类型为InputStream对象的引用in的话,那么如果in的真实类型是 PushbackInputStream 的话,只要客户端不需要使用unread()方法,那么客户端一般没有问题。但是如果客户端必须使用这个方法,就必须进行向下类型转换。将in的类型转换成为PushbackInputStream之后才可能调用这个方法。但是,这个类型转换意味着客户端必须知道它拿到的引用是指向一个类型为PushbackInputStream的对象。这就破坏了使用装饰模式的原始用意。
现实世界与理论总归是有一段差距的。纯粹的装饰模式在真实的系统中很难找到。一般所遇到的,都是这种半透明的装饰模式。
下面是使用I/O流读取文件内容的简单操作示例:
1 | public class IOTest { |
观察上面的代码,会发现最里层是一个FileInputStream对象,然后把它传递给一个BufferedInputStream对象,经过BufferedInputStream处理,再把处理后的对象传递给了DataInputStream对象进行处理,这个过程其实就是装饰器的组装过程,FileInputStream对象相当于原始的被装饰的对象,而BufferedInputStream对象和DataInputStream对象则相当于装饰器。
应用
设计模式在JAVA I/O库中的应用
装饰模式在Java语言中的最著名的应用莫过于Java I/O标准库的设计了。
由于Java I/O库需要很多性能的各种组合,如果这些性能都是用继承的方法实现的,那么每一种组合都需要一个类,这样就会造成大量性能重复的类出现。而如果采用装饰模式,那么类的数目就会大大减少,性能的重复也可以减至最少。因此装饰模式是Java I/O库的基本模式。
Java I/O库的对象结构图如下,由于Java I/O的对象众多,因此只画出InputStream的部分。

根据上图可以看出:
抽象构件(Component)角色:由InputStream扮演。这是一个抽象类,为各种子类型提供统一的接口。
具体构件(ConcreteComponent)角色:由ByteArrayInputStream、FileInputStream、PipedInputStream、StringBufferInputStream等类扮演。它们实现了抽象构件角色所规定的接口。
抽象装饰(Decorator)角色:由FilterInputStream扮演。它实现了InputStream所规定的接口。
具体装饰(ConcreteDecorator)角色:由几个类扮演,分别是BufferedInputStream、DataInputStream以及两个不常用到的类LineNumberInputStream、PushbackInputStream。
代理模式
定义
代理模式(Proxy Pattern) :给某一个对象提供一个代理,并由代理对象控制对原对象的引用。代理模式的英 文叫做Proxy或Surrogate,它是一种对象结构型模式。
结构
代理模式包含如下角色:
- Subject: 抽象主题角色
- Proxy: 代理主题角色
- RealSubject: 真实主题角色
实例
代理模式分为静态代理和动态代理两种。
区别在于:静态代理在编译期确定代理对象,在程序运行前代理类的.class文件就已经存在了;而动态代理在运行期,通过反射机制创建代理对象。
静态代理
我们将创建一个 Image 接口和实现了 Image 接口的实体类。ProxyImage 是一个代理类,减少 RealImage 对象加载的内存占用。
ProxyPatternDemo*,我们的演示类使用 *ProxyImage 来获取要加载的 Image 对象,并按照需求进行显示。
创建一个接口(抽象主题角色)
1
2
3public interface Image {
void display();
}创建实现接口的实体类(真实主题角色)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class RealImage implements Image {
private String fileName;
public RealImage(String fileName) {
this.fileName = fileName;
loadFromDisk(fileName);
}
public void display() {
System.out.println("Displaying " + fileName);
}
private void loadFromDisk(String fileName) {
System.out.println("Loading " + fileName);
}
}创建实现接口的实体类(代理主题角色)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class ProxyImage implements Image {
private RealImage realImage;
private String fileName;
public ProxyImage(String fileName) {
this.fileName = fileName;
}
public void display() {
if (realImage == null) {
realImage = new RealImage(fileName);
}
realImage.display();
}
}使用 ProxyImage 来获取 RealImage 类的对象
1
2
3
4
5
6
7
8
9
10public class ProxyPatternDemo {
public static void main(String[] args) {
Image image = new ProxyImage("test_10mb.jpg");
// 图像将从磁盘加载
image.display();
System.out.println("");
// 图像不需要从磁盘加载
image.display();
}
}执行程序,输出结果:
1
2
3
4Loading test_10mb.jpg
Displaying test_10mb.jpg
Displaying test_10mb.jpg
优点:可以做到在不修改目标对象的功能前提下,对目标功能扩展。
缺点:代理类和委托类实现相同的接口,同时要实现相同的方法。这样就出现了大量的代码重复。如果接口增加一个方法,除了所有实现类需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度。
动态代理
JDK动态代理
- java.lang.reflect.Proxy:生成动态代理类和对象;
- java.lang.reflect.InvocationHandler(处理器接口):可以通过invoke方法实现对真实角色的代理访问。
JDK生成代理只需要使用 Proxy 的 newProxyInstance 方法,但是该方法需要接收三个参数:
1 | static Object newProxyInstance(ClassLoader loader, Class [] interfaces, InvocationHandler handler) |
注意该方法是在Proxy类中是静态方法,每次通过 Proxy 生成的代理类对象都要指定对应的处理器对象。
- ClassLoader loader:指定当前目标对象使用类加载器,用null表示默认类加载器
- Class [] interfaces:需要实现的接口数组
- InvocationHandler handler:调用处理器,执行目标对象的方法时,会触发调用处理器的方法,从而把当前执行目标对象的方法作为参数传入
java.lang.reflect.InvocationHandler:这是调用处理器接口,它自定义了一个 invoke 方法,用于集中处理在动态代理类对象上的方法调用,通常在该方法中实现对委托类的代理访问。
1 | // 该方法负责集中处理动态代理类上的所有方法调用。 |
代码示例:
- 接口:Subject.java(抽象主题角色)
1 | public interface Subject { |
- 真实对象:RealSubject.java(真实主题角色)
1 | public class RealSubject implements Subject{ |
- 处理器对象:MyInvocationHandler.java
1 | import java.lang.reflect.InvocationHandler; |
- 调用端:Client.java
1 | import java.lang.reflect.Proxy; |
总结:代理对象不需要实现接口,但是目标对象一定要实现接口,否则不能用动态代理。
CGLIB动态代理
静态代理和JDK动态代理模式都是要求目标对象实现一个接口或者多个接口,但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候就可以使用构建目标对象子类的方式实现代理,这种方法就叫做:Cglib代理。
Cglib代理,也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展。
Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口。它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)。
Cglib包的底层是通过使用字节码处理框架ASM来转换字节码并生成新的子类。
代理的类不能为final,否则报错;目标对象的方法如果为 final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法。
Cglib 动态代理是针对目标类, 动态生成一个子类, 然后子类覆盖父类中的方法, 如果是private或是final类修饰的方法,则不会被重写。
- 需要代理的类(真实主题角色)
1 | package cn.cpf.pattern.structure.proxy.cglib; |
- CGLIB 代理类(代理主题角色)
1 | package cn.cpf.pattern.structure.proxy.cglib; |
测试方法:
1 | import java.lang.reflect.Method; |
运行结果:
1 | ### before invocation |
应用
Spring AOP的实现。
图片代理:一个很常见的代理模式的应用实例就是对大图浏览的控制。
用户通过浏览器访问网页时先不加载真实的大图,而是通过代理对象的方法来进行处理,在代理对象的方法中,先使用一个线程向客户端浏览器加载一个小图片,然后在后台使用另一个线程来调用大图片的加载方法将大图片加载到客户端。当需要浏览大图片时,再将大图片在新网页中显示。如果用户在浏览大图时加载工作还没有完成,可以再启动一个线程来显示相应的提示信息。通过代理技术结合多线程编程将真实图片的加载放到后台来操作,不影响前台图片的浏览。
远程代理。
远程代理可以将网络的细节隐藏起来,使得客户端不必考虑网络的存在。客户完全可以认为被代理的远程业务对象是局域的而不是远程的,而远程代理对象承担了大部分的网络通信工作。
虚拟代理。
当一个对象的加载十分耗费资源的时候,虚拟代理的优势就非常明显地体现出来了。虚拟代理模式是一种内存节省技术,那些占用大量内存或处理复杂的对象将推迟到使用它的时候才创建。
Copy-on-Write 代理。
保护(Protect or Access)代理。
Cache代理。
为结果提供临时的存储空间,以便其他客户端调用防火墙(Firewall)代理。
保护目标不让恶意用户靠近
同步化(Synchronization)代理。
智能引用(Smart Reference)代理。
代理模式和装饰器模式的区别
- 装饰器模式:能动态的新增或组合对象的行为
在不改变接口的前提下,动态扩展对象的功能 - 代理模式:为其他对象提供一种代理以控制对这个对象的访问
在不改变接口的前提下,控制对象的访问
装饰模式是“新增行为”,而代理模式是“控制访问”。关键就是我们如何判断是“新增行为”还是“控制访问”。
- 代理类所能代理的类完全由代理类确定,装饰类装饰的对象需要根据实际使用时客户端的组合来确定
- 被代理对象由代理对象创建,客户端甚至不需要知道被代理类的存在;被装饰对象由客户端创建并传给装饰对象
代理模式和适配器模式的区别
适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。
Spring
简单来说,Spring 是一个分层的 JavaSE/EE full-stack(一站式) 轻量级开源框架。
Spring有分层的体系结构,这意味着你能选择使用它孤立的任何部分,它的架构仍然是内在稳定的。例如,你可能选择仅仅使用Spring来简化JDBC的使用,或用来管理所有的业务对象。
spring 特征:
轻量
从大小与开销两方面而言Spring都是轻量的。完整的Spring框架可以在一个大小只有1MB多的JAR文件里发布。并且Spring所需的处理开销也是微不足道的。
控制反转
Spring通过一种称作控制反转的技术促进了低耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
面向切面
Spring提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
容器
Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
框架
Spring可以将简单的组件配置、组合成为复杂的应用。在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
MVC
Spring的作用是整合,但不仅仅限于整合,Spring 框架可以被看做是一个企业解决方案级别的框架。客户端发送请求,服务器控制器(由DispatcherServlet实现的)完成请求的转发,控制器调用一个用于映射的类HandlerMapping,该类用于将请求映射到对应的处理器来处理请求。HandlerMapping 将请求映射到对应的处理器Controller(相当于Action)在Spring 当中如果写一些处理器组件,一般实现Controller 接口,在Controller 中就可以调用一些Service 或DAO 来进行数据操作 ModelAndView 用于存放从DAO 中取出的数据,还可以存放响应视图的一些数据。 如果想将处理结果返回给用户,那么在Spring 框架中还提供一个视图组件ViewResolver,该组件根据Controller 返回的标示,找到对应的视图,将响应response 返回给用户。
spring 特点
- 方便解耦,简化开发
通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合。有了Spring,用户不必再为单实例模式类、属性文件解析等这些很底层的需求编写代码,可以更专注于上层的应用。 - AOP编程的支持
通过Spring提供的AOP功能,方便进行面向切面的编程,许多不容易用传统OOP实现的功能可以通过AOP轻松应付。 - 声明式事务的支持
在Spring中,我们可以从单调烦闷的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。 - 方便程序的测试
可以用非容器依赖的编程方式进行几乎所有的测试工作,在Spring里,测试不再是昂贵的操作,而是随手可做的事情。例如:Spring对Junit4支持,可以通过注解方便的测试Spring程序。 - 方便集成各种优秀框架
Spring不排斥各种优秀的开源框架,相反,Spring可以降低各种框架的使用难度,Spring提供了对各种优秀框架(如Struts,Hibernate、Hessian、Quartz)等的直接支持。 - 降低Java EE API的使用难度
Spring对很多难用的Java EE API(如JDBC,JavaMail,远程调用等)提供了一个薄薄的封装层,通过Spring的简易封装,这些Java EE API的使用难度大为降低。 - Java 源码是经典学习范例
Spring的源码设计精妙、结构清晰、匠心独运,处处体现着大师对Java设计模式灵活运用以及对Java技术的高深造诣。Spring框架源码无疑是Java技术的最佳实践范例。如果想在短时间内迅速提高自己的Java技术水平和应用开发水平,学习和研究Spring源码将会使你收到意想不到的效果。
Spring 优点
- 低侵入式设计,代码污染极低
- 独立于各种应用服务器,基于Spring框架的应用,可以真正实现Write Once,Run Anywhere的承诺
- Spring的DI机制降低了业务对象替换的复杂性,提高了组件之间的解耦
- Spring的AOP支持允许将一些通用任务如安全、事务、日志等进行集中式管理,从而提供了更好的复用
- Spring的ORM和DAO提供了与第三方持久层框架的良好整合,并简化了底层的数据库访问
- Spring并不强制应用完全依赖于Spring,开发者可自由选用Spring框架的部分或全部
基本框架
Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring 模块构建在核心容器之上,核心容器定义了创建、配置和管理 bean 的方式。组成Spring框架的每个模块(或组件)都可以单独存在,或者与其他一个或多个模块联合实现。

核心容器:
核心容器提供 Spring 框架的基本功能(Spring Core)。核心容器的主要组件是 BeanFactory,它是工厂模式的实现。BeanFactory 使用控制反转(IOC) 模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。
Spring 上下文:
Spring 上下文是一个配置文件,向 Spring框架提供上下文信息。Spring 上下文包括企业服务,例如JNDI、EJB、电子邮件、国际化、校验和调度功能。
Spring AOP:
通过配置管理特性,Spring AOP 模块直接将面向切面的编程功能集成到了 Spring 框架中。所以,可以很容易地使 Spring 框架管理的任何对象支持AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
Spring DAO:
JDBCDAO抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理和不同数据库供应商抛出的错误消息。异常层次结构简化了错误处理,并且极大地降低了需要编写的异常代码数量(例如打开和关闭连接)。Spring DAO 的面向 JDBC 的异常遵从通用的 DAO 异常层次结构。
Spring ORM:
Spring 框架插入了若干个ORM框架,从而提供了 ORM 的对象关系工具,其中包括JDO、Hibernate和iBatisSQL Map。所有这些都遵从 Spring 的通用事务和 DAO 异常层次结构。
Spring Web 模块:
Web 上下文模块建立在应用程序上下文模块之上,为基于 Web 的应用程序提供了上下文。所以,Spring框架支持与 Jakarta Struts 的集成。Web 模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
Spring MVC 框架:
MVC框架是一个全功能的构建 Web应用程序的 MVC 实现。通过策略接口,MVC框架变成为高度可配置的,MVC 容纳了大量视图技术,其中包括 JSP、Velocity、Tiles、iText 和 POI。模型由javabean构成,存放于Map;视图是一个接口,负责显示模型;控制器表示逻辑代码,是Controller的实现。Spring框架的功能可以用在任何J2EE服务器中,大多数功能也适用于不受管理的环境。Spring 的核心要点是:支持不绑定到特定 J2EE服务的可重用业务和数据访问对象。毫无疑问,这样的对象可以在不同J2EE 环境(Web 或EJB)、独立应用程序、测试环境之间重用。
控制反转和依赖注入
IOC
什么是IOC
Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”。
谁控制谁,控制什么:
传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建;
谁控制谁:IoC 容器控制了对象
控制什么:主要控制了外部资源获取(不只是对象,包括比如文件等)。
为何是反转,哪些方面反转了:
有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;
为何是反转:因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转
哪些方面反转了:依赖对象的获取被反转了。
DI
什么是DI
DI—Dependency Injection,即“依赖注入”:是组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”。
谁依赖于谁:当然是应用程序依赖于IoC容器;
为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IoC和DI由什么关系呢?其实它们是同一个概念不同角度的描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
依赖注入的三种实现方式
- 构造方法注入
- Setter方式注入
- 接口注入
Spring IoC有什么好处呢? - Mingqi的回答 - 知乎
依赖倒置原则——把原本的高层建筑依赖底层建筑“倒置”过来,变成底层建筑依赖高层建筑。高层建筑决定需要什么,底层去实现这样的需求,但是高层并不用管底层是怎么实现的。这样就不会出现“牵一发动全身”的情况。
控制反转(Inversion of Control) 就是依赖倒置原则的一种代码设计的思路。具体采用的方法就是所谓的依赖注入(Dependency Injection)。
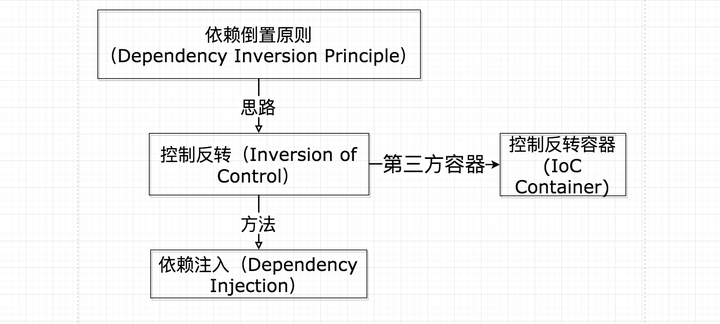
AOP
什么是AOP
AOP,Aspect Orient Programming,即面向切面编程。是对OOP(Object Orient Programming)的一种补充。
AOP 术语
通知(Advice)
通知是织入到目标类连接点上的一段程序代码,在Spring中,通知除用于描述一段程序代码外,还拥有另一个和连接点相关的信息,这便是执行点的方位。结合执行点方位信息和切点信息,我们就可以找到特定的连接点。
连接点(JoinPoint)
即通知具体执行的地方,Spring仅支持方法的连接点,即仅能在方法调用前、方法调用后、方法抛出异常时以及方法调用前后这些程序执行点织入通知。连接点由两个信息确定:第一是用方法表示的程序执行点;第二是用相对点表示的方位。
切点(Pointcut)
每个程序类都拥有多个连接点,如一个拥有两个方法的类,这两个方法都是连接点,即连接点是程序类中客观存在的事物。AOP通过“切点”定位特定的连接点。连接点相当于数据库中的记录,而切点相当于查询条件。切点和连接点不是一对一的关系,一个切点可以匹配多个连接点。在Spring中,切点通过org.springframework.aop.Pointcut接口进行描述,它使用类和方法作为连接点的查询条件,Spring AOP的规则解析引擎负责切点所设定的查询条件,找到对应的连接点。其实确切地说,不能称之为查询连接点,因为连接点是方法执行前、执行后等包括方位信息的具体程序执行点,而切点只定位到某个方法上,所以如果希望定位到具体连接点上,还需要提供方位信息。
切面(Aspect)
切面是通知和切点的结合。现在发现了吧,没连接点什么事情,连接点就是为了让你好理解切点,搞出来的,明白这个概念就行了。通知说明了干什么和什么时候干(什么时候通过方法名中的before,after,around等就能知道),而切点说明了在哪干(指定到底是哪个方法),这就是一个完整的切面定义。引入(introduction)
引介是一种特殊的增强,它为类添加一些属性和方法。这样,即使一个业务类原本没有实现某个接口,通过AOP的引介功能,我们可以动态地为该业务类添加接口的实现逻辑,让业务类成为这个接口的实现类。目标(target)
增强逻辑的织入目标类。如果没有AOP,目标业务类需要自己实现所有逻辑,而在AOP的帮助下,目标业务类只实现那些非横切逻辑的程序逻辑,而性能监视和事务管理等这些横切逻辑则可以使用AOP动态织入到特定的连接点上。代理(proxy)
一个类被AOP织入增强后,就产出了一个结果类,它是融合了原类和增强逻辑的代理类。织入(weaving)
织入是将增强添加到目标类具体连接点上的过程。AOP像一台织布机,将目标类、通知或引入通过AOP这台织布机天衣无缝地编织到一起。AOP有三种织入方式:
a、编译期织入,这要求使用特殊的Java编译器。
b、类装载期织入,这要求使用特殊的类装载器。
c、动态代理织入,在运行期为目标类添加增强生成子类的方式。
Spring采用动态代理织入,而AspectJ采用编译期织入和类装载期织入。
五种通知类型
- 前置通知[Before advice]:在连接点前面执行,前置通知不会影响连接点的执行,除非此处抛出异常。
- 正常返回通知[After returning advice]:在连接点正常执行完成后执行,如果连接点抛出异常,则不会执行。
- 异常返回通知[After throwing advice]:在连接点抛出异常后执行。
- 返回通知[After (finally) advice]:在连接点执行完成后执行,不管是正常执行完成,还是抛出异常,都会执行返回通知中的内容。
- 环绕通知[Around advice]:环绕通知围绕在连接点前后,比如一个方法调用的前后。这是最强大的通知类型,能在方法调用前后自定义一些操作。环绕通知还需要负责决定是继续处理join point(调用ProceedingJoinPoint的proceed方法)还是中断执行。
切点表达式
标准的Aspectj Aop的pointcut的表达式类型是很丰富的,但是Spring Aop只支持其中的9种,外加Spring Aop自己扩充的一种一共是10种类型的表达式,分别如下。
execution:一般用于指定方法的执行,用的最多。
within:指定某些类型的全部方法执行,也可用来指定一个包。
this:Spring Aop是基于代理的,生成的bean也是一个代理对象,this就是这个代理对象,当这个对象可以转换为指定的类型时,对应的切入点就是它了,Spring Aop将生效。
target:当被代理的对象可以转换为指定的类型时,对应的切入点就是它了,Spring Aop将生效。
args:当执行的方法的参数是指定类型时生效。
@target:当代理的目标对象上拥有指定的注解时生效。
@args:当执行的方法参数类型上拥有指定的注解时生效。
@within:与@target类似,看官方文档和网上的说法都是@within只需要目标对象的类或者父类上有指定的注解,则@within会生效,而@target则是必须是目标对象的类上有指定的注解。而根据笔者的测试这两者都是只要目标类或父类上有指定的注解即可。
@annotation:当执行的方法上拥有指定的注解时生效。
bean:当调用的方法是指定的bean的方法时生效。
execution
由于Spring切面粒度最小是达到方法级别,而execution表达式可以用于明确指定方法返回类型,类名,方法名和参数名等与方法相关的部件,并且在Spring中,大部分需要使用AOP的业务场景也只需要达到方法级别即可,因而execution表达式的使用是最为广泛的。如下是execution表达式的语法:
1 | execution(modifiers-pattern? ret-type-pattern declaring-type-pattern?name-pattern(param-pattern) throws-pattern?) |
这里问号表示当前项可以有也可以没有,其中各项的语义如下:
- modifiers-pattern:方法的可见性,如public,protected;
- ret-type-pattern:方法的返回值类型,如int,void等;
- declaring-type-pattern:方法所在类的全路径名,如com.spring.Aspect;
- name-pattern:方法名类型,如buisinessService();
- param-pattern:方法的参数类型,如java.lang.String;
- throws-pattern:方法抛出的异常类型,如java.lang.Exception;
如下是一个使用execution表达式的例子:
1 | execution(public * com.spring.service.BusinessObject.businessService(java.lang.String,..)) |
上述切点表达式将会匹配使用public修饰,返回值为任意类型,并且是com.spring.BusinessObject类中名称为businessService的方法,方法可以有多个参数,但是第一个参数必须是java.lang.String类型的方法。上述示例中我们使用了..通配符,关于通配符的类型,主要有两种:
* 通配符:该通配符主要用于匹配单个单词,或者是以某个词为前缀或后缀的单词。
如下示例表示返回值为任意类型,在com.spring.service.BusinessObject类中,并且参数个数为零的方法:
1 | execution(* com.spring.service.BusinessObject.*()) |
下述示例表示返回值为任意类型,在com.spring.service包中,以Business为前缀的类,并且是类中参数个数为零方法:
1 | execution(* com.spring.service.Business*.*()) |
- .. 通配符:该通配符表示0个或多个项,主要用于declaring-type-pattern和param-pattern中,如果用于declaring-type-pattern中,则表示匹配当前包及其子包,如果用于param-pattern中,则表示匹配0个或多个参数。
如下示例表示匹配返回值为任意类型,并且是com.spring.service包及其子包下的任意类的名称为businessService的方法,而且该方法不能有任何参数:
1 | execution(* com.spring.service..*.businessService()) |
这里需要说明的是,包路径service...businessService()中的..应该理解为延续前面的service路径,表示到service路径为止,或者继续延续service路径,从而包括其子包路径;后面的.businessService(),这里的*表示匹配一个单词,因为是在方法名前,因而表示匹配任意的类。
如下示例是使用..表示任意个数的参数的示例,需要注意,表示参数的时候可以在括号中事先指定某些类型的参数,而其余的参数则由..进行匹配:
1 | execution(* com.spring.service.BusinessObject.businessService(java.lang.String,..)) |
AOP应用
- 日志记录,跟踪,优化和监控
- 事务的处理
- 持久化
- 性能的优化
- 资源池,如数据库连接池的管理
- 系统统一的认证、权限管理等
- 应用系统的异常捕捉及处理
AOP的实现
AOP 的实现技术主要有Spring AOP和AspectJ。
- AspectJ
AspectJ的底层技术是静态代理,即用一种AspectJ支持的特定语言编写切面,通过一个命令来编译,生成一个新的代理类,该代理类增强了业务类,这是在编译时增强,相对于下面说的运行时增强,编译时增强的性能更好。
- Spring AOP
Spring AOP采用的是动态代理,在运行期间对业务方法进行增强,所以不会生成新类,对于动态代理技术,Spring AOP提供了对JDK动态代理的支持以及CGLib的支持。
Spring MVC 执行流程
早期的 MVC 模型(Model2)就像下图这样:

首先用户的请求会到达 Servlet,然后根据请求调用相应的 Java Bean,并把所有的显示结果交给 JSP 去完成,这样的模式我们就称为 MVC 模式。
- M 代表模型(Model)
模型是什么呢? 模型就是数据,就是 dao,bean - V 代表视图(View)
视图是什么呢? 就是网页, JSP,用来展示模型中的数据 - C 代表控制器(controller)
控制器是什么? 控制器的作用就是把不同的数据(Model),显示在不同的视图(View)上,Servlet 扮演的就是这样的角色。
Spring MVC 的架构
为解决持久层中一直未处理好的数据库事务的编程,又为了迎合 NoSQL 的强势崛起,Spring MVC 给出了方案:

传统的模型层被拆分为了业务层(Service)和数据访问层(DAO,Data Access Object)。在 Service 下可以通过 Spring 的声明式事务操作数据访问层,而在业务层上还允许我们访问 NoSQL ,这样就能够满足异军突起的 NoSQL 的使用了,它可以大大提高互联网系统的性能。
特点:
- 结构松散,几乎可以在 Spring MVC 中使用各类视图
- 松耦合,各个模块分离
- 与 Spring 无缝集成
SpringMVC框架是一个基于请求驱动的Web框架,并且使用了‘前端控制器’模型来进行设计,再根据‘请求映射规则’分发给相应的页面控制器进行处理。
(一)整体流程
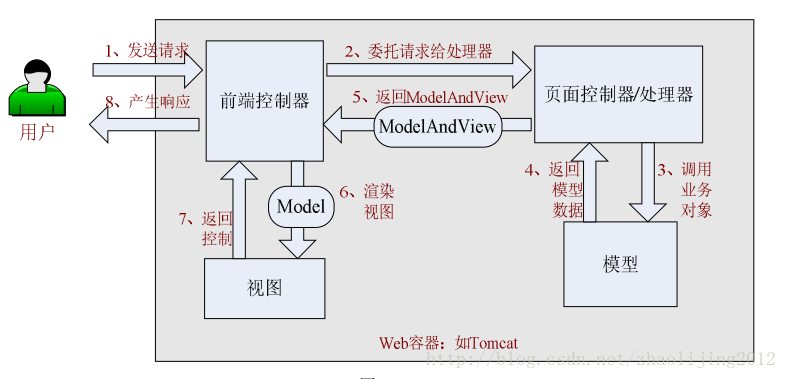
具体步骤:
1、 首先用户发送请求————>前端控制器,前端控制器根据请求信息(如 URL)来决定选择哪一个页面控制器进行处理并把请求委托给它,即以前的控制器的控制逻辑部分;图 2-1 中的 1、2 步骤;
2、 页面控制器接收到请求后,进行功能处理,首先需要收集和绑定请求参数到一个对象,这个对象在 Spring Web MVC 中叫命令对象,并进行验证,然后将命令对象委托给业务对象进行处理;处理完毕后返回一个 ModelAndView(模型数据和逻辑视图名);图 2-1 中的 3、4、5 步骤;
3、 前端控制器收回控制权,然后根据返回的逻辑视图名,选择相应的视图进行渲染,并把模型数据传入以便视图渲染;图 2-1 中的步骤 6、7;
4、 前端控制器再次收回控制权,将响应返回给用户,图 2-1 中的步骤 8;至此整个结束。(二)核心流程
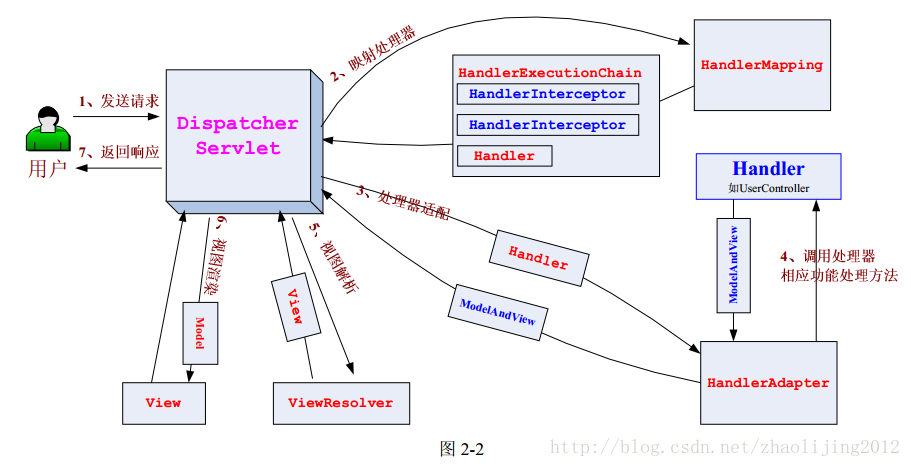
具体步骤:
- 用户发送请求到前端控制器(DispatcherServlet)
- 前端控制器请求处理器映射器 HandlerMapping 来查找 Handler,可以根据 xml 配置、注解来进行查找
- 处理器映射器 HandlerMapping 向前端控制器返回 Handler
- 前端控制器调用处理器适配器 HandlerAdapter 去执行 Handler
- 处理器适配器 HandlerAdapter 去执行 Handler
- Handler 执行完给适配器返回 ModelAndView
- 处理器适配器 HandlerAdapter 向前端控制器返回 ModelAndView,ModelAndView 是 Spring MVC 框架的一个底层对象,包括了 Model 和 View
- 前端控制器请求视图解析器进行视图解析,根据逻辑视图名解析成真正的试图(JSP)
- 视图解析器向前端控制器放回 View
- 前端控制器进行试图渲染,视图渲染就是将数据(在 ModelAndView 中)填充到 request 域
- 前端控制器向用户响应结果
主要组件:
前端控制器 DispatcherServlet(不需要程序员开发)
作用:接收请求,相应结果。相当于转发器,中央处理器,有了 DispatcherServlet 减少了其他组件之间的耦合度。
处理器映射器 HandlerMapping(不需要程序员开发)
作用:根据 url 查找 Handler,可以根据 xml 配置,也可以根据注解
处理器适配器 HandlerAdapter
作用:按照特定的规则(HandlerAdapter 要求的规则)去执行 Handler
处理器 Handler(需要程序员开发)
注意:编写 Handler(即我们平时说的 Controller)时要按照 HandlerAdapter 的要求去做,这样适配器才能正确的执行 Handler
视图解析器 ViewResolver(不需要程序员开发)
作用:进行视图解析,根据逻辑视图名解析成真正的视图(View)
视图 View(需要程序员开发 jsp)
View 是一个接口,实现类支持不同的 View 类型(jsp,freemaker,pdf…)
(三)总结核心开发步骤
1、 DispatcherServlet 在 web.xml 中的部署描述,从而拦截请求到 Spring Web MVC
2、 HandlerMapping 的配置,从而将请求映射到处理器
3、 HandlerAdapter 的配置,从而支持多种类型的处理器
4、 ViewResolver 的配置,从而将逻辑视图名解析为具体视图技术
5、 处理器(页面控制器)的配置,从而进行功能处理
SpringMVC与Struts2区别与比较总结
1、Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url,而struts2的架构实现起来要费劲,因为Struts2中Action的一个方法可以对应一个url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
2、由上边原因,SpringMVC的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而Struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码 读程序时带来麻烦,每次来了请求就创建一个Action,一个Action对象对应一个request上下文。
3、由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
4、 拦截器实现机制上,Struts2有以自己的interceptor机制,SpringMVC用的是独立的AOP方式,这样导致Struts2的配置文件量还是比SpringMVC大。
5、SpringMVC的入口是servlet,而Struts2是filter(这里要指出,filter和servlet是不同的。以前认为filter是servlet的一种特殊),这就导致了二者的机制不同,这里就牵涉到servlet和filter的区别了。
6、SpringMVC集成了Ajax,使用非常方便,只需一个注解@ResponseBody就可以实现,然后直接返回响应文本即可,而Struts2拦截器集成了Ajax,在Action中处理时一般必须安装插件或者自己写代码集成进去,使用起来也相对不方便。
7、SpringMVC验证支持JSR303,处理起来相对更加灵活方便,而Struts2验证比较繁琐,感觉太烦乱。
8、Spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高(当然Struts2也可以通过不同的目录结构和相关配置做到SpringMVC一样的效果,但是需要xml配置的地方不少)。
9、 设计思想上,Struts2更加符合OOP的编程思想, SpringMVC就比较谨慎,在servlet上扩展。
10、SpringMVC开发效率和性能高于Struts2。
11、SpringMVC可以认为已经100%零配置。
Spring Boot
Spring Boot 的三种启动方式
IDE 运行Application这个类的main方法
在Spring Boot应用的根目录下运行
mvn spring-boot:run使用 mvn install 生成 jar后运行
1
2
3
4先到项目根目录
mvn install
cd target
java -jar xxxx.jar
版本控制
GIT 常用命令
项目管理
Maven 常用命令
mvn compile
编译项目
mvn package
打包
mvn package -Dmaven.test.skip=ture
打包时跳过测试
mvn clean package -Dmaven.test.skip=true
清除以前的 jar 包后重新打包,跳过测试类
mvn install
安装当前工程的输出文件到本地仓库
mvn clean
清除项目目录中的生成结果
package 与 install 命令的区别
package 是把 jar 打到本项目的 target 目录下,而 install 是把 target 下的 jar 安装到本地仓库,供其他项目使用。
正则表达式
非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\‘ 匹配 “",而 ‘(‘ 则匹配 “(“。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 ^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
定位符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
Java 正则表达式
在其他语言中,\\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如Perl),一个反斜杠 \ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \\ 代表其他语言中的一个 \,这也就是为什么表示一位数字的正则表达式是 \\d,而表示一个普通的反斜杠是 \\\\。
算法
IP 网段黑名单过滤
问题:给出一个网段,该网段的地址都属于黑名单,验证其他ip地址是否属于黑名单
思路:要想到通过二进制的位运算来实现:
ip & 子网掩码 = 网段
对于一个 CIDR 的ip地址,怎么得到子网掩码?
先得到CIDR中的网络号位数netCount,然后:
int mask = 0xFFFFFFFF << (32 - netCount);
这样就能得到子网掩码
1 | public class IPFilter { |
密码加密
任何应用考虑到安全,绝不能明文的方式保存密码。密码应该通过哈希算法进行加密。有很多标准的算法比如SHA或者MD5,结合salt(盐)是一个不错的选择。 Spring Security提供了BCryptPasswordEncoder类,实现Spring的PasswordEncoder接口使用BCrypt强哈希方法来加密密码。
BCrypt强哈希方法 每次加密的结果都不一样。
(1)tensquare_user工程的pom引入依赖
1 | <dependency> |
(2)添加配置类 (资源/工具类中提供)
我们在添加了spring security依赖后,所有的地址都被spring security所控制了,我们目前只是需要用到BCrypt密码加密的部分,所以我们要添加一个配置类,配置为所有地址都可以匿名访问。
1 | /** |
(3)修改tensquare_user工程的Application, 配置bean
1 |
|
管理员密码加密
新增管理员密码加密
修改tensquare_user工程的AdminService
1 |
|
管理员登陆密码校验
(1)AdminDao增加方法定义
1 | public Admin findByLoginname(String loginname); |
(2)AdminService增加方法
1 | /** |
(3)AdminController增加方法
1 | /** |
用户密码加密
用户注册密码加密
(4)修改tensquare_user工程的UserService 类,引入BCryptPasswordEncoder
1 |
|
(5)修改tensquare_user工程的UserService 类的add方法,添加密码加密的逻辑
1 | /** |
用户登陆密码判断
(1)修改tensquare_user工程的UserDao接口,增加方法定义
1 | /** |
(2)修改tensquare_user工程的UserService 类,增加方法
1 | /** |
(4)修改tensquare_user工程的UserController类,增加login方法
1 | /** |
Spring Boot
简介
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
优缺点
优点:
独立运行
Spring Boot而且内嵌了各种servlet容器,Tomcat、Jetty等,现在不再需要打成war包部署到容器中,Spring Boot只要打成一个可执行的jar包就能独立运行,所有的依赖包都在一个jar包内。
简化配置
spring-boot-starter-web启动器自动依赖其他组件,简少了maven的配置。
1
2
3
4
5
6
7
8
9
10+- org.springframework.boot:spring-boot-starter-web:jar:1.5.6.RELEASE:compile
+- org.springframework.boot:spring-boot-starter-tomcat:jar:1.5.6.RELEASE:compile
| +- org.apache.tomcat.embed:tomcat-embed-core:jar:8.5.16:compile
| +- org.apache.tomcat.embed:tomcat-embed-el:jar:8.5.16:compile
| \- org.apache.tomcat.embed:tomcat-embed-websocket:jar:8.5.16:compile
+- org.hibernate:hibernate-validator:jar:5.3.5.Final:compile
| +- javax.validation:validation-api:jar:1.1.0.Final:compile
| +- org.jboss.logging:jboss-logging:jar:3.3.1.Final:compile
| \- com.fasterxml:classmate:jar:1.3.3:compile
\- org.springframework:spring-webmvc:jar:4.3.10.RELEASE:compile自动配置
Spring Boot能根据当前类路径下的类、jar包来自动配置bean,如添加一个spring-boot-starter-web启动器就能拥有web的功能,无需其他配置。
无代码生成和XML配置
Spring Boot配置过程中无代码生成,也无需XML配置文件就能完成所有配置工作,这一切都是借助于条件注解完成的,这也是Spring4.x的核心功能之一。
应用监控
Spring Boot提供一系列端点可以监控服务及应用,做健康检测。
缺点:
核心配置文件
SpringBoot配置文件可以放置在多种路径下,不同路径下的配置优先级有所不同。
可放置目录(优先级从高到低)
- file:./config/ (当前项目路径config目录下);
- file:./ (当前项目路径下);
- classpath:/config/ (类路径config目录下);
- classpath:/ (类路径config下).
优先级由高到底,高优先级的配置会覆盖低优先级的配置;SpringBoot会从这四个位置全部加载配置文件并互补配置;我们可以从ConfigFileApplicationListener这类便可看出,其中DEFAULT_SEARCH_LOCATIONS属性设置了加载的目录:
1 | private static final String DEFAULT_SEARCH_LOCATIONS = "classpath:/,classpath:/config/,file:./,file:./config/"; |
读取自定义属性
使用@Value方式(常用)
使用 @ConfigurationProperties 把相关的配置,注入到某个配置类中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
(prefix = "spring.datasource")
public class MyDataSource {
private String url;
private String username;
private String password;
private String driverClassName;
// 提供Setter 和 Getter 方法
}注意:你现在能大概猜到为什么SpringBoot 应用能够根据默认属性(默认属性列表)来自动配置数据源了吧?因为内置的数据源类
DataSourceProperties通过@ConfigurationProperties(prefix = "spring.datasource")读取到了我们在配置文件填写的数据源信息,然后通过DataSourceAutoConfiguration创建了数据源Bean和进行了相关初始化配置。使用Environment方式
1
2
3
4
5
6
7
8
9
10
public class WebController {
private Environment env;
("/index3")
public String index3(){
return "方式三:"+env.getProperty("test.msg");
}
}
读取自定义配置文件的属性
1 |
|
注意:springboot 1.5版本以后@ConfigurationProperties没有了location属性,使用@PropertySource来指定配置文件位置
Spring Boot 多环境配置
使用yml文件(分为单文档和多文档两种方式)
首先,我们先创建一个名为 application.yml的属性文件,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42server:
port: 8080
my:
name: demo
spring:
profiles:
active: dev
#development environment
spring:
profiles: dev
server:
port: 8160
my:
name: ricky
#test environment
spring:
profiles: test
server:
port: 8180
my:
name: test
#production environment
spring:
profiles: prod
server:
port: 8190
my:
name: prodapplication.yml文件分为四部分,使用 — 来作为分隔符,第一部分通用配置部分,表示三个环境都通用的属性, 后面三段分别为:开发,测试,生产,用spring.profiles指定了一个值(开发为dev,测试为test,生产为prod),这个值表示该段配置应该用在哪个profile里面。
如果我们是本地启动,在通用配置里面可以设置调用哪个环境的profil,也就是第一段的spring.profiles.active=XXX, 其中XXX是后面3段中spring.profiles对应的value,通过这个就可以控制本地启动调用哪个环境的配置文件,例如:
1
2
3spring:
profiles:
active: dev表示默认 加载的就是开发环境的配置,如果dev换成test,则会加载测试环境的属性,以此类推。
注意:如果spring.profiles.active没有指定值,那么只会使用没有指定spring.profiles文件的值,也就是只会加载通用的配置。
启动参数
如果是部署到服务器的话,我们正常打成jar包,启动时通过 –spring.profiles.active=xxx 来控制加载哪个环境的配置,完整命令如下:1
2
3java -jar xxx.jar --spring.profiles.active=test 表示使用测试环境的配置
java -jar xxx.jar --spring.profiles.active=prod 表示使用生产环境的配置使用多个yml配置文件进行配置属性文件
我们也可以使用多个yml来配置属性,将于环境无关的属性放置到application.yml文件里面;通过与配置文件相同的命名规范,创建application-{profile}.yml文件 存放不同环境特有的配置,例如 application-test.yml 存放测试环境特有的配置属性,application-prod.yml 存放生产环境特有的配置属性。通过这种形式来配置多个环境的属性文件,在application.yml文件里面spring.profiles.active=xxx来指定加载不同环境的配置,如果不指定,则默认只使用application.yml属性文件,不会加载其他的profiles的配置。
使用properties文件
如果使用application.properties进行多个环境的配置,原理跟使用多个yml配置文件一致,创建application-{profile}.properties文件 存放不同环境特有的配置,将于环境无关的属性放置到application.properties文件里面,并在application.properties文件中通过spring.profiles.active=xxx 指定加载不同环境的配置。如果不指定,则默认加载application.properties的配置,不会加载带有profile的配置。Maven Profile
如果我们使用的是构建工具是Maven,也可以通过Maven的profile特性来实现多环境配置打包。
pom.xml配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49<profiles>
<!--开发环境-->
<profile>
<id>dev</id>
<properties>
<build.profile.id>dev</build.profile.id>
</properties>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
</profile>
<!--测试环境-->
<profile>
<id>test</id>
<properties>
<build.profile.id>test</build.profile.id>
</properties>
</profile>
<!--生产环境-->
<profile>
<id>prod</id>
<properties>
<build.profile.id>prod</build.profile.id>
</properties>
</profile>
</profiles>
<build>
<finalName>${project.artifactId}</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/resources.${build.profile.id}</directory>
<filtering>false</filtering>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<classifier>exec</classifier>
</configuration>
</plugin>
</plugins>
</build>通过执行
mvn clean package -P ${profile}来指定使用哪个profile。
SpringBoot几个常用的注解
- @RestController和@Controller指定一个类,作为控制器的注解
- @RequestMapping方法级别的映射注解,这一个用过Spring MVC的小伙伴相信都很熟悉
- @EnableAutoConfiguration和@SpringBootApplication是类级别的注解,根据maven依赖的jar来自动配置,只要引入了spring-boot-starter-web的依赖,默认会自动配置Spring MVC和tomcat容器
- @Configuration类级别的注解,一般这个注解,我们用来标识main方法所在的类,完成元数据bean的初始化。
- @ComponentScan类级别的注解,自动扫描加载所有的Spring组件包括Bean注入,一般用在main方法所在的类上
- @ImportResource类级别注解,当我们必须使用一个xml的配置时,使用@ImportResource和@Configuration来标识这个文件资源的类。
- @Autowired注解,一般结合@ComponentScan注解,来自动注入一个Service或Dao级别的Bean
- @Component类级别注解,用来标识一个组件,比如我自定了一个filter,则需要此注解标识之后,Spring Boot才会正确识别。
过滤器
过滤器Filter,是Servlet的的一个实用技术了。可通过过滤器,对请求进行拦截,比如读取session判断用户是否登录、判断访问的请求URL是否有访问权限(黑白名单)等。主要还是可对请求进行预处理。
在springboot有两种实现过滤器功能:
-
@WebFilter时Servlet3.0新增的注解,原先实现过滤器,需要在web.xml中进行配置,而现在通过此注解,启动启动时会自动扫描自动注册。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//注册器名称为customFilter,拦截的url为所有
(filterName="customFilter",urlPatterns={"/*"})
4j
public class CustomFilter implements Filter{
public void init(FilterConfig filterConfig) throws ServletException {
log.info("filter 初始化");
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
// TODO Auto-generated method stub
log.info("doFilter 请求处理");
//对request、response进行一些预处理
// 比如设置请求编码
// request.setCharacterEncoding("UTF-8");
// response.setCharacterEncoding("UTF-8");
//TODO 进行业务逻辑
//链路 直接传给下一个过滤器
chain.doFilter(request, response);
}
public void destroy() {
log.info("filter 销毁");
}
}
-
FilterRegistrationBean是springboot提供的,此类提供setOrder方法,可以为filter设置排序值,让spring在注册web filter之前排序后再依次注册。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public FilterRegistrationBean filterRegistrationBean() {
FilterRegistrationBean registration = new FilterRegistrationBean();
//当过滤器有注入其他bean类时,可直接通过@bean的方式进行实体类过滤器,这样不可自动注入过滤器使用的其他bean类。
//当然,若无其他bean需要获取时,可直接new CustomFilter(),也可使用getBean的方式。
registration.setFilter(customFilter());
//过滤器名称
registration.setName("customFilter");
//拦截路径
registration.addUrlPatterns("/*");
//设置顺序
registration.setOrder(10);
return registration;
}
public Filter customFilter() {
return new CustomFilter();
}
拦截器
1 | 4j |
1 |
|
监听器
Listeeshi是servlet规范中定义的一种特殊类。用于监听servletContext、HttpSession和servletRequest等域对象的创建和销毁事件。监听域对象的属性发生修改的事件。用于在事件发生前、发生后做一些必要的处理。一般是获取在线人数等业务需求。
1 |
|
公共异常处理
为了使我们的代码更容易维护,我们创建一个类集中处理异常
在om.tensquare.user.controller包下创建公共异常处理类BaseExceptionHandler
1 | /** |
面试常见问题
什么是Spring Boot
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。Spring Boot 其实不是什么新的框架,它默认配置了很多框架的使用方式,就像 maven 整合了所有的 jar 包,Spring Boot 整合了所有的框架(不知道这样比喻是否合适)。
spring大家都知道,boot是启动的意思。所以,spring boot其实就是一个启动spring项目的一个工具而已。从最根本上来讲,Spring Boot就是一些库的集合,它能够被任意项目的构建系统所使用。
以前在写spring项目的时候,要配置各种xml文件,还记得曾经被ssh框架支配的恐惧。随着spring3,spring4的相继推出,约定大于配置逐渐成为了开发者的共识,大家也渐渐的从写xml转为写各种注解,在spring4的项目里,你甚至可以一行xml都不写。
虽然spring4已经可以做到无xml,但写一个大项目需要茫茫多的包,maven配置要写几百行,也是一件很可怕的事。
现在,快速开发一个网站的平台层出不穷,nodejs,php等虎视眈眈,并且脚本语言渐渐流行了起来(Node JS,Ruby,Groovy,Scala等),spring的开发模式越来越显得笨重。
在这种环境下,spring boot伴随着spring4一起出现了。
Spring Boot、Spring MVC 和 Spring 有什么区别?
我们说到Spring,一般指代的是Spring Framework。纵览Spring的结构,你会发现Spring Framework 本身并未提供太多具体的功能,它主要专注于让你的项目代码组织更加优雅,使其具有极好的灵活性和扩展性,同时又能通过Spring集成业界优秀的解决方案
Spring MVC是Spring的一部分,Spring 出来以后,大家觉得很好用,于是按照这种模式设计了一个 MVC框架(一些用Spring 解耦的组件),主要用于开发WEB应用和网络接口,它是Spring的一个模块,通过Dispatcher Servlet, ModelAndView 和 View Resolver,让应用开发变得很容易。
初期的Spring通过代码加配置的形式为项目提供了良好的灵活性和扩展性,但随着Spring越来越庞大,其配置文件也越来越繁琐,太多复杂的xml文件也一直是Spring被人诟病的地方,特别是近些年其他简洁的WEB方案层出不穷,如基于Python或Node.Js,几行代码就能实现一个WEB服务器,对比起来,大家渐渐觉得Spring那一套太过繁琐,此时,Spring社区推出了Spring Boot,它的目的在于实现自动配置,降低项目搭建的复杂度。
Spring MVC和Spring Boot都属于Spring,Spring MVC 是基于Spring的一个 MVC 框架,而Spring Boot 是基于Spring的一套快速开发整合包。说得更简便一些:Spring 最初利用“工厂模式”(DI)和“代理模式”(AOP)解耦应用组件。大家觉得挺好用,于是按照这种模式搞了一个 MVC框架(一些用Spring 解耦的组件),用于开发 web 应用( SpringMVC )。然后又发现每次开发都写很多样板代码,为了简化工作流程,于是开发出了一些“懒人整合包”(starter),这套就是 Spring Boot。
Spring 、Spring Boot 和 Spring Cloud 的关系
Spring 最初最核心的两大核心功能 Spring Ioc 和 Spring Aop 成就了 Spring,Spring 在这两大核心的功能上不断的发展,才有了 Spring 事务、Spring Mvc 等一系列伟大的产品,最终成就了 Spring 帝国,到了后期 Spring 几乎可以解决企业开发中的所有问题。
Spring Boot 是在强大的 Spring 帝国生态基础上面发展而来,发明 Spring Boot 不是为了取代 Spring ,是为了让人们更容易的使用 Spring 。所以说没有 Spring 强大的功能和生态,就不会有后期的 Spring Boot 火热, Spring Boot 使用约定优于配置的理念,重新重构了 Spring 的使用,让 Spring 后续的发展更有生命力。
Spring Cloud 是一系列框架的有序集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。
Spring 并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过 Spring Boot 风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
根据上面的说明我们可以看出来,Spring Cloud 是为了解决微服务架构中服务治理而提供的一系列功能的开发框架,并且 Spring Cloud 是完全基于 Spring Boot 而开发,Spring Cloud 利用 Spring Boot 特性整合了开源行业中优秀的组件,整体对外提供了一套在微服务架构中服务治理的解决方案。
综上我们可以这样来理解,正是由于 Spring Ioc 和 Spring Aop 两个强大的功能才有了 Spring ,Spring 生态不断的发展才有了 Spring Boot ,使用 Spring Boot 让 Spring 更易用更有生命力,Spring Cloud 是基于 Spring Boot 开发的一套微服务架构下的服务治理方案。
用一组不太合理的包含关系来表达它们之间的关系。
Spring ioc/aop > Spring > Spring Boot > Spring Cloud
Spring Boot 的核心配置文件有哪几个?它们的区别是什么?
Spring Boot 的核心配置文件是 application 和 bootstrap 配置文件。
application 配置文件这个容易理解,主要用于 Spring Boot 项目的自动化配置。
boostrap 由父 ApplicationContext 加载,比 applicaton 优先加载
boostrap 里面的属性不能被覆盖
bootstrap 配置文件有以下几个应用场景。
- 使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性;
- 一些加密/解密的场景;
Spring Boot 的配置文件有哪几种格式?它们有什么区别?
.properties 和 .yml,它们的区别主要是书写格式不同。
1).properties
1
app.user.name = javastack
2).yml
1
2
3app:
user:
name: javastack另外,.yml 格式不支持
@PropertySource注解导入配置。Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解 @SpringBootApplication 是 Spring Boot 的核心注解,主要组合了以下 3 个注解:
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
@ComponentScan:Spring组件扫描。不配置默认扫描@SpringBootApplication所在类的同级目录以及它的子目录(这很重要,后面很应用到这个特性)。当然你也可以自己指定要扫描的包目录,例如:
1
(basePackages = "com.lqr.demo1")
开启 Spring Boot 特性有哪几种方式?
1)继承spring-boot-starter-parent项目
2)导入spring-boot-dependencies项目依赖
使用Spring Boot很简单,先添加基础依赖包,有以下两种方式
继承spring-boot-starter-parent项目
1
2
3
4
5<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId
<version>1.5.6.RELEASE</version>
</parent>导入spring-boot-dependencies项目依赖
1
2
3
4
5
6
7
8
9
10
11<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Spring Boot依赖注意点
属性覆盖只对继承有效
Spring Boot依赖包里面的组件的版本都是和当前Spring Boot绑定的,如果要修改里面组件的版本,只需要添加如下属性覆盖即可,但这种方式只对继承有效,导入的方式无效。
1
2
3<properties>
<slf4j.version>1.7.25<slf4j.version>
</properties>如果导入的方式要实现版本的升级,达到上面的效果,这样也可以做到,把要升级的组件依赖放到Spring Boot之前。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<dependencyManagement>
<dependencies>
<!-- Override Spring Data release train provided by Spring Boot -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-releasetrain</artifactId>
<version>Fowler-SR2</version>
<scope>import</scope>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>需要注意,要修改Spring Boot的依赖组件版本可能会造成不兼容的问题。
资源文件过滤问题
有时候,我们的资源文件中设置的值,只能在构建项目的时候才会被指定。为了完成这个需求,在Maven中可以为这个需要在构建的时候才可以确定值的位置,放置一个占位符,来表示这个未来会被设置的值。通过使用
${property}的方式指定。其中property可以是指定在pom.xml文件中的值,或者是在setting.xml文件中设置的值,或者是放在项目的filters目录(参考Maven的项目目录结构)下的外部的properties文件中的值,亦或是一个系统属性。这种方式在Maven中称为对资源文件的过滤。使用继承Spring Boot时,如果要使用 Maven resource filter 过滤资源文件时,资源文件里面的占位符为了使${}和Spring Boot区别开来,此时要用@…@包起来,不然无效。另外,@…@占位符在yaml文件编辑器中编译报错,所以使用继承方式有诸多问题,坑要慢慢趟。
Spring Boot 自动配置原理是什么?
Spring Boot的自动配置注解是@EnableAutoConfiguration,
@EnableAutoConfiguration注解核心点是@Import的自动配置导入选择器类AutoConfigurationImportSelector。1
2
3
4
5
6
7
8
9
10
11
12
13({ElementType.TYPE})
(RetentionPolicy.RUNTIME)
({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class AutoConfigurationImportSelector implements DeferredImportSelector, ...{
protected List<String> getCandidateConfigurations(
AnnotationMetadata metadata,
AnnotationAttributes attributes) {
List<String> configurations =
SpringFactoriesLoader.loadFactoryNames(
this.getSpringFactoriesLoaderFactoryClass(),
this.getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you are using a custom packaging, make sure that file is correct.");
return configurations;
}
}AutoConfigurationImportSelector通过SpringFactoriesLoader.loadFactoryNames()核心方法读取 ClassPath 目录下面的 META-INF/spring.factories 文件。spring.factories 文件中配置了 Spring Boot 所有的自动配置类的全类名,例如常见的Jpa 自动配置类
JpaRepositoriesAutoConfiguration、WebMvcAutoConfigurationWeb MVC 自动配置类和ServletWebServerFactoryAutoConfiguration容器自动配置类等 。查看Spring Boot自带的自动配置的包:找到 spring-boot-autoconfigure-x.x.x.RELEASE.jar,打开其中的META-INF/spring.factories文件会找到自动配置的映射。当 pom.xml 添加某 Starter 依赖组件的时候,就会自动触发该依赖的默认配置。
你如何理解 Spring Boot 中的 Starters?
Starters可以理解为启动器,它包含了一系列可以集成到应用里面的依赖包,你可以一站式集成 Spring 及其他技术,而不需要到处找示例代码和依赖包。如你想使用 Spring JPA 访问数据库,只要加入 spring-boot-starter-data-jpa 启动器依赖就能使用了。
Spring Boot 提供了很多 “开箱即用” 的 Starter 组件。Starter 组件是可被加载在应用中的 Maven 依赖项。只需要在 Maven 配置中添加对应的依赖配置,即可使用对应的 Starter 组件。例如,添加
spring-boot-starter-web依赖,就可用于构建 REST API 服务,其包含了 Spring MVC 和 Tomcat 内嵌容器等。一个完整的 Starter 组件包括以下两点:
提供自动配置功能的自动配置模块。
提供依赖关系管理功能的组件模块,即封装了组件所有功能,开箱即用。
starter 的 jar 包虽然很小,但它的 pom 文件中却包含了很多。starter 只不过是把我们某一模块,比如web 开发时所需要的所有JAR 包打包好给我们而已。不过它的厉害之处在于,能自动把配置文件搞好,不用我们手动配置。
Spring Boot 支持哪些日志框架?推荐和默认的日志框架是哪个?
常见的日志框架:
JUL(Java Util Logging)
虽然来自于官方,但实现过于简陋。
jboss-logging
自诞生之初就不是为了服务大众
Log4j
Log4j、SLF4j 和 Logback 的作者是同一个人 ceki,作者说 Log4j 太烂,他已经不想改了,重新写了一个升级版的框架,名字就叫 Logback。
Log4j2
Apache 出品的,设计很优秀,但太过于先进,很多框架对其支持不是很好,保不准就会出现一个不大不小的坑。Log4j2 为了追求极致的性能,在框架的设计上存在过度设计的嫌疑。
SLF4J主要是为了给Java日志访问提供一个标准、规范的API框架,其主要意义在于提供接口,具体的实现可以交由其他日志框架,例如Log4J和logback等。即 SLF4J 是日志门面, logback 是日志实现。
Spring Boot 支持 Java Util Logging, Log4j, Log4j2, Lockback 作为日志框架,如果你使用 Starters 启动器,Spring Boot 将使用 Logback 作为默认日志框架。
你如何理解 Spring Boot 配置加载顺序?
在 Spring Boot 里面,可以使用以下几种方式来加载配置。
1)properties文件;
2)YAML文件;
3)系统环境变量;
4)命令行参数;
等等……
配置属性加载的顺序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
331、开发者工具 `Devtools` 全局配置参数;
2、单元测试上的 `@TestPropertySource` 注解指定的参数;
3、单元测试上的 `@SpringBootTest` 注解指定的参数;
4、命令行指定的参数,如 `java -jar springboot.jar --name="Java技术栈"`;
5、命令行中的 `SPRING_APPLICATION_JSONJSON` 指定参数, 如 `java -Dspring.application.json='{"name":"Java技术栈"}' -jar springboot.jar`
6、`ServletConfig` 初始化参数;
7、`ServletContext` 初始化参数;
8、JNDI参数(如 `java:comp/env/spring.application.json`);
9、Java系统参数(来源:`System.getProperties()`);
10、操作系统环境变量参数;
11、`RandomValuePropertySource` 随机数,仅匹配:`ramdom.*`;
12、JAR包外面的配置文件参数(`application-{profile}.properties(YAML)`)
13、JAR包里面的配置文件参数(`application-{profile}.properties(YAML)`)
14、JAR包外面的配置文件参数(`application.properties(YAML)`)
15、JAR包里面的配置文件参数(`application.properties(YAML)`)
16、`@Configuration`配置文件上 `@PropertySource` 注解加载的参数;
17、默认参数(通过 `SpringApplication.setDefaultProperties` 指定);数字小的优先级越高,即数字小的会覆盖数字大的参数值,我们来实践下,验证以上配置参数的加载顺序。
Spring Boot 2.X 有什么新特性?与 1.X 有什么区别?
依赖 JDK 版本升级
2.x 至少需要 JDK 8 的支持,2.x 里面的许多方法应用了 JDK 8 的许多高级新特性,所以你要升级到 2.0 版本,先确认你的应用必须兼容 JDK 8。
另外,2.x 开始了对 JDK 9 的支持。
第三方类库升级
2.x 对第三方类库升级了所有能升级的最新稳定版本。
1) Spring Framework 5+
2) Tomcat 8.5+
3) Flyway 5+
4) Hibernate 5.2+
5) Thymeleaf 3+
响应式 Spring 编程支持
HTTP/2 支持
过滤器、拦截器的区别
spring 的拦截器和 servlet 的过滤器 Filter 有相似之处,比如二者都是 AOP 编程思想的体现。
使用范围不同
Filter 是 servlet 规范定义的,只能用于 web 程序中;而拦截器既可以y用于 web 程序,也可以用于 application、swing 程序中。
规范不同
Filter 是在 servlet 规范中定义的,定义在 javax.servlet 包中,是 servlet 容器支持的,由 Server(Tomcat) 调用;而拦截器是 spring 容器内的,定义在org.springframework.web.servlet 包中,是 spring 框架支持的,由 Spring 调用。因此 Filter 总是优先于 Interceptor 执行。
使用的资源不同
拦截器是一个Spring的组件,归Spring管理,配置在Spring文件中,因此能使用Spring里的任何资源、对象,例如 Service对象、数据源、事务管理等,通过IoC注入到拦截器即可,而 Filter 则不能。
深度不同
Filter在只在 Servlet 前后起作用。拦截器能够深入到方法前后、异常抛出前后等,因此拦截器的使用具有更大的弹性。
过滤器拦截器执行顺序:
![]()
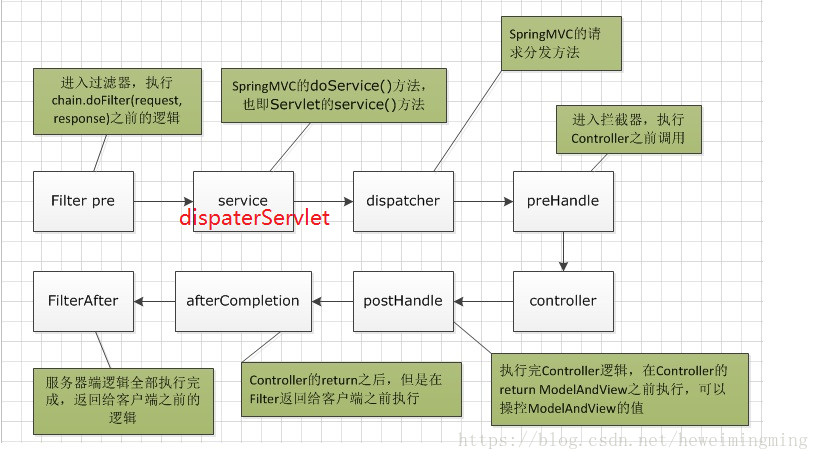
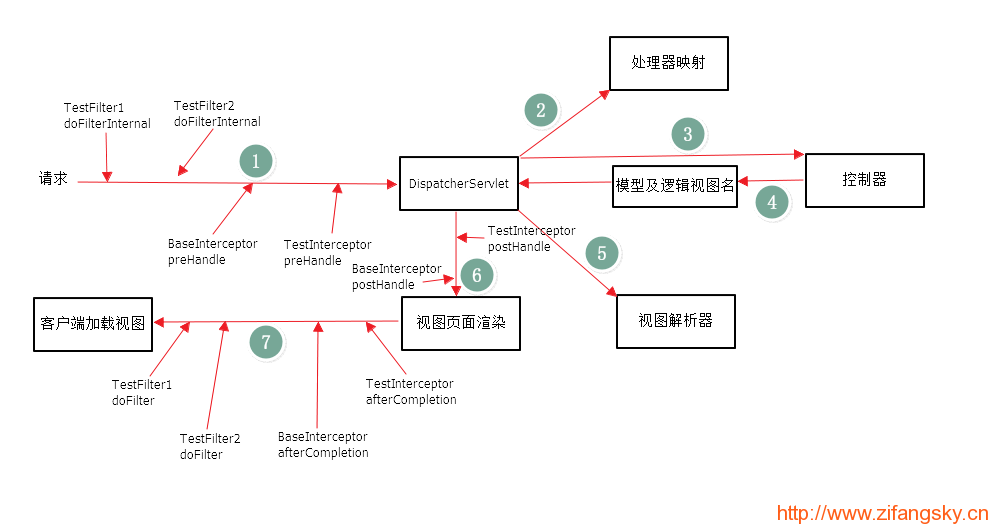
Redis
什么是 Redis
Redis 是一个使用 C 语言写成的,开源的 key-value 数据库。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 五种基本数据结构
String 字符串
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
常用命令:
set,get,decr,incr,mget等。
使用场景:常规key-value缓存应用; 常规计数:微博数,粉丝数等,计数器是有范围的,它不能超过Long.Max,不能低于Long.MIN。
Hash 字典
哈希等价于Java语言的HashMap,在实现结构上它使用二维结构,第一维是数组,第二维是链表,hash的内容key和value存放在链表中,数组里存放的是链表的头指针。通过key查找元素时,先计算key的hashcode,然后用hashcode对数组的长度进行取模定位到链表的表头,再对链表进行遍历获取到相应的value值,链表的作用就是用来将产生了「hash碰撞」的元素串起来。Java语言开发者会感到非常熟悉,因为这样的结构和HashMap是没有区别的。哈希的第一维数组的长度也是2^n。hash特别适合用于存储对象。 比如我们可以用Hash数据结构来存储用户信息,商品信息等等。
当hash内部的元素比较拥挤时(hash碰撞比较频繁),就需要进行扩容。扩容需要申请新的两倍大小的数组,然后将所有的键值对重新分配到新的数组下标对应的链表中(rehash)。如果hash结构很大,比如有上百万个键值对,那么一次完整rehash的过程就会耗时很长。这对于单线程的Redis里来说有点压力山大。所以Redis采用了渐进式rehash的方案。它会同时保留两个新旧hash结构,在后续的定时任务以及hash结构的读写指令中将旧结构的元素逐渐迁移到新的结构中。这样就可以避免因扩容导致的线程卡顿现象。
常用命令:
hget,hset,hgetall等。举个例子: 最近做的一个电商网站项目的首页就使用了redis的hash数据结构进行缓存,因为一个网站的首页访问量是最大的,所以通常网站的首页可以通过redis缓存来提高性能和并发量。
List 列表
Redis将列表数据结构命名为list而不是array,是因为列表的存储结构用的是链表而不是数组,而且链表还是双向链表。因为它是链表,所以随机定位性能较弱,首尾插入删除性能较优。如果list的列表长度很长,使用时我们一定要关注链表相关操作的时间复杂度。如果再深入一点,你会发现Redis底层存储的还不是一个简单的linkedlist,而是称之为快速链表quicklist的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
常用命令:
lpush,rpush,lpop,rpop,lrange等应用场景:微博的关注列表,粉丝列表,最新消息排行等功能都可以用Redis的list结构来实现。在日常应用中,列表常用来作为异步队列来使用。
Set 集合
set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的。 当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。Java程序员都知道HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
常用命令:
sadd,spop,smembers,sunion等应用场景:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同喜好、二度好友等功能。
Sorted Set 有序集合
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构
Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。zset底层实现使用了两个数据结构,第一个是hash,第二个是跳跃列表,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。跳跃列表的目的在于给元素value排序,根据score的范围获取元素列表。
常用命令:
zadd,zrange,zrem,zcard等应用场景:在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用Redis中的SortedSet结构进行存储。
数据淘汰(内存回收)策略
Redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。Redis 提供 6 种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
Redis 在默认情况下会采用 noeviction 策略。换句话说,如果内存己满 , 则不再提供写入操作 , 而只提供读取操作 。 可以采用 config set maxmemory-policy {policy} 命令来动态配置:
1 | 192.168.1.4>config set maxmemory-policy volatile-lru |
Redis常用命令
Redis持久化
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis有两种持久化的方式:快照(RDB文件)和追加式文件(AOF文件)。前者将当前数据保存到硬盘,后者则是将每次执行的写命令保存到硬盘。
RDB持久化方式会在一个特定的间隔保存那个时间点的一个数据快照。
AOF持久化方式则会记录每一个服务器收到的写操作。在服务启动时,这些记录的操作会逐条执行从而重建出原来的数据。写操作命令记录的格式跟Redis协议一致,以追加的方式进行保存。
Redis的持久化是可以禁用的,就是说你可以让数据的生命周期只存在于服务器的运行时间里。
两种方式的持久化是可以同时存在的,但是当Redis重启时,AOF文件会被优先用于重建数据,因为AOF的数据更准确。
RDB 方式可以保存过去一段时间内的数据,并且保存结果是一个单一的文件,可以将文件备份到其他服务器,并且在回复大量数据的时候,RDB 方式的速度会比 AOF 方式的回复速度要快。
AOF 方式默认每秒钟备份 1 次,频率很高,它的操作方式是以追加的方式记录日志而不是数据,并且它的重写过程是按顺序进行追加,所以它的文件内容非常容易读懂。
RDB 由于备份频率不高,所以在恢复数据的时候有可能丢失一小段时间的数据,而且在数据集比较大的时候有可能对毫秒级的请求产生影响。
AOF 的文件体积比较大,而且由于保存频率很高,所以整体的速度会比 RDB 慢一些,但是性能依旧很高。
Redis 和数据库双写一致性问题
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
更新的时候,先删除缓存,然后更新数据库。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,复杂点的缓存的场景,缓存不单单是数据库中直接取出来的值。比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值。
另外更新缓存的代价有时候是很高的。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次,100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都把里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
Redis分区
分区是将你的数据分发到不同redis实例上的一个过程,每个redis实例只是你所有key的一个子集。
Redis分区主要有两个目的:
- 分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。
- 分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
分区类型
有许多分区标准。假如我们有4个Redis实例R0, R1, R2, R3,有一批用户数据user:1, user:2, … ,那么有很多存储方案可以选择。
范围分区:就是将不同范围的对象映射到不同Redis实例。比如说,用户ID从0到10000的都被存储到R0,用户ID从10001到20000被存储到R1,依此类推。
散列分区:
- 使用散列函数 (如
crc32)将键名称转换为一个数字。例:键foobar, 使用crc32(foobar)函数将产生散列值93024922。 - 对转换后的散列值进行取模,以产生一个0到3的数字,以便可以使这个key映射到4个Redis实例当中的一个。
93024922 % 4等于2, 所以foobar会被存储到第2个Redis实例。 R2 注意: 对一个数字进行取模,在大多数编程语言中是使用运算符%
- 使用散列函数 (如
- 如果Redis只作为可伸缩缓存服务器来使用,那么用一致性哈希是非常容易的。
- 如果Redis被作为数据持久化服务器,需要提供节点和键值的固定映射,还有节点数目必须是固定的,不能改变。否则当增加或删除节点时,我们需要一个系统来为键重新分配节点,从2015年4月1日开始,Redis集群提供该特性。
分区实现
Redis 集群
Twemproxy
Twemproxy是Twitter维护的(缓存)代理系统,代理Memcached的ASCII协议和Redis协议。它是单线程程序,使用c语言编写,运行起来非常快。它是采用Apache 2.0 license的开源软件。
Twemproxy支持自动分区,如果其代理的其中一个Redis节点不可用时,会自动将该节点排除(这将改变原来的keys-instances的映射关系,所以你应该仅在把Redis当缓存时使用Twemproxy)。
Twemproxy本身不存在单点问题,因为你可以启动多个Twemproxy实例,然后让你的客户端去连接任意一个Twemproxy实例。
Twemproxy是Redis客户端和服务器端的一个中间层,由它来处理分区功能应该不算复杂,并且应该算比较可靠的。
支持一致性哈希的客户端
相对于Twemproxy,另一种可选的分区方案是在客户端实现一致性哈希或者其他类似算法。有很多客户端已经支持一致性哈希,如 Redis-rb 和 Predis.
Redis Java 客户端
Redis的Java客户端主要有 Redisson、Jedis、lettuce 等等,官方推荐使用Redisson。
Spring Boot 2.0中 Redis 客户端驱动现在由 Jedis变为了 Lettuce,但依然支持 jedis。
Spring boot data-redis 依赖 jedis或Lettuce,实际上是对jedis这些客户端的封装,提供一套与客户端无关的api供应用使用,从而你在从一个redis客户端切换为另一个客户端,不需要修改业务代码。spring-boot-data-redis 内部实现了对Lettuce和jedis两个客户端的封装,默认使用的是Lettuce。
SpringDataRedis
Spring-data-redis是spring大家族的一部分,提供了在srping应用中通过简单的配置访问redis服务,对reids底层开发包(Jedis, JRedis, and RJC)进行了高度封装,RedisTemplate提供了redis各种操作。
Redis集群方案
集群的实现基础是 Redis 分区。
集群实现方式有三种:
客户端分片
由客户端决定key写入或者读取的节点。包括jedis在内的一些客户端,实现了客户端分片机制。
![img]()
基于代理的分片
客户端发送请求到一个代理,代理解析客户端的数据,将请求转发至正确的节点,然后将结果回复给客户端。例如:Twemproxy、codis。
![]()
路由查询
将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行。如:Redis-cluster
![]()



twemproxy
大概概念是,它类似于一个代理方式,使用方法和普通redis无任何区别,设置好它下属的多个redis实例后,使用时在本需要连接redis的地方改为连接twemproxy,它会以一个代理的身份接收请求并使用一致性hash算法,将请求转接到具体redis,将结果再返回twemproxy。使用方式简便(相对redis只需修改连接端口),对旧项目扩展的首选。 问题:twemproxy自身单端口实例的压力,使用一致性hash后,对redis节点数量改变时候的计算值的改变,数据无法自动移动到新的节点。
codis
目前用的最多的集群方案,基本和twemproxy一致的效果,但它支持在 节点数量改变情况下,旧节点数据可恢复到新hash节点。使用这套方案的公司:阿里云、ApsaraCache, RedisLabs、京东、百度等
redis cluster3.0自带的集群
特点在于他的分布式算法不是一致性hash,而是hash槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
在业务代码层实现
起几个毫无关联的redis实例,在代码层,对key 进行hash计算,然后去对应的redis实例操作数据。 这种方式对hash层代码要求比较高,需要考虑节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控等等。
方案选择
基于客户端的方案任何时候都要慎重考虑,在此我们不予推荐。
基于twemproxy的方案虽然看起来功能挺全面,但是实际使用中存在的问题同样很多,具体见上述,目前也不推荐再用twemproxy的方案。
codis在redis cluster出来之前应该是最理想的一种redis集群解决方案,但是codis需要采用其自身修改版的redis,因此这和redis社区版本会有差异,因此无法及时跟进redis社区版本更新,而对于那些自己对redis有所改动的用户来讲,那更不便使用codis。同时codis-proxy是go语言编写,在性能方面,尤其是耗时表现损耗较多。
redis cluster自redis 3.0推出以来,目前已经在很多生产环境上得到了应用,目前来讲,构建redis集群,推荐采用redis cluster搭配一款支持redis cluster的代理方案。
Redis与消息队列
尽量不要使用redis去做消息队列,这不是redis的设计目标。但实在太多人使用redis去做去消息队列。一般比较多的还是使用redis做缓存,比如秒杀系统,首页缓存等等。
首先做简单的引入,MQ(消息队列)主要是用来:
- 解耦应用、
- 异步化消息
- 流量削峰填谷
目前使用的较多的有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ等。
为什么要用Redis实现轻量级MQ?
在业务的实现过程中,就算没有大量的流量,解耦和异步化几乎也是处处可用,此时MQ就显得尤为重要。但与此同时MQ也是一个蛮重的组件,例如我们如果用RabbitMQ就必须为它搭建一个服务器,同时如果要考虑可用性,就要为服务端建立一个集群,而且在生产如果有问题也需要查找功能。在中小型业务的开发过程中,可能业务的其他整个实现都没这个重。过重的组件服务会成倍增加工作量。所幸的是,Redis提供的list数据结构非常适合做消息队列。
生产者消费者模式
1 | public class ProducerTest { |
1 | public class ConsumerTest { |
发布订阅模式
redis同样可以实现消息队列的发布订阅功能,发布消息者使用比较简单,订阅消息者则需要手动继承 redis.clients.jedis.JedisPubSub 这个抽象类,消费者有动作时就会回调这个实现类的方法。
1 | public class ProducerTest { |
1 | public class MessageHandler extends JedisPubSub { |
1 | public class ConsumerTest { |
如何实现ack机制?
ack,即消息确认机制(Acknowledge)。
首先来看RabbitMQ的ack机制:
- Publisher把消息通知给Consumer,如果Consumer已处理完任务,那么它将向Broker发送ACK消息,告知某条消息已被成功处理,可以从队列中移除。如果Consumer没有发送回ACK消息,那么Broker会认为消息处理失败,会将此消息及后续消息分发给其他Consumer进行处理(redeliver flag置为true)。
- 这种确认机制和TCP/IP协议确立连接类似。不同的是,TCP/IP确立连接需要经过三次握手,而RabbitMQ只需要一次ACK。
- 值的注意的是,RabbitMQ当且仅当检测到ACK消息未发出且Consumer的连接终止时才会将消息重新分发给其他Consumer,因此不需要担心消息处理时间过长而被重新分发的情况。
那么在我们用Redis实现消息队列的ack机制的时候该怎么做呢?
需要注意两点:
- work处理失败后,要回滚消息到原始pending队列
- 假如worker挂掉,也要回滚消息到原始pending队列
上面第一点可以在业务中完成,即失败后执行回滚消息。
实现方案
(该方案主要解决worker挂掉的情况)
- 维护两个队列:pending队列和doing表(hash表)。
- workers定义为ThreadPool。
- 由pending队列出队后,workers分配一个线程(单个worker)去处理消息——给目标消息append一个当前时间戳和当前线程名称,将其写入doing表,然后该worker去消费消息,完成后自行在doing表擦除信息。
- 启用一个定时任务,每隔一段时间去扫描doing队列,检查每个元素的时间戳,如果超时,则由worker的ThreadPoolExecutor去检查线程是否存在,如果存在则取消当前任务执行,并把事务rollback。最后把该任务从doing队列中pop出,再重新push进pending队列。
- 在worker的某线程中,如果处理业务失败,则主动回滚,并把任务从doing队列中移除,重新push进pending队列。
Redis分布式锁
针对分布式锁,目前有以下几种实现方案:
- 基于数据库锁机制实现分布式锁
- 基于缓存实现分布式锁
- 基于zookeeper实现分布式锁
说实话,如果在公司里落地生产环境用分布式锁的时候,一定是会用开源类库的,比如Redis分布式锁,一般就是用Redisson框架就好了,非常的简便易用。
非要自己实现的话就是使用 Redis 的 SETNX 和 GETSET 这两个命令实现。
1 |
|
1 | public interface SecKillService { |
1 |
|
加锁核心代码解析
1 | /** |
最原始的加锁其实只需要看
SETNX是否成功即可1
2
3
4
5
6
7
8public boolean lock(String key, String value) {
// SETNX再java中对应的是setIfAbsent
if (redisTemplate.opsForValue().setIfAbsent(key, value)) {
return true;
}
return false;
}1
2
3
4
5
6
7
8
9
10
11
12
13
public void orderProductMockDiffUser(String productId) {
// 加锁
long time = System.currentTimeMillis()+TIMEOUT;
if (!redisLock.lock(productId, String.valueOf(time))){
throw new SellException(101, "哎呦喂,人也太多了,换个姿势再试试~~");
}
// 业务代码
// 解锁
redisLock.unlock(productId, String.valueOf(time));
}但是这样会出现死锁的情况:当某个线程获取锁后在业务代码出现异常,此时解锁的代码就走不到了,锁就一直被占用了,就会出现死锁的情况。
为了解决这一问题,引入了超时时间,当死锁超过一定时间后让该锁自动失效,其他线程就可以抢占该锁了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public boolean lock(String key, String value) {
// SETNX再java中对应的是setIfAbsent
if (redisTemplate.opsForValue().setIfAbsent(key, value)) {
return true;
}
String currentValue = redisTemplate.opsForValue().get(key);
// 如果锁过期
if (!StringUtils.isEmpty(currentValue)
&& Long.parseLong(currentValue) < System.currentTimeMillis()) {
return true;
}
return false;
}但是此时还存在线程安全问题:当死锁过期的时候如果有两个线程同时执行到了判断锁过期的 if 语句内,则这两个线程都将获得该锁,造成线程安全问题,导致数据不一致。
利用 Redis 的单线程特性可以防止该问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public boolean lock(String key, String value) {
// SETNX再java中对应的是setIfAbsent
if (redisTemplate.opsForValue().setIfAbsent(key, value)) {
return true;
}
String currentValue = redisTemplate.opsForValue().get(key);
// 如果锁过期
if (!StringUtils.isEmpty(currentValue)
&& Long.parseLong(currentValue) < System.currentTimeMillis()) {
// 获取上一个锁的时间
String oldValue = redisTemplate.opsForValue().getAndSet(key, value);
if (!StringUtils.isEmpty(oldValue) && oldValue.equals(currentValue)) {
return true;
}
}
return false;
}当两个线程同时走到判断锁过期的代码内,此时由于 Redis 是单线程的,只会有一个线程先执行
GETSET命令,过去该锁,当另一个线程再执行GETSET后将会导致里面的 if 语句结果为 false,故最终只会有一个线程获得锁。
缓存穿透
Redis缓存穿透是指查询一个一定不存在的数据,由于缓存不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
对于缓存穿透问题,通常有如下解决方案:
可以给key设置一些格式规则,然后查询之前先过滤掉不符合规则的Key。
如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。设置一个过期时间或者当有值的时候将缓存中的值替换掉即可。
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查询压力。关于布隆过滤器,详情查看:基于BitSet的布隆过滤器(Bloom Filter)
缓存雪崩
指的是大量缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
解决办法:
这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布,设置不同的过期时间,比如超时时间是固定的5分钟加上随机的2分钟。
用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。在加锁方法内先从缓存中再获取一次,没有再查DB。 (当然也可以: 在没有获取锁的线程中一直轮询缓存,至超限时)
缓存的高可用性
缓存层设计成高可用,防止缓存大面积故障。即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
缓存降级
可以利用ehcache等本地缓存(暂时使用),但主要还需要对源服务访问进行限流、资源隔离(熔断)、降级等。
当访问量剧增、服务出现问题仍然需要保证服务还是可用的。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级,这里会涉及到运维的配合。降级的最终目的是保证核心服务可用,即使是有损的。
做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
3、定时刷新缓存;
一致性 Hash 算法
我们在使用Redis的时候,为了保证Redis的高可用,提高Redis的读写性能,最简单的方式我们会做主从复制,组成Master-Master或者Master-Slave的形式,或者搭建Redis集群,进行数据的读写分离,类似于数据库的主从复制和读写分离。如下所示:
假设,我们有一个社交网站,需要使用Redis存储图片资源,存储的格式为键值对,key值为图片名称,value为该图片所在文件服务器的路径,我们需要根据文件名查找该文件所在文件服务器上的路径,数据量大概有2000W左右,按照我们约定的规则进行分库,规则就是随机分配,我们可以部署8台缓存服务器,每台服务器大概含有500W条数据,并且进行主从复制,示意图如下:
如果我们使用Hash的方式,每一张图片在进行分库的时候都可以定位到特定的服务器,示意图如下:
上图中,假设我们查找的是”a.png”,由于有4台服务器(排除从库),因此公式为hash(a.png) % 4 = 2 ,可知定位到了第2号服务器,这样的话就不会遍历所有的服务器,大大提升了性能!
Hash的问题
使用上述Hash算法进行缓存时,会出现一些缺陷,主要体现在服务器数量变动的时候,所有缓存的位置都要发生改变!为了解决这些问题,Hash一致性算法(一致性Hash算法)诞生了!
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下:
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用IP地址哈希后在环空间的位置如下:
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
一致性Hash算法的容错性和可扩展性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响,如下所示:
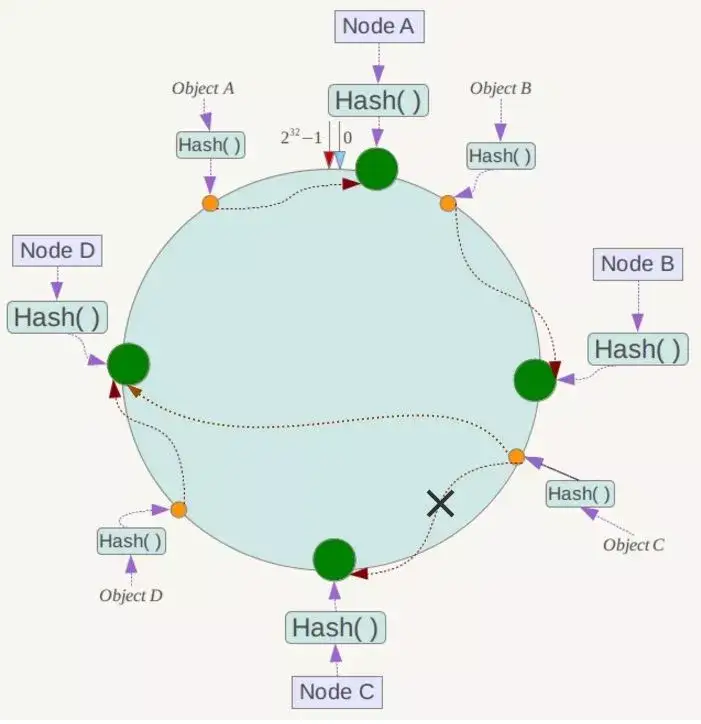
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
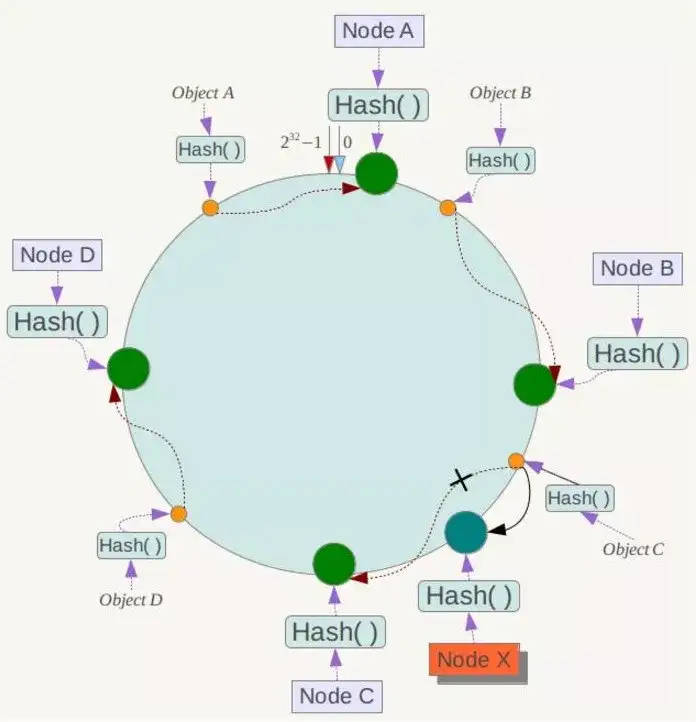
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:
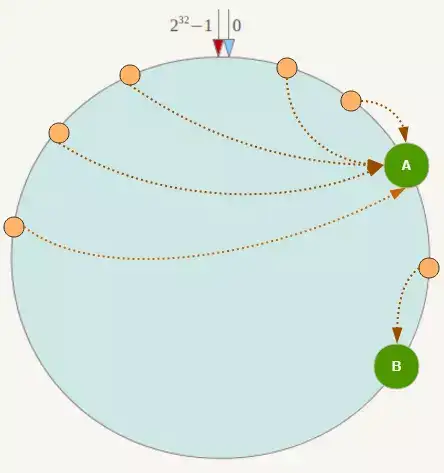
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
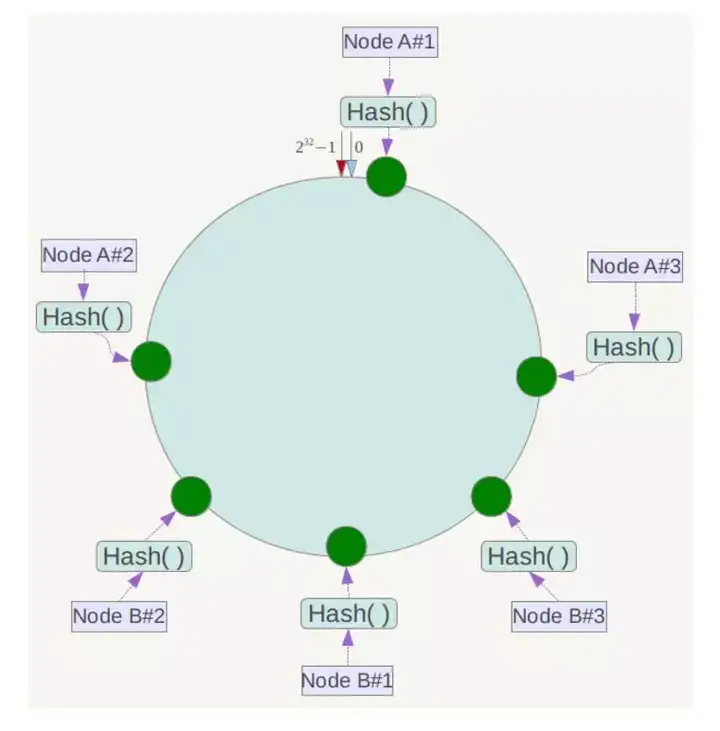
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
Hash槽
Redis Cluster 里面使用的方法,一个 Redis Cluster 包含16384(0~16383)个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中。
- redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护 node<->slot<->value。
- 一共有16384个槽,每台服务器分管其中的一部分
- 插入一个数据的时候,先根据CRC16算法计算key对应的值,然后用该值对16384取余数(即CRC16(key) mod 16384),确定将数据放到哪个槽里面
- 在增加节点的时候,之前的节点各自分出一些槽给新节点,对应的数据也一起迁出
为什么要选择的槽是16384个呢?
crc16会输出16bit的结果,可以看作是一个分布在0-2^16-1之间的数,redis的作者测试发现这个数对2^{14}求模的会将key在0-2^{14-1}之间分布得很均匀,因此选了这个值。
面试常见问题
Redis与Memcached的区别
数据类型支持不同
与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多。最为常用的数据类型主要由五种:String、Hash、List、Set和Sorted Set。
内存管理机制不同
Redis支持数据的备份,即master-slave模式的数据备份;
数据持久化支持
Redis虽然是基于内存的存储系统,但是它本身是支持内存数据的持久化的,而且提供两种主要的持久化策略:RDB快照和AOF日志。而memcached是不支持数据持久化操作的。
集群管理的不同
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。
相较于Memcached只能采用客户端实现分布式存储,Redis更偏向于在服务器端构建分布式存储。最新版本的Redis已经支持了分布式存储功能。Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,具有线性可伸缩的功能。
网络IO模型不同
memcached是多线程,非阻塞IO复用的网络模型。redis使用单线程的IO复用模型。
redis使用的是单线程模型,保证了数据按顺序提交。
memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作value大小不同
redis最大可以达到1GB,而memcache只有1MB
性能比较
Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。
MyBatis
什么是MyBatis
MyBatis是一个Java持久化框架,它通过XML描述符或注解把对象与存储过程或SQL语句关联起来。
MyBatis是在Apache许可证 2.0下分发的自由软件,是iBATIS 3.0的分支版本。其维护团队也包含iBATIS的初创成员。
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
MyBatis的优点
MyBatis把sql语句从Java源程序中独立出来,放在单独的XML文件中编写,给程序的维护带来了很大便利。
MyBatis封装了底层JDBC API的调用细节,并能自动将结果集转换成Java Bean对象,大大简化了Java数据库编程的重复工作。
因为MyBatis需要程序员自己去编写sql语句,程序员可以结合数据库自身的特点灵活控制sql语句,因此能够实现比Hibernate等全自动orm框架更高的查询效率,能够完成复杂查询。
接口绑定
MyBatis的接口绑定就是在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定,我们直接调用接口方法就可以,这样比起原来了SqlSession提供的方法我们可以有更加灵活的选择和设置.
接口绑定有两种方式:一种是通过注解绑定,就是在接口的方法上面加上 @Select 、@Update 等注解里面包含Sql语句来绑定。另外一种就是通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名。
当Sql语句比较简单时候,用注解绑定;当SQL语句比较复杂时候,用xml绑定.
关联查询
一对一
1 | <mapper namespace="com.lcb.mapping.userMapper"> |
一对多
1 | <mapper namespace="com.lcb.mapping.userMapper"> |
缓存机制
MyBatis的查询缓存机制,根据缓存区的作用域(生命周期)可划分为两种:一级缓存与二级缓存
一级缓存是Session会话级别的缓存,位于表示一次数据库会话的SqlSession对象之中,又被称之为本地缓存。一级缓存是MyBatis内部实现的一个特性,用户不能配置,默认情况下自动支持的缓存,用户没有定制它的权利(不过这也不是绝对的,可以通过开发插件对它进行修改);
二级缓存是Application应用级别的缓存,它的生命周期很长,跟Application的声明周期一样,也就是说它的作用范围是整个Application应用。
MyBatis中一级缓存和二级缓存的组织如下图所示:
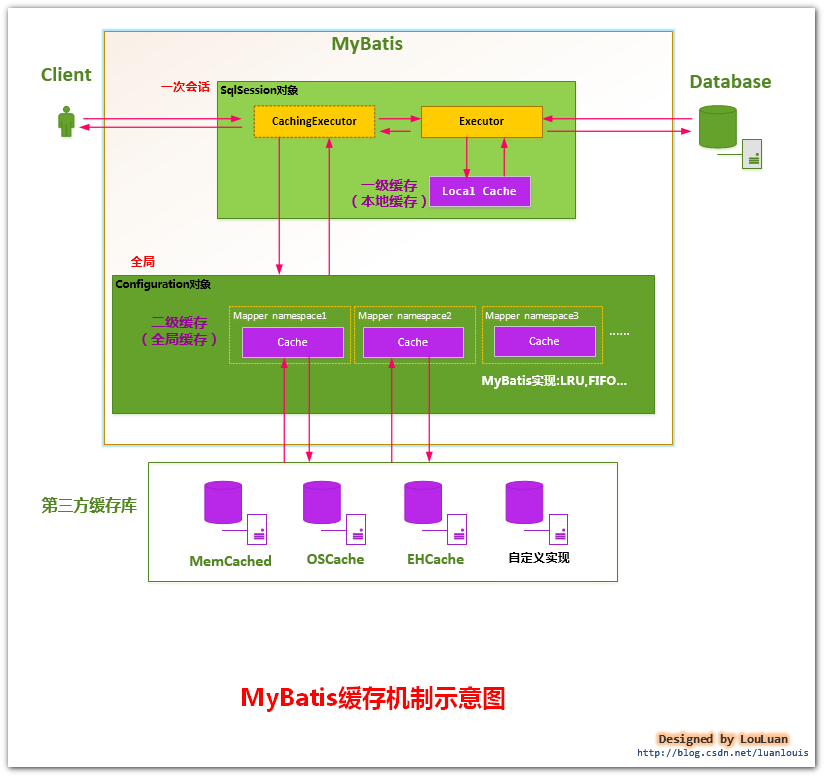
一级缓存
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。
为了减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
实际上, SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。SqlSession、Executor、Cache之间的关系:Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
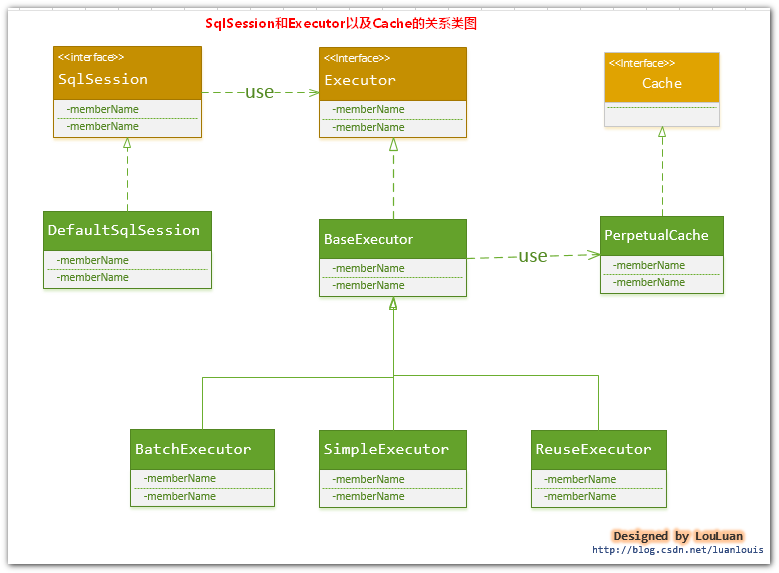
一级缓存配置
只需在MyBatis的配置文件中,添加如下语句,就可以使用一级缓存。共有两个选项,SESSION或者STATEMENT,默认是SESSION级别,即在一个MyBatis会话中执行的所有语句,都会共享这一个缓存。一种是STATEMENT级别,可以理解为缓存只对当前执行的这一个Statement有效。
1 | <setting name="localCacheScope" value="SESSION"/> |
一级缓存的生命周期
MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
一级缓存的工作流程:
对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果;
判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;
如果命中,则直接将缓存结果返回;
如果没命中:
4.1 去数据库中查询数据,得到查询结果;
4.2 将key和查询到的结果分别作为key,value对存储到Cache中;
4.3. 将查询结果返回;
结束。
Cache接口的设计以及CacheKey的定义
MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Service Provider Interface) ,所有的MyBatis内部的Cache缓存,都应该实现这一接口。MyBatis定义了一个PerpetualCache实现类实现了Cache接口,实际上,在SqlSession对象里的Executor 对象内维护的Cache类型实例对象,就是PerpetualCache子类创建的。
Cache最核心的实现其实就是一个Map,将本次查询使用的特征值作为key,将查询结果作为value存储到Map中。现在最核心的问题出现了:怎样来确定一次查询的特征值?换句话说就是:怎样判断某两次查询是完全相同的查询?也可以这样说:如何确定Cache中的key值?
MyBatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
传入的 statementId
查询时要求的结果集中的结果范围 (结果的范围通过rowBounds.offset和rowBounds.limit表示);
这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
传递给java.sql.Statement要设置的参数值
现在分别解释上述四个条件:
传入的statementId,对于MyBatis而言,你要使用它,必须需要一个statementId,它代表着你将执行什么样的Sql;
MyBatis自身提供的分页功能是通过RowBounds来实现的,它通过rowBounds.offset和rowBounds.limit来过滤查询出来的结果集,这种分页功能是基于查询结果的再过滤,而不是进行数据库的物理分页;
由于MyBatis底层还是依赖于JDBC实现的,那么,对于两次完全一模一样的查询,MyBatis要保证对于底层JDBC而言,也是完全一致的查询才行。而对于JDBC而言,两次查询,只要传入给JDBC的SQL语句完全一致,传入的参数也完全一致,就认为是两次查询是完全一致的。
上述的第3个条件正是要求保证传递给JDBC的SQL语句完全一致;第4条则是保证传递给JDBC的参数也完全一致;
综上所述,CacheKey由以下条件决定:statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值
总结
- MyBatis一级缓存的生命周期和SqlSession一致。
- MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
- MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
二级缓存
当开启一个会话时,一个SqlSession对象会使用一个Executor对象来完成会话操作,MyBatis的二级缓存机制的关键就是对这个Executor对象做文章。如果用户配置了”cacheEnabled=true”,那么MyBatis在为SqlSession对象创建Executor对象时,会对Executor对象加上一个装饰者:CachingExecutor,这时SqlSession使用CachingExecutor对象来完成操作请求。CachingExecutor对于查询请求,会先判断该查询请求在Application级别的二级缓存中是否有缓存结果,如果有查询结果,则直接返回缓存结果;如果缓存中没有,再交给真正的Executor对象来完成查询操作,之后CachingExecutor会将真正Executor返回的查询结果放置到缓存中,然后在返回给用户。
二级缓存配置
要正确的使用二级缓存,需完成如下配置的。
在MyBatis的配置文件中开启二级缓存。
1
<setting name="cacheEnabled" value="true"/>
在MyBatis的映射XML中配置cache或者 cache-ref 。
cache标签用于声明这个namespace使用二级缓存,并且可以自定义配置。
1
<cache/>
type:cache使用的类型,默认是PerpetualCache,这在一级缓存中提到过。eviction: 定义回收的策略,常见的有FIFO,LRU。flushInterval: 配置一定时间自动刷新缓存,单位是毫秒。size: 最多缓存对象的个数。readOnly: 是否只读,若配置可读写,则需要对应的实体类能够序列化。blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。cache-ref代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache。1
<cache-ref namespace="mapper.StudentMapper"/>
MyBatis二级缓存的划分
MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下:
a.为每一个Mapper分配一个Cache缓存对象(使用<cache>节点配置);
b.多个Mapper共用一个Cache缓存对象(使用<cache-ref>节点配置);
使用二级缓存,必须要具备的条件
MyBatis对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。虽然在Mapper中配置了<cache>,并且为此Mapper分配了Cache对象,这并不表示我们使用Mapper中定义的查询语句查到的结果都会放置到Cache对象之中,我们必须指定Mapper中的某条选择语句是否支持缓存,即如下所示,在<select> 节点中配置useCache=”true”,Mapper才会对此Select的查询支持缓存特性,否则,不会对此Select查询,不会经过Cache缓存。如下所示,Select语句配置了useCache=”true”,则表明这条Select语句的查询会使用二级缓存。
1 | <select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" useCache="true"> |
总之,要想使某条Select查询支持二级缓存,你需要保证:
1. MyBatis支持二级缓存的总开关:全局配置变量参数 cacheEnabled=true
2. 该select语句所在的Mapper,配置了`<cache>` 或`<cached-ref>`节点,并且有效
3. 该select语句的参数 useCache=true一级缓存和二级缓存的使用顺序
请注意,如果你的MyBatis使用了二级缓存,并且你的Mapper和select语句也配置使用了二级缓存,那么在执行select查询的时候,MyBatis会先从二级缓存中取输入,其次才是一级缓存。
二级缓存实现的选择
MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在<cache type="">节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Memecached的集成,总之,使用MyBatis的二级缓存有三个选择:
- MyBatis自身提供的缓存实现;
- 用户自定义的Cache接口实现;
- 跟第三方内存缓存库的集成;
总结
MyBatis的二级缓存相对于一级缓存来说,实现了
SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
通常我们会为每个单表创建单独的映射文件,由于MyBatis的二级缓存是基于
namespace的,多表查询语句所在的namspace无法感应到其他namespace中的语句对多表查询中涉及的表进行的修改,引发脏数据问题。在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。
动态SQL
常用标签
Mybatis提供了9种动态sql标签:trim|where|set|foreach|if|choose|when|otherwise|bind。
<foreach>foreach的主要用在构建 in 条件中,它可以在SQL语句中进行迭代一个集合。
foreach元素的属性主要有 item,index,collection,open,separator,close。
item表示集合中每一个元素进行迭代时的别名,index指定一个名字,用于表示在迭代过程中,每次迭代到的位置,open表示该语句以什么开始,separator表示在每次进行迭代之间以什么符号作为分隔 符,close表示以什么结束,在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下3种情况:- 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list
- 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map
分页插件
添加pagehelper依赖
1
2
3
4
5
6<!-- pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>在 application.yml 配置文件中添加以下配置:
1
2
3
4
5
6#pagehelper分页插件配置
pagehelper:
helperDialect: mysql
reasonable: true
supportMethodsArguments: true
params: count=countSql在 Mapper 查询接口调用前增加
PageHelper.startPage(pageNo,pageSize);1
2
3
4
5("/users")
public List<User> lists(@RequestParam(defaultValue = "1") int pageNo, @RequestParam(defaultValue = "10") int pageSize) {
PageHelper.startPage(pageNo,pageSize);
return userService.getUsers();
}需要注意的是,分页代码
PageHelper.startPage(pageNo,pageSize);只对其后的第一个查询有效。返回分页信息
上面我们返回的只是数据,而总页数、当前页数、每页条数等分页相关的信息并没有返回。
下面我们对controller、service、mapper里的方法的返回值做一下修改,将
List<User>改为Page<User>,Page是 com.github.pagehelper 包里的类,它是 java.util.ArrayList 的子类。1
2
3
4
5
6("/users")
public PageInfo<User> lists(@RequestParam(defaultValue = "1") int pageNo,@RequestParam(defaultValue = "10") int pageSize) {
PageHelper.startPage(pageNo,pageSize);
PageInfo<User> pageInfo = new PageInfo<>(userService.getUsers());
return pageInfo;
}MyBatis Plus 中的分页

批量插入
Mybatis 批量插入通过 foreach 标签,将多条数据拼接在sql 语句后,一次执行只获取一次session,提交一条sql语句。减少了程序和数据库交互的准备时间。
1 | <insert id="addUser" parameterType="java.util.List" > |
注意:
首先是返回值
对于普通的单条插入,数据库的返回值就是 (0/1) 。
对于返回值代表的意思可以认为是“语句执行返回的数据库受影响的行数。”或者是“此次执行是否成功(0-失败,1-成功)。”对应的也就是在Dao层中,对于插入方法的返回值类型的设定有(int/boolean)两种。
对于批量插入的返回值,返回的还是(0/1),而不是统计插入成功几条,即使你的Dao层方法的返回值类型为int.
这里的(0/1) 也就代表着,这次批量插入是否成功(0-失败,1-成功)。当然你Dao层的返回值还是可以是(int/boolean)
对于批量插入中间有一个失败会怎么样
批量语句,只要有一个失败,就会全部失败。数据库会回滚全部数据。
其实也很好理解。首先我们知道了mybatis
<foreache>批量插入,是在程序内拼接sql 语句(拼接成多条同时插入的sql语句),拼接后发给数据库。就相当于咱们自己在mysql的命令行中,执行一条多插入的语句。默认情况下 mysql 单条语句是一个事务,这在一个事务范围内,当中间的sql语句有问题,或者有一个插入失败,就会触发事务回滚。同时你也能看到错误提示。(命令行执行单条sql的情况)所以有一个插入不成功肯定全部回滚。批量插入数据量的限制
1)、Mybatis 本身对插入的数据量没有限制
2)、mysql对语句的长度有限制,默认是 4M
其他数据库的情况这里不介绍,可以自行百度。通过上面 “mysql对语句的长度有限制,默认是 4M” 我们可以知道,批量插入数据是有限制的。不能一下把几万条数据(就是太大数据量意思)一次性插入。
所以一般情况下我们推荐即使使用批量插入,也要分批次。
每次批次设置多少?需要根据你的插入一条数据的参数量来做度量。因为受限条件是sql语句的长度。而且分批插入更加合理,对于插入失败,回滚范围会缩小很多。
为了保证程序健壮性,对空集合参数的校验
Mybatis并没有做集合容量的验证,如果集合参数为空或者size为0则生成的sql可能只有”insert into user(name,age) values”这样一段或者没有,所以说,写批量sql的时候注意在调用批量方法的地方加入对容量的验证。
mybatis批量插入的另外一种不推荐的写法
1
2
3
4
5<insert id="addBatchUser" parameterType="java.util.List" >
<foreach collection="list" item="item" index="index" separator=";">
insert into user(name,age) values(#{item.name},#{item.age})
</foreach>
</insert>这种写法也能实现批量插入。但是有很多问题。
a、首先这种方式的批量插入也是sql拼接。但是明显字符长度增加。这就导致每批次可插入的数量减少
b、这种方式执行返回值还是(0、1)是已经尝试插入的最后一条数据是否成功。由于这种foreach 拼接成的sql语句,是以分号“;”分隔的多条insert语句。这就导致前面的数据项都插入成功了。(默认数据库的事务处理是单条提交的,出错前的执行都是一个个单条语句,所以并并没有回滚数据。)
所以如果中间插入失败回滚的话,需要使用Spring事务,但是还需要注意spring事务是抛出运行时异常时才会回滚。这种批量插入中间有没插入成功的是不会抛出异常的。所以你需要根据返回值判断手动编码抛出异常。而最上面的那种写法就不用用spring事务,因为他是一条sql语句。
常见面试题
MyBatis和Hibernate的区别
hibernate是全自动,而mybatis是半自动
hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。Hibernate 真正实现了java代码和sql的分离。
hibernate数据库移植性远大于mybatis
hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库(Oracle、MySQL等)的耦合性,而mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。
hibernate拥有完整的日志系统,mybatis则欠缺一些
hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而mybatis则除了基本记录功能外,功能薄弱很多。
mybatis相比hibernate需要关心很多细节
hibernate配置要比mybatis复杂的多,学习成本也比mybatis高。但也正因为mybatis使用简单,才导致它要比hibernate关心很多技术细节。mybatis由于不用考虑很多细节,开发模式上与传统jdbc区别很小,因此很容易上手并开发项目,但忽略细节会导致项目前期bug较多,因而开发出相对稳定的软件很慢,而开发出软件却很快。hibernate则正好与之相反。但是如果使用hibernate很熟练的话,实际上开发效率丝毫不差于甚至超越mybatis。
sql直接优化上,mybatis要比hibernate方便很多
由于mybatis的sql都是写在xml里,因此优化sql比hibernate方便很多。而hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上hibernate不及mybatis。
缓存机制上,hibernate要比mybatis更好一些
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
而Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。
#{}和${}的区别是什么?
动态 SQL 是 mybatis 的强大特性之一,也是它优于其他 ORM 框架的一个重要原因。mybatis 在对 sql 语句进行预编译之前,会对 sql 进行动态解析,解析为一个 BoundSql 对象,也是在此处对动态 SQL 进行处理的。
在动态 SQL 解析阶段, #{ } 和 ${ } 会有不同的表现:
#{ } 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符。
例如,sqlMap 中如下的 sql 语句
1
select * from user where name = #{name};
解析为:
1
select * from user where name = ?;
一个 #{ } 被解析为一个参数占位符
?。而,
${ } 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换
例如,sqlMap 中如下的 sql
1
select * from user where name = '${name}';
当我们传递的参数为 “ruhua” 时,上述 sql 的解析为:
1
select * from user where name = "ruhua";
预编译之前的 SQL 语句已经不包含变量 name 了。
综上所得, ${ } 的变量的替换阶段是在动态 SQL 解析阶段,而 #{ }的变量的替换是在 DBMS 中。
总结:
- #{}是预编译处理,${}是字符串替换。
- Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
- Mybatis在处理${}时,就是把${}替换成变量的值。当需要直接插入一个不做任何修改的字符串到SQL语句中,例如在ORDER BY后接一个不添加引号的值作为列名,这时候就需要使用${}。
- 使用#{}可以有效的防止SQL注入,提高系统安全性。
当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
第1种: 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致
1
2
3<select id="selectorder" parametertype="int" resultetype="me.gacl.domain.order">
select order_id id, order_no orderno ,order_price price form orders where order_id=#{id};
</select> 123第2种: 通过
<resultMap>来映射字段名和实体类属性名的一一对应的关系1
2
3
4
5
6
7
8
9
10
11<resultMap type="me.gacl.domain.order" id="orderresultmap">
<!--用id属性来映射主键字段-->
<id property="id" column="order_id">
<!--用result属性来映射非主键字段,property为实体类属性名,column为数据表中的属性-->
<result property="orderno" column =”order_no"/>
<result property="price" column="order_price"/>
</reslutMap>
<select id="getOrder" parameterType="int" resultMap="orderresultmap">
select * from orders where order_id=#{id}
</select>模糊查询like语句该怎么写?
第1种:在Java代码中添加sql通配符。
1
2string wildcardname = “%smi%”;
list<name> names = mapper.selectlike(wildcardname);1
2
3<select id=”selectlike”>
select * from foo where bar like #{value}
</select>第2种:在sql语句中拼接通配符,会引起sql注入
1
2string wildcardname = “smi”;
list<name> names = mapper.selectlike(wildcardname);1
2
3<select id=”selectlike”>
select * from foo where bar like "%"#{value}"%"
</select>第3种:MySQL的 CONCAT() 函数
1
2string wildcardname = “smi”;
list<name> names = mapper.selectlike(wildcardname);1
2
3<select id=”selectlike”>
select * from foo where bar like CONCAT('%', #{value}, '%')
</select>第4种:Mybatis 的 bind,bind 标签可以将OGNL(对象图导航语言)表达式的值绑定到一个变量中,方便以后引用这个变量的值
1
2string wildcardname = “smi”;
list<name> names = mapper.selectlike(wildcardname);1
2
3
4
5
6<select id="selectBykeyWord" parameterType="string" resultType="com.why.mybatis.entity.RoleEntity">
<select id=”selectlike”>
<bind name="pattern" value="'%' + value + '%'" />
select * from foo where bar like #{pattern}
</select>通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:
com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略,而不是全限名+方法名+参数。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis 使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在 SQL 内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用 Mybatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 SQL,然后重写 SQL,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截 SQL 后重写为:select t.* from (select * from student)t limit 0,10。Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
第一种是使用
<resultMap>标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用sql列的别名功能,将列别名书写为对象属性名,比如T_NAME AS NAME,对象属性名一般是name,小写,但是列名不区分大小写,Mybatis会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成T_NAME AS NaMe,Mybatis一样可以正常工作。有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
如何获取自动生成的(主)键值?
insert 方法总是返回一个int值,这个值代表的是插入的行数。
而自动生成的键值在 insert 方法执行完后可以被设置到传入的参数对象中。1
2
3<insert id=”insertname” usegeneratedkeys=”true” keyproperty=”id”>
insert into names (name) values (#{name})
</insert>1
2
3
4
5
6
7name name = new name();
name.setname(“fred”);
int rows = mapper.insertname(name);
// 完成后,id已经被设置到对象中
system.out.println(“rows inserted = ” + rows);
system.out.println(“generated key value = ” + name.getid());在mapper中如何传递多个参数?
第1种:如果使用的是JDK8的话,那么会有Bug。
1
2//DAO层的函数
Public UserselectUser(String name,String area);1
2
3
4<-- #{0}代表接收的是dao层中的第一个参数,#{1}代表dao层中第二参数,更多参数一致往后加即可。-->
<select id="selectUser"resultMap="BaseResultMap">
select * fromuser_user_t whereuser_name = #{0} anduser_area=#{1}
</select>第2种:使用 @param 注解:
1
2
3
4public interface usermapper {
user selectuser(@param(“username”) string username,
@param(“hashedpassword”) string hashedpassword);
}然后,就可以在xml像下面这样使用(推荐封装为一个map,作为单个参数传递给mapper):
1
2
3
4
5
6<select id="selectuser" resulttype="user">
select id, username, hashedpassword
from some_table
where username = #{username}
and hashedpassword = #{hashedpassword}
</select>Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。
原因就是namespace+id是作为Map<String, MappedStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:
select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。
在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。当然了,不光是Mybatis,几乎所有的 ORM 包括Hibernate,支持延迟加载的原理都是一样的。
SqlMapConfig.xml中配置有哪些内容?
SqlMapConfig.xml中配置的内容和顺序如下:
- properties(属性)
- settings(配置)
- typeAliases(类型别名)
- typeHandlers(类型处理器)
- objectFactory(对象工厂)
- plugins(插件)
- environments(环境集合属性对象)
- environment(环境子属性对象)
- transactionManager(事务管理)
- dataSource(数据源)
- mappers(映射器)
MyBatis实现一对一有几种方式?具体怎么操作的?
有联合查询和嵌套查询,联合查询是几个表联合查询,只查询一次,通过在resultMap里面配置association节点配置一对一的类就可以完成;嵌套查询是先查一个表,根据这个表里面的结果的外键id,去再另外一个表里面查询数据,也是通过association配置,但另外一个表的查询通过select属性配置。
Mybatis能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别?
Mybatis不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把selectOne()修改为selectList()即可;多对多查询,其实就是一对多查询,只需要把selectOne()修改为selectList()即可。
关联对象查询,有两种实现方式,一种是单独发送一个sql去查询关联对象,赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的含义为使用join查询,一部分列是A对象的属性值,另外一部分列是关联对象B的属性值,好处是只发一个sql查询,就可以把主对象和其关联对象查出来。
MyBatis里面的动态Sql是怎么设定的?用什么语法?
MyBatis里面的动态Sql一般是通过if节点来实现,通过OGNL语法来实现,但是如果要写的完整,必须配合where,trim节点,where节点是判断包含节点有内容就插入where,否则不插入,trim节点是用来判断如果动态语句是以and 或or开始,那么会自动把这个and或者or取掉。
Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
还有很多其他的标签,
<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态sql的9个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中<sql>为sql片段标签,通过<include>标签引入sql片段,<selectKey>为不支持自增的主键生成策略标签。Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
Mybatis都有哪些Executor执行器?它们之间的区别是什么?
Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
- SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
- ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map
- BatchExecutor:完成批处理。
Mybatis中如何指定使用哪一种Executor执行器?
在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
Mybatis是否可以映射Enum枚举类?
Mybatis 不单可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方式为自定义一个TypeHandler,实现TypeHandler的setParameter()和getResult()接口方法。TypeHandler有两个作用,一是完成从javaType至jdbcType的转换,二是完成jdbcType至javaType的转换,体现为setParameter()和getResult()两个方法,分别代表设置sql问号占位符参数和获取列查询结果。
resultType resultMap的区别?
类的名字和数据库相同时,可以直接设置resultType参数为Pojo类,若不同,需要设置resultMap 将结果名字和Pojo名字进行转换
Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在Xml映射文件中,
<parameterMap>标签会被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。<resultMap>标签会被解析为ResultMap对象,其每个子元素会被解析为ResultMapping对象。每一个<select>、<insert>、<update>、<delete>标签均会被解析为MappedStatement对象,标签内的sql会被解析为BoundSql对象。Mapper 接口的工作原理
mybatis 在运行时使用 JDK 动态代理生成代理对象,在调用接口方法时,代理对象会拦截接口方法,转而运行 MappedStatement 的 sql 语句,并生成结果返回。
RabbitMQ
为什么要引入消息中间件?
- 系统解耦
- 异步调用
- 流量削峰
消息中间件对比
常见的消息中间件有:ActiveMQ,RabbitMQ,RocketMQ,Kafka。
ActiveMQ
Apache ActiveMQ 是最受欢迎且功能最强大的开源消息传递和Integration Patterns服务器。Apache ActiveMQ速度快,支持许多跨语言客户端和协议,带有易于使用的企业集成模式和许多高级功能,同时完全支持JMS 1.1和J2EE 1.4。Apache ActiveMQ是在Apache 2.0许可下发布。RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
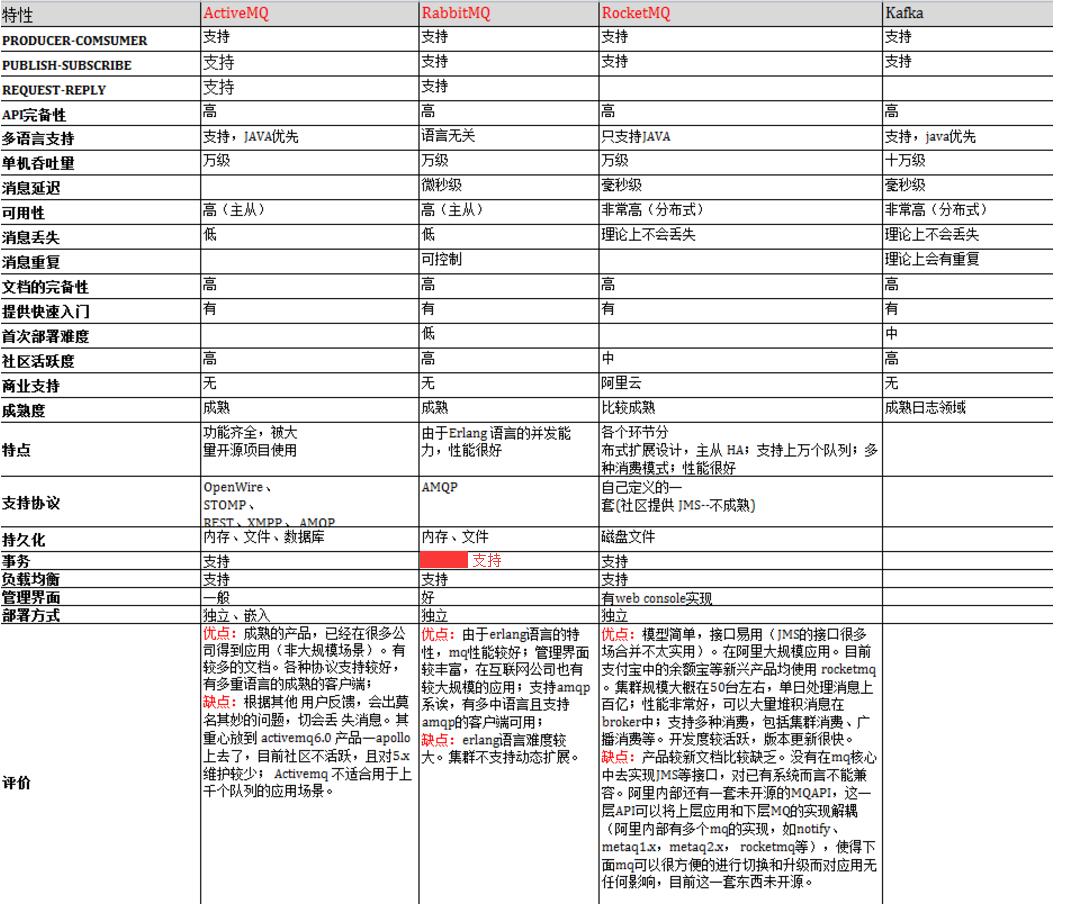
什么是RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
- 可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。 - 灵活的路由(Flexible Routing)在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
- 消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。 - 高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。 - 多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。 - 多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。 - 管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方
面。 - 跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。 - 插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
架构图

主要概念
- RabbitMQ Server: 也叫broker server,它是一种传输服务。 他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。
- Producer: 消息生产者,如图A、B、C,数据的发送方。消息生产者连接RabbitMQ服务器然后将消息投递到Exchange。
- Consumer:消息消费者,如图1、2、3,数据的接收方。消息消费者订阅队列,RabbitMQ将Queue中的消息发送到消息消费者。
- Exchange:生产者将消息发送到Exchange(交换器),由Exchange将消息路由到一个或多个Queue中(或者丢弃)。Exchange并不存储消息。RabbitMQ中的Exchange有direct、fanout、topic、headers四种类型,每种类型对应不同的路由规则。
- Queue:(队列)是RabbitMQ的内部对象,用于存储消息。消息消费者就是通过订阅队列来获取消息的,RabbitMQ中的消息都只能存储在Queue中,生产者生产消息并最终投递到Queue中,消费者可以从Queue中获取消息并消费。多个消费者可以订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。
- RoutingKey:生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则,而这个routing key需要与Exchange Type及binding key联合使用才能最终生效。在Exchange Type与binding key固定的情况下(在正常使用时一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,通过指定routing key来决定消息流向哪里。RabbitMQ为routing key设定的长度限制为255 bytes。
- Connection:Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
- Channels:它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
- VirtualHost:权限控制的基本单位,一个VirtualHost里面有若干Exchange和MessageQueue,以及指定被哪些user使用。
直接模式(Direct)
什么是Direct模式
我们需要将消息发给唯一一个节点时使用这种模式,这是最简单的一种形式。

任何发送到Direct Exchange的消息都会被转发到RouteKey中指定的Queue。
- 一般情况可以使用rabbitMQ自带的Exchange:””(该Exchange的名字为空字符串,下文称其为default Exchange)。
- 这种模式下不需要将Exchange进行任何绑定(binding)操作
- 消息传递时需要一个“RouteKey”,可以简单的理解为要发送到的队列名字。
- 如果vhost中不存在RouteKey中指定的队列名,则该消息会被抛弃。
创建队列
做下面的例子前,我们先建立一个叫itcast的队列。
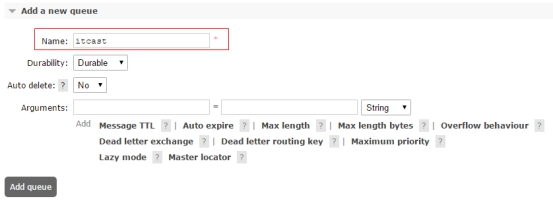
Durability:是否做持久化 Durable(持久)/ transient(临时)
Auto delete : 是否自动删除
代码实现-消息生产者
(1)创建工程rabbitmq_demo,引入amqp起步依赖 ,pom.xml如下:
1 | <dependency> |
(2)编写配置文件application.yml
1 | spring: |
(3)编写启动类
1 |
|
(4)编写测试类
1 | (SpringRunner.class) |
代码实现-消息消费者
(1)编写消息消费者类
1 |
|
(2)运行启动类,可以在控制台看到刚才发送的消息
分列模式(Fanout)
什么是分列(Fanout)模式
当我们需要将消息一次发给多个队列时,需要使用这种模式。如下图:

任何发送到Fanout Exchange的消息都会被转发到与该Exchange绑定(Binding)的所有Queue上。
- 可以理解为路由表的模式
- 这种模式不需要RouteKey
- 这种模式需要提前将Exchange与Queue进行绑定,一个Exchange可以绑定多个
Queue,一个Queue可以同多个Exchange进行绑定。 - 如果接受到消息的Exchange没有与任何Queue绑定,则消息会被抛弃。
交换器绑定队列
(1)在queue中添加队列itheima 和kudingyu
(2)新建交换器chuanzhi

(3)将itcast 和itheima两个队列绑定到交换器chuanzhi
点击chuanzhi进入交换器管理界面
点击Bindings添加绑定 itheima和kudingyu
绑定后效果如下:

代码实现-消息生产者
1 |
|
代码实现-消息消费者
创建消息监听类,用于监听itheima的消息
1 |
|
创建消息监听类,用于监听kudingyu的消息
1 |
|
主题模式(Topic)
什么是主题模式
任何发送到Topic Exchange的消息都会被转发到所有关心RouteKey中指定话题的Queue上

如上图所示
此类交换器使得来自不同的源头的消息可以到达一个对列,其实说的更明白一点就是模糊匹配的意思,例如:上图中红色对列的routekey为usa.#,#代表匹配任意字符,但是要想消息能到达此对列,usa.必须匹配后面的#好可以随意。图中usa.news, usa.weather,都能找到红色队列,符号 # 匹配一个或多个词,符号 * 匹配不多不少一个
词。因此 usa.# 能够匹配到 usa.news.XXX ,但是 usa.* 只会匹配到 usa.XXX 。
注:
交换器说到底是一个名称与队列绑定的列表。当消息发布到交换器时,实际上是由你所连接的信道,将消息路由键同交换器上绑定的列表进行比较,最后路由消息。
任何发送到Topic Exchange的消息都会被转发到所有关心RouteKey中指定话题的Queue上
- 这种模式较为复杂,简单来说,就是每个队列都有其关心的主题,所有的消息都带有一个“标题”(RouteKey),Exchange会将消息转发到所有关注主题能与RouteKey模糊匹配的队列。
- 这种模式需要RouteKey,也许要提前绑定Exchange与Queue。
- 在进行绑定时,要提供一个该队列关心的主题,如“#.log.#”表示该队列关心所有涉及log的消息(一个RouteKey为”MQ.log.error”的消息会被转发到该队列)。
- “#”表示0个或若干个关键字,“”表示一个关键字。如“log.”能与“log.warn”匹配,无法与“log.warn.timeout”匹配;但是“log.#”能与上述两者匹配。
- 同样,如果Exchange没有发现能够与RouteKey匹配的Queue,则会抛弃此消息
创建队列与绑定
(1)新建一个交换器 ,类型选择topic
(2)点击新建的交换器topictest
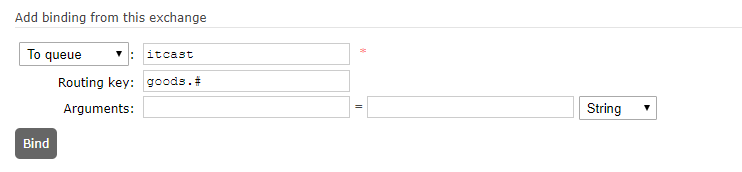
添加匹配规则,添加后列表如下:
代码实现
编写测试类方法:
1 |
|
输出结果:itcast接收到消息:主题模式
1 |
|
输出结果:itheima接收到消息:主题模式
1 |
|
输出结果:
itheima接收到消息:主题模式
itcast接收到消息:主题模式
kudingyu接收到消息:主题模式
RestFul
RESTful
何为RESTful
RESTful架构,就是目前最流行的一种互联网软件架构。它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。REST这个词,是Roy Thomas Fielding在他2000年的博士论文中提出的 .
REST 是Representational State Transfer的缩写,翻译是”表现层状态转化”。 可以总结为一句话:REST是所有Web应用都应该遵守的架构设计指导原则。
面向资源是REST最明显的特征,对于同一个资源的一组不同的操作。资源是服务器上一个可命名的抽象概念,资源是以名词为核心来组织的,首先关注的是名词。REST要求,必须通过统一的接口来对资源执行各种操作。对于每个资源只能执行一组有限的操作。
REST 是一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
安全性和幂等性
7个HTTP方法:GET/POST/PUT/DELETE/PATCH/HEAD/OPTIONS
RestFul service 架构是基于 http 协议的。Http 有两个非常重要的特性,安全性和幂等性。
安全性: 请求一次或多次, 不会改变实例的表现形式. 重点强调无副作用.
幂等性: 请求一次或多次, 响应结果相同. 重点强调副作用的一致性.
增删改查,三个不安全,三个幂等
| Function | idempotent | safe | description |
|---|---|---|---|
| GET | YES | YES | 获取实例 |
| HEAD | YES | YES | 获取响应头 |
| OPTIONS | YES | YES | 获取支持的请求方式 |
| TRACE | YES | YES | 追踪查看最终的请求 |
| PUT | YES | NO | 全量覆盖某个实例 |
| POST | NO | NO | 创建新实例 |
| PATCH | NO | NO | 修改实例的某些属性 |
| DELETE | YES | NO | 删除某个实例 |
一、起源
REST这个词,是Roy Thomas Fielding在他2000年的博士论文中提出的。

Fielding是一个非常重要的人,他是HTTP协议(1.0版和1.1版)的主要设计者、Apache服务器软件的作者之一、Apache基金会的第一任主席。所以,他的这篇论文一经发表,就引起了关注,并且立即对互联网开发产生了深远的影响。
二、名称
Fielding将他对互联网软件的架构原则,定名为REST,即Representational State Transfer的缩写。我对这个词组的翻译是”表现层状态转化”。
如果一个架构符合REST原则,就称它为RESTful架构。
要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组到底是什么意思,它的每一个词代表了什么涵义。如果你把这个名称搞懂了,也就不难体会REST是一种什么样的设计。
三、资源(Resources)
REST的名称”表现层状态转化”中,省略了主语。”表现层”其实指的是”资源”(Resources)的”表现层”。
所谓”资源”,就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓”上网”,就是与互联网上一系列的”资源”互动,调用它的URI。
四、表现层(Representation)
“资源”是一种信息实体,它可以有多种外在表现形式。我们把”资源”具体呈现出来的形式,叫做它的”表现层”(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的”.html”后缀名是不必要的,因为这个后缀名表示格式,属于”表现层”范畴,而URI应该只代表”资源”的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对”表现层”的描述。
五、状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生”状态转化”(State Transfer)。而这种转化是建立在表现层之上的,所以就是”表现层状态转化”。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
六、综述
综合上面的解释,我们总结一下什么是RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现”表现层状态转化”。
七、误区
RESTful架构有一些典型的设计误区。
最常见的一种设计错误,就是URI包含动词。因为”资源”表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中。
举例来说,某个URI是/posts/show/1,其中show是动词,这个URI就设计错了,正确的写法应该是/posts/1,然后用GET方法表示show。
如果某些动作是HTTP动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户1向账户2汇款500元,错误的URI是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词transfer改成名词transaction,资源不能是动词,但是可以是一种服务:
POST /transaction HTTP/1.1
Host: 127.0.0.1
from=1&to=2&amount=500.00
另一个设计误区,就是在URI中加入版本号:
http://www.example.com/app/1.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services):
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0
微服务
什么是系统架构设计
系统架构设计描述了在应用系统的内部,如何根据业务、技术、组织、灵活性、可扩展性以及可维护性等多种因素,将应用系统划分成不同的部分,并使这些部分彼此之间相互分工、相互协作,从而使得这些部分之间能够进行有机的联系,合并组装成为一个整体,完成目标系统的所有工作。
什么是微服务
微服务架构(Microservice Architecture)是一种架构风格,它的主要作用是将功能分解到离散的各个服务当中,从而降低系统的耦合性,并提供更加灵活的服务支持。
单体应用的优缺点
所谓单体应用,就是把所有业务的代码都放在一起。随着业务递增,项目慢慢大了起来,单体应用的缺点就逐一暴露出来了。单体应用主要有以下缺点:
可扩展性差: 随着功能的增加,垂直扩展的成本将会越来越大;而对于水平扩展而言,因为所有代码都运行在同一个进程,没办法做到针对应用程序的部分功能做独立的扩展。
垂直扩展就是升级原有的系统处理能力,比如从硬件上可以扩充系统内存,增加CPU核数,升级网卡等;从软件上可以通过使用Cache减少IO次数,使用异步增加吞吐量
水平扩展就是使用结合负载均衡服务器实现集群部署,解决高可用问题。
维护成本大: 随着应用程序的功能越来越多,当出现 bug 时,可能引起 bug 的原因组合越来越多,导致分析、定位和修复的成本增加;并且在对全局功能缺乏深度理解的情况下,容易在修复 bug 时引入新的 bug。再就是团队越来越大时,沟通成本、管理成本也显著增加。
稳定性不高:一个微不足道的小问题,可以导致整个应用挂掉。
持续交付周期长: 构建和部署时间会随着功能的增多而增加,改了一个业务的一行代码,都需要重启整个单体应用,重新部署。
新人培养周期长: 新成员了解背景、熟悉业务和配置环境的时间越来越长。
技术选型成本高: 单块架构倾向于采用统一的技术平台或方案来解决所有问题,如果后续想引入新的技术或框架,成本和风险都很大。
正因为单体应用有着这些缺陷,才有了微服务。
优点:
- 易于开发: 开发方式简单,IDE 支持好,方便运行和调试。
- 易于测试: 所有功能运行在一个进程中,一旦进程启动,便可以进行系统测试。
- 易于部署: 只需要将打好的一个软件包发布到服务器即可。
- 易于水平伸缩: 只需要创建一个服务器节点,配置好运行时环境,再将软件包发布到新服务器节点即可运行程序(当然也需要采取分发策略保证请求能有效地分发到新节点)。
微服务架构的特性
1. 独立性
微服务架构中的每个服务,都是具有自身的业务逻辑,符合高内聚、低耦合以及单一职责原则。每个服务在应用交付过程中,能够独立地开发、测试和部署。
2. 轻量级通信
服务之间通过轻量级的通信机制实现互通互联,而所谓的轻量级,通常指语言无关、平台无关的交互方式。
对于轻量级通信的格式而言,我们熟悉的 XML 和 JSON,它们是语言无关、平台无关的;对于通信的协议而言,通常基于 HTTP,能让服务间的通信变得标准化、无状态化。目前大家熟悉的 REST(Representational State Transfer)是实现服务间互相协作的轻量级通信机制之一。使用轻量级通信机制,可以让团队选择更适合的语言、工具或者平台来开发服务本身。
RPC与REST
RPC是面向过程,Restful是面向资源,并且使用了Http动词。从这个维度上看,Restful风格的url在表述的精简性、可读性上都要更好。
REST(Representational State Transfer 表现层状态转化)
- 要求要将接口以资源的形式呈现。REST规范把所有内容都视为资源,网络上一切皆资源
- 它的URL主体是资源,是个名词
- 仅支持HTTP协议
RPC(Remote Procedure Call 远程过程调用)
- 主体都是动作,是个动词,表示我要做什么。
- 像调用本地方法一样调用远程方法
- 大多数都是用TCP协议
比较:都是网络交互的协议规范。通常用于多个微服务之间的通信协议。
高与低是对实现两种规范框架的相对比较,但也不是绝对的,需要根据实际情况而定。
1、HTTP相对更规范,更标准,更通用,无论哪种语言都支持http协议。如果你是对外开放API,例如开放平台,外部的编程语言多种多样,你无法拒绝对每种语言的支持,现在开源中间件,基本最先支持的几个协议都包含RESTful。
2、RPC 框架作为架构微服务化的基础组件,它能大大降低架构微服务化的成本,提高调用方与服务提供方的研发效率,屏蔽跨进程调用函数(服务)的各类复杂细节。让调用方感觉就像调用本地函数一样调用远端函数、让服务提供方感觉就像实现一个本地函数一样来实现服务。
4. 进程隔离
单体架构中,整个系统运行在同一个进程中,当应用进行部署时,必须停掉当前正在运行的应用,部署完成后再重启进程,无法做到独立部署。
有时候我们会将重复的代码抽取出来封装成组件,在单块架构中,组件通常的形态叫做共享库(如 jar 包或者 DLL),但是当程序运行时,所有组件最终也会被加载到同一进程中运行。
在微服务架构中,应用程序由多个服务组成,每个服务都是高度自治的独立业务实体,可以运行在独立的进程中,不同的服务能非常容易地部署到不同的主机上。
理论上所有服务可以部署在同一个服务器节点,但是并不推荐这么做,因为微服务架构的主旨就是高度自治和高度隔离。
微服务的本质
1. 服务作为组件
微服务也可以被认为是一种组件,但是跟传统组件的区别在于它可以独立部署,因此它的一个显著的优势。另外一个优点是,它在组件与组件之间定义了清晰的、语言无关、平台无关的规范接口,耦合度低,灵活性非常高。但它的不足之处是,分布式调用严重依赖于网络的可靠性和稳定性。
2. 围绕业务组织团队
在单块架构中,企业一般会根据技能划分团队,在这种组织架构下,即便是简单的需求变更都有可能需要跨团队协作,沟通成本很高。而在微服务架构中,它提倡以业务为核心,按照业务能力来组织团队,团队中的成员具有多样性的技能。
3. 关注产品而非项目
在单块架构中,应用基本上是基于“项目模式”构建的,即项目启动时从不同技能资源池中抽取相关资源组成团队,项目结束后释放所有资源。这种情况下团队成员缺乏主人翁意识和产品成就感。
在微服务架构中,提倡采用“产品模式”构建,即更倾向于让团队负责整个服务的生命周期,以便提供更优质的服务。
4. 技术多样性
微服务架构中,提倡针对不同的业务特征选择合适的技术方案,有针对性的解决具体业务问题,而不是像单块架构中采用统一的平台或技术来解决所有问题。
5. 业务数据独立
随着业务的发展,可以方便地选择更合的工具管理或者迁移业务数据。
6. 基础设施自动化
微服务架构提供自主管理其相关的业务数据,这样可以随着业务的发展提供数据接口集成,而不是以数据库的方式同其他服务集成。另外,在微服务架构的实践过程中,对持续交付和部署流水线的要求很高,将促进企业不断寻找更高效的方式完成基础设施的自动化及 DevOps 运维能力的提升。
微服务的优缺点
优点:
- 边界清晰,开发测试维护简单:每个服务职责清晰,只关注于一个业务功能
- 技术栈灵活:每个服务开发语言可不同,只需要把服务注册到注册中心,统一协议
- 松耦合:各个服务间不像单体架构一样通过方法调用
- 可用性:单个服务宕机,不影响其他服务访问,可能影响业务,如果有关联
- 按需扩展:某个服务需要做硬件升级,比如集群,硬件升级等,不影响其他服务
缺点:
- 分布式带来的复杂性:网络延迟、容错性、消息序列化、数据一致性、异步机制、版本化、差异化等
- 运维开销成本增加:整体应用可能只需部署至一小片应用服务区集群,而微服务架构可能变成需要构建/测试/部署/运行数十个独立的服务,并可能需要支持多种语言和环境。
- 服务版本问题:当某个服务接口版本升级,其他调用的单体服务可能都要进行升级
服务架构的落地是存在很多挑战的
1. 分布式系统的复杂性
微服务架构是基于分布式的系统,而构建分布式系统必然会带来额外的开销。
- 性能: 分布式系统是跨进程、跨网络的调用,受网络延迟和带宽的影响。
- 可靠性: 由于高度依赖于网络状况,任何一次的远程调用都有可能失败,随着服务的增多还会出现更多的潜在故障点。因此,如何提高系统的可靠性、降低因网络引起的故障率,是系统构建的一大挑战。
- 异步: 异步通信大大增加了功能实现的复杂度,并且伴随着定位难、调试难等问题。
- 数据一致性: 要保证分布式系统的数据强一致性,成本是非常高的,需要在 C(一致性)A(可用性)P(分区容错性) 三者之间做出权衡。
2. 运维成本
运维主要包括配置、部署、监控与告警和日志收集四大方面。微服务架构中,每个服务都需要独立地配置、部署、监控和收集日志,成本呈指数级增长。
3. 自动化部署
在微服务架构中,每个服务都独立部署,交付周期短且频率高,人工部署已经无法适应业务的快速变化。因此如何有效地构建自动化部署体系,是微服务面临的另一个挑战。
4. DevOps 与组织架构
在微服务架构的实施过程中,开发人员和运维人员的角色发生了变化,开发者将承担起整个服务的生命周期的责任,包括部署和监控;而运维则更倾向于顾问式的角色,尽早考虑服务如何部署。因此,按需调整组织架构、构建全功能的团队,也是一个不小的挑战。
5. 服务间的依赖测试
单块架构中,通常使用集成测试来验证依赖是否正常。而在微服务架构中,服务数量众多,每个服务都是独立的业务单元,服务主要通过接口进行交互,如何保证依赖的正常,是测试面临的主要挑战。
6. 服务间的依赖管理
微服务架构中,服务数量众多,如何清晰有效地展示服务间的依赖关系也是个不小的挑战。
微服务与SOA
微服务是SOA发展出来的产物,它是一种比较现代化的细粒度的SOA实现方式。
SOA(Service-Oriented Architecture 面向服务的架构)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
Spring Cloud
什么是SpringCloud
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、熔断器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
SpringCloud与SpringBoot的关系
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的云应用开发工具;Spring Boot专注于快速、方便集成的单个微服务个体,Spring Cloud关注全局的服务治理框架;Spring Boot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,能不配置就
不配置,Spring Cloud很大的一部分是基于Spring Boot来实现,可以不基于Spring Boot吗?不可以。
Spring Boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring Boot,属于依赖的关系。
SpringCloud主要框架
- 服务注册——Netflix Eureka
- 服务调用——Netflix Feign
- 熔断器——Netflix Hystrix
- 服务网关——Netflix Zuul
- 分布式配置——Spring Cloud Config
- 消息总线 —— Spring Cloud Bus
Spring Cloud和Dubbo对比
或许很多人会说Spring Cloud和Dubbo的对比有点不公平,Dubbo只是实现了服务治理,而Spring Cloud下面有17个子项目(可能还会新增)分别覆盖了微服务架构下的方方面面,服务治理只是其中的一个方面,一定程度来说,Dubbo只是Spring Cloud Netflix中的一个子集。
| Dubbo | Spring Cloud | |
|---|---|---|
| 服务注册中心 | Zookeeper | Spring Cloud Netflix Eureka |
| 服务调用方式 | RPC | REST API |
| 服务网关 | 无 | Spring Cloud Netflix Zuul |
| 熔断器 | 不完善 | Spring Cloud Netflix Hystrix |
| 分布式配置 | 无 | Spring Cloud Config |
| 服务跟踪 | 无 | Spring Cloud Sleuth |
| 消息总线 | 无 | Spring Cloud Bus |
| 数据流 | 无 | Spring Cloud Stream |
| 批量任务 | 无 | Spring Cloud Task |
| …… | …… | …… |
跨域处理
跨域是什么?浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域 。我们是采用前后端分离开发的,也是前后端分离部署的,必然会存在跨域问题。 怎么解决跨域?很简单,只需要在controller类上添加注解@CrossOrigin 即可!这个注解其实是CORS的实现。
CORS(Cross-Origin Resource Sharing, 跨源资源共享)是W3C出的一个标准,其思想是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。因此,要想实现CORS进行跨域,需要服务器进行一些设置,同时前端也需要做一些配置和分析。
分布式ID生成器
由于我们的数据库在生产环境中要分片部署(MyCat),所以我们不能使用数据库本身的自增功能来产生主键值,只能由程序来生成唯一的主键值。我们采用的是开源的twitter的snowflake(雪花)算法。
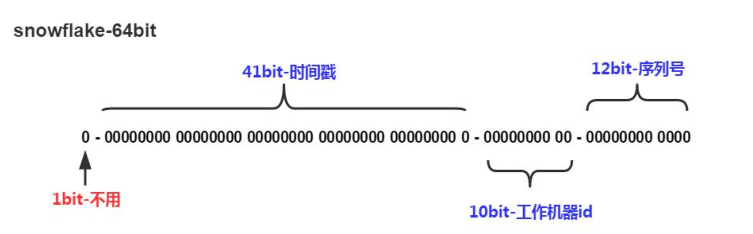
默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1024台机器,序列号支持1毫秒产生4096个自增序列id . SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
常见的认证机制
HTTP Basic Auth
HTTP Basic Auth简单点说明就是每次请求API时都提供用户的username和password,简言之,Basic Auth是配合RESTful API 使用的最简单的认证方式,只需提供用户名密码即可,但由于有把用户名密码暴露给第三方客户端的风险,在生产环境下被使用的越来越少。因此,在开发对外开放的RESTful API时,尽量避免采用HTTP Basic
Auth
Cookie Auth
Cookie认证机制就是为一次请求认证在服务端创建一个Session对象,同时在客户端的浏览器端创建了一个Cookie对象;通过客户端带上来Cookie对象来与服务器端的session对象匹配来实现状态管理的。默认的,当我们关闭浏览器的时候,cookie会被删除。但可以通过修改cookie 的expire time使cookie在一定时间内有效;
OAuth
OAuth(开放授权)是一个开放的授权标准,允许用户让第三方应用访问该用户在某一web服务上存储的私密的资源(如照片,视频,联系人列表),而无需将用户名和密码提供给第三方应用。
OAuth允许用户提供一个令牌,而不是用户名和密码来访问他们存放在特定服务提供者的数据。每一个令牌授权一个特定的第三方系统(例如,视频编辑网站)在特定的时段(例如,接下来的2小时内)内访问特定的资源(例如仅仅是某一相册中的视频)。这样,OAuth让用户可以授权第三方网站访问他们存储在另外服务提供者的某些特定信
息,而非所有内容
下面是OAuth2.0的流程:
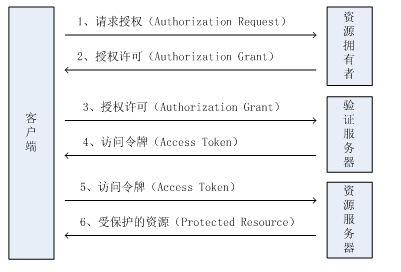
这种基于OAuth的认证机制适用于个人消费者类的互联网产品,如社交类APP等应用,但是不太适合拥有自有认证权限管理的企业应用。
Token Auth
使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
- 客户端使用用户名跟密码请求登录
- 服务端收到请求,去验证用户名与密码
- 验证成功后,服务端会签发一个 Token,再把这个 Token 发送给客户端
- 客户端收到 Token 以后可以把它存储起来,比如放在 Cookie 里
- 客户端每次向服务端请求资源的时候需要带着服务端签发的 Token
- 服务端收到请求,然后去验证客户端请求里面带着的 Token,如果验证成功,就向客户端返回请求的数据
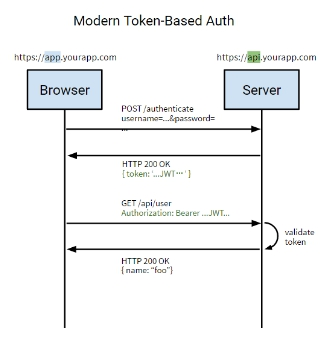
Token Auth的优点
Token机制相对于Cookie机制又有什么好处呢?
支持跨域访问: Cookie是不允许垮域访问的,这一点对Token机制是不存在的,前提是传输的用户认证信息通过HTTP头传输.
无状态(也称:服务端可扩展行):Token机制在服务端不需要存储session信息,因为Token 自身包含了所有登录用户的信息,只需要在客户端的cookie或本地介质存储状态信息.
更适用CDN: 可以通过内容分发网络请求你服务端的所有资料(如:javascript,HTML,图片等),而你的服务端只要提供API即可.
去耦: 不需要绑定到一个特定的身份验证方案。Token可以在任何地方生成,只要在你的API被调用的时候,你可以进行Token生成调用即可.
更适用于移动应用: 当你的客户端是一个原生平台(iOS, Android,Windows 8等)时,Cookie是不被支持的(你需要通过Cookie容器进行处理),这时采用Token认证机制就会简单得多。
CSRF:因为不再依赖于Cookie,所以你就不需要考虑对CSRF(跨站请求伪造)的防范。
性能: 一次网络往返时间(通过数据库查询session信息)总比做一次HMACSHA256计算 的Token验证和解析要费时得多.
不需要为登录页面做特殊处理: 如果你使用Protractor 做功能测试的时候,不再需要为登录页面做特殊处理.
基于标准化:你的API可以采用标准化的 JSON Web Token (JWT). 这个标准已经存在多个后端库(.NET, Ruby, Java,Python, PHP)和多家公司的支持(如:Firebase,Google, Microsoft).
基于JWT的Token认证机制实现
什么是JWT
JSON Web Token(JWT)是一个非常轻巧的规范。这个规范允许我们使用JWT在用户和服务器之间传递安全可靠的信息。
JWT组成
一个JWT实际上就是一个字符串,它由三部分组成,头部、载荷与签名。
头部(Header)
头部用于描述关于该JWT的最基本的信息,例如其类型以及签名所用的算法等。这也可以被表示成一个JSON对象。
1 | {"typ":"JWT","alg":"HS256"} |
在头部指明了签名算法是HS256算法。 我们进行BASE64编码http://base64.xpcha.com/,编码后的字符串如下:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
小知识:Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。JDK 中提供了非常方便的 BASE64Encoder 和 BASE64Decoder,用它们可以非常方便的完成基于 BASE64 的编码和解码.
载荷(playload)
载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些有效信息包含三个部分
(1)标准中注册的声明(建议但不强制使用)
1 | iss: jwt签发者 |
(2)公共的声明
公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密.
(3)私有的声明
私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。这个指的就是自定义的claim。比如前面那个结构举例中的admin和name都属于自定的claim。这些claim跟JWT标准规定的claim区别在于:JWT规定的claim,JWT的接收方在拿到JWT之后,都知道怎么对这些标准的claim进行验证(还不知道是否能够验证);而private claims不会验证,除非明确告诉接收方要对这些claim进行验证以及规则才行。
定义一个payload:
1 | {"sub":"1234567890","name":"John Doe","admin":true} |
然后将其进行base64编码,得到Jwt的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
签证(signature)
jwt的第三部分是一个签证信息,这个签证信息由三部分组成:
- header (base64后的)
- payload (base64后的)
- secret
这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。
TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
Java的JJWT实现JWT
什么是JJWT
JJWT是一个提供端到端的JWT创建和验证的Java库。永远免费和开源(Apache License,版本2.0),JJWT很容易使用和理解。它被设计成一个以建筑为中心的流畅界面,隐藏了它的大部分复杂性。
JJWT快速入门
token的创建
(1)创建maven工程,引入依赖
1 | <dependency> |
(2)创建类CreateJwtTest,用于生成token
1 | public class CreateJwtTest { |
setIssuedAt用于设置签发时间, signWith用于设置签名秘钥
(3)测试运行,输出如下:
eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiI4ODgiLCJzdWIiOiLlsI_nmb0iLCJpYXQiOjE1MjM0MTM0NTh9.gq0J‐cOM_qCNqU_s‐d_IrRytaNenesPmqAIhQpYXHZk
再次运行,会发现每次运行的结果是不一样的,因为我们的载荷中包含了时间。
token的解析
我们刚才已经创建了token ,在web应用中这个操作是由服务端进行然后发给客户端,客户端在下次向服务端发送请求时需要携带这个token(这就好像是拿着一张门票一样),那服务端接到这个token 应该解析出token中的信息(例如用户id),根据这些信息查询数据库返回相应的结果。
创建ParseJwtTest
1 | public class ParseJwtTest { |
试着将token或签名秘钥篡改一下,会发现运行时就会报错,所以解析token也就是验证token
token过期校验
有很多时候,我们并不希望签发的token是永久生效的,所以我们可以为token添加一个过期时间。
创建CreateJwtTest2
1 | public class CreateJwtTest2 { |
setExpiration 方法用于设置过期时间
修改ParseJwtTest
1 | public class ParseJwtTest { |
测试运行,当未过期时可以正常读取,当过期时会引发io.jsonwebtoken.ExpiredJwtException异常。
自定义claims
我们刚才的例子只是存储了id和subject两个信息,如果你想存储更多的信息(例如角色)可以定义自定义claims
创建CreateJwtTest3
1 | public class CreateJwtTest3 { |
修改ParseJwtTest
1 | public class ParseJwtTest { |
MongoDB
什么是MongoDB
MongoDB 是一个跨平台的,面向文档的数据库,是当前 NoSQL 数据库产品中最热门的一种。它介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的产品。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。
MongoDB特点
MongoDB 最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它是一个面向集合的,模式自由的文档型数据库。
具体特点总结如下:
(1)面向集合存储,易于存储对象类型的数据
(2)模式自由
(3)支持动态查询
(4)支持完全索引,包含内部对象
(5)支持复制和故障恢复
(6)使用高效的二进制数据存储,包括大型对象(如视频等)
(7)自动处理碎片,以支持云计算层次的扩展性
(8)支持各种语言的驱动程序
(9) 文件存储格式为 BSON(一种 JSON 的扩展)
MongoDB体系结构
MongoDB 的逻辑结构是一种层次结构。主要由:文档(document)、集合(collection)、数据库(database)这三部分组成的。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。
(1)MongoDB 的文档(document),相当于关系数据库中的一行记录。
(2)多个文档组成一个集合(collection),相当于关系数据库的表。
(3)多个集合(collection),逻辑上组织在一起,就是数据库(database)。
(4)一个 MongoDB 实例支持多个数据库(database)。
文档(document)、集合(collection)、数据库(database)的层次结构如下图:
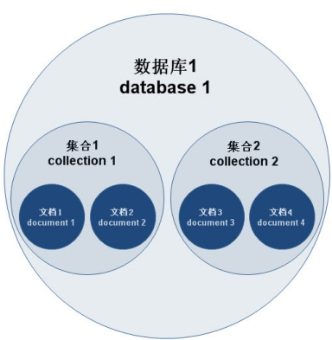
下表是MongoDB与MySQL数据库逻辑结构概念的对比
| MongoDb | 关系型数据库Mysql |
|---|---|
| 数据库(databases) | 数据库(databases) |
| 集合(collections) | 表(table) |
| 文档(document) | 行(row) |
数据类型
基本数据类型
null:用于表示空值或者不存在的字段,{“x”:null}
布尔型:布尔类型有两个值true和false,{“x”:true}
数值:shell默认使用64为浮点型数值。{“x”:3.14}或{“x”:3}。对于整型值,可以使用 NumberInt(4字节符号整数)或NumberLong(8字节符号整数),{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
字符串:UTF-8字符串都可以表示为字符串类型的数据,{“x”:“呵呵”}
日期:日期被存储为自新纪元依赖经过的毫秒数,不存储时区,{“x”:new Date()}
正则表达式:查询时,使用正则表达式作为限定条件,语法与JavaScript的正则表达式相同,{“x”:/[abc]/}
数组:数据列表或数据集可以表示为数组,{“x”: [“a“,“b”,”c”]}
内嵌文档:文档可以嵌套其他文档,被嵌套的文档作为值来处理,{“x”:{“y”:3 }}
对象Id:对象id是一个12字节的字符串,是文档的唯一标识,{“x”: objectId() }
二进制数据:二进制数据是一个任意字节的字符串。它不能直接在shell中使用。如果要将非utf-字符保存到数据库中,二进制数据是唯一的方式。
代码:查询和文档中可以包括任何JavaScript代码,{“x”:function(){/…/}}
常用命令
选择和创建数据库
选择和创建数据库的语法格式:
use 数据库名称
如果数据库不存在则自动创建
插入与查询文档
插入文档的语法格式:
db.集合名称.insert(数据);
查询集合的语法格式:
db.集合名称.find()
这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。
修改与删除文档
修改文档的语法结构:
db.集合名称.update(条件,修改后的数据)
删除文档的语法结构:
db.集合名称.remove(条件)
统计条数
统计记录条件使用count()方法。以下语句统计spit集合的记录数
db.spit.count()
模糊查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
/模糊查询字符串/
例如,我要查询吐槽内容包含“流量”的所有文档,代码如下:
db.spit.find({content:/流量/})
大于 小于 不等于
<, <=, >, >= 这个操作符也是很常用的,格式如下:
1 | db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value |
包含与不包含
包含使用$in操作符。
示例:查询吐槽集合中userid字段包含1013和1014的文档
db.spit.find({userid:{$in:["1013","1014"]}})
不包含使用$nin操作符。
示例:查询吐槽集合中userid字段不包含1013和1014的文档
db.spit.find({userid:{$nin:["1013","1014"]}})
条件连接
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相当于SQL的and)
格式为:
$and:[ { },{ },{ } ]
示例:查询吐槽集合中visits大于等于1000 并且小于2000的文档
db.spit.find({$and:[ {visits:{$gte:1000}} ,{visits:{$lt:2000} }]})
列值增长
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用$inc运算符来实现
db.spit.update({_id:"2"},{$inc:{visits:NumberInt(1)}} )
Java操作MongoDB
mongodb-driver是mongo官方推出的java连接mongoDB的驱动包,相当于JDBC驱动。我们通过一个入门的案例来了解mongodb-driver的基本使用
查询全部记录
(1)创建工程 mongoDemo, 引入依赖
1 | <dependencies> |
(2)创建测试类
1 | /** |
条件查询
BasicDBObject对象:表示一个具体的记录,BasicDBObject实现了DBObject,是key-value的数据结构,用起来和HashMap是基本一致的。
(1)查询userid为1013的记录
1 | public class MongoDemo1 { |
(2)查询浏览量大于1000的记录
1 | public class MongoDemo2 { |
插入数据
1 | public class MongoDemo3 { |
SpringDataMongoDB
SpringData家族成员之一,用于操作MongoDb的持久层框架,封装了底层的mongodb-driver。
官网主页: https://projects.spring.io/spring-data-mongodb/
ElasticSearch
什么是ElasticSearch
Elasticsearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch特点
- 可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上
- 将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;
- 开箱即用的,部署简单
- 全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理
ElasticSearch体系结构
下表是Elasticsearch与MySQL数据库逻辑结构概念的对比
| Elasticsearch | 关系型数据库Mysql |
|---|---|
| 索引(index) | 数据库(databases) |
| 类型(type) | 表(table) |
| 文档(document) | 行(row) |
Head插件
在学习Elasticsearch的过程中,必不可少需要通过一些工具查看es的运行状态以及数据。如果都是通过rest请求,未免太过麻烦,而且也不够人性化。此时,head可以完美的帮助你快速学习和使用es。
Head插件可以实现基本信息的查看,rest请求的模拟,数据的检索等等。
IK分词器
IK分词是一款国人开发的相对简单的中文分词器。虽然开发者自2012年之后就不在维护了,但在工程应用中IK算是比较流行的一款!
项目整理
应用世界
Hacker News排名算法
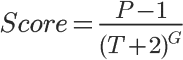
P:表示帖子的得票数,减去1是为了忽略发帖人的投票。
T:表示距离发帖的时间(单位为小时),加上2是为了防止最新的帖子导致分母过小(之所以选择2,可能是因为从原始文章出现在其他网站,到转贴至Hacker News,平均需要两个小时)。
G:表示”重力因子”(gravityth power),即将帖子排名往下拉的力量,默认值为1.8
结论:
- 得票越多,排名越高。
- 发帖时间越新,排名越高。或者说,帖子的排名会随着时间不断下降。(经过24小时之后,所有帖子的得分基本上都小于1)
- 重力因子G数值大小决定了排名随时间下降的速度。G值越大,排名下降得越快。
缺点:用户只能投赞成票,不允许用户投反对票
项目中的代码
1 | public class RankingUtil { |
应用:应用世界中的应用排名。后期需求要求可以手动排名,加了排序数字段。将距离应用上架时间和重力因子作为动态配置参数,通过sprint boot的actuator的自动监听实现在不重启服务器的情况下自动刷新配置。
Shiro
概念解释
SecurityManager
这个类是shiro的核心,shiro的所有功能(登录校验、授权)都是通过这个类实现的。但是他其实什么都不做,他只是一个平台,就像淘宝一样,自己啥也不卖,而是让别人卖 。securityManager是通过它内部的属性来实现的各种功能的,其中最主要的就是Reaml。
Realm
realm有“域”的意思,引申为“来源”,也就是说某些东西原来是在哪的,在shiro判断某个用户能不能登录或者是能不能做什么事的时候,他需要知道之前程序对该用户的信息(比如用户名,密码,角色,权限)的存储放在哪里,这个“哪里”就是realm,我们在实际开发中只有一个域,那就是关系型数据库中的User表,但是有的情况下可能有多个域,比如某些网站允许你使用qq号登陆,也允许你使用自己注册的账号登陆,那就有两个域。简单一句话,域就是存储用户信息的地方,这个很好理解。在以后shiro的登录校验和权限管理的时候都是需要这个接口的,因为他存储了所有的信息。他的实现类有AuthenticationRealm,用来处理登录,AuthorizingRealm,用来处理访问权限。Realm就是提供AuthorizationInfo(权限认证结果)和AuthenticationInfo(登录认证结果)这两个对象的地方。
AuthenticationToken
校验的标签,这个类使用在用户登录的时候,用户填写了用户名+密码,然后我们将其封装在这个类中,用来和数据库中的比较,然后得出结果,返回的结果就是下一个类。
AuthenticationInfo
校验的信息,这个类是在校验完了用户登录之后产生的,校验的结果有很多种,比如根本不存在这个用户或者有用户但是密码不对或者当前用于由于多次输入错误密码而被锁定或者当前用户没有激活(有的情况下可能需要用邮箱激活)或者是重复登录等等,完全可以定义自己的校验失败的情况。在校验成功之后,我们就要返回一个AuthenticationInfo,里面包含了这个用户的很多标示符Principal(不仅仅是用户名)和密码(Credential)。
Principal
是主体(subject)进行身份认证的标识,标识必须具有唯一性,如用户名、手机号、邮箱地址等,一个主体可以有多个身份,但是必须有一个主身份(Primary Principal)。
subject
就是用户,user。只不过这里的user并不一定是一个人,而是任何可能会访问我们应用的请求,比如定期调度的工作。
策略模式实现多模式上架应用
上架应用时可以指定应用的模式:
- 默认模式:什么都不做
- 过期时间模式:到达指定时间够自动下架应用
- 用户数模式:当有指定数量的用户点击过该应用后自动下架
- 点击数模式:当有指定数量的点击数后自动下架应用
用户的每次点击操作都会触发模式处理。用户点击后先找到对应应用的模式ID根据模式ID返回不用的模式处理器进行相应处理。
策略模式和工厂模式在结构上很像,但工厂是创建型模式,它的作用就是创建对象; 而策略是行为型模式,它的作用是让一个对象在许多行为中选择一种行为;
腾讯云OSS对象存储
结合腾讯云的官方文档和SDK实现即可。上传图片就是先把图片上传到服务器,然后再上传到腾讯云,得到图片链接地址后存到数据库,再将服务器上的图片文件删除即可。
Beetl
Beetl(“bi tou”)对java语言的良好支持和很好的性能。官网说性能是Freemarker的6倍。它的语法官方文档上全都有很方便,而且都是中文。
那么为什么要用模板引擎呢?很简单的原因,实际应用场景中文本的格式是固定的,但是内容有所不同。如果是不复杂的内容我们可以直接用代码生成需要的文本。但是当文本变得复杂的时候,我们用java生成文本的性能就会下降,同时也不利于维护。解决办法是将数据和格式进行分离,将一个文本分成模板和数据。模板中有固定的格式,需要动态变化的数据一般用占位符代替。这样我们想改模板格式的时候不需要去更改代码,只需要去改模板就可以了。同时模板引擎渲染文本的效率也会更高。
页面静态化
应用世界中将应用的介绍页面使用Beetl生成静态化的HTML页面放入腾讯云的OSS中。适合静态化的页面是哪些很少变动,访问量又大的页面。
通过GroupTemplate 来生成页面:
1 | public void BeetlString() throws Exception { |
结果:
2
3
4
5
6
7
8
<head>
<title>This is a test template Email.</title>
</head>
<body>
<h1>beetl</h1>
</body>
</html>
THNews资讯分享平台
分布式 ID 生成器
由于分布式下的分库分表(太难了,不是我做的)需要保证全局唯一的ID,故需要分布式 ID 生成器来生成 ID。使用最多的是Twitter公司的SnowFlake算法,就是著名的《雪花算法》。
SnowFlake原理
SnowFlake产生的ID是一个64位的整型,结构如下(每一部分用“-”符号分隔):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
1位:标识,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以为0;
41位:时间戳部分,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年;
10位:节点部分,Twitter实现中使用前5位作为数据中心标识,后5位作为机器标识,可以部署1024个节点;
12位:序列号部分,支持同一毫秒内同一个节点可以生成4096个ID;
SnowFlake算法生成的ID大致上是按照时间递增的,用在分布式系统中时,需要注意数据中心标识和机器标识必须唯一,这样就能保证每个节点生成的ID都是唯一的!
有状态(SESSION)和无状态(JWT)登录验证
有状态的登录验证就是将会话信息存放在服务器中。而无状态的登录验证就是服务器不存会话信息。
| 有状态 | 无状态 | |
|---|---|---|
| 数据同步 | 需要同步 | 无需同步 |
| 资源消耗 | 消耗内存资源保存数据 消耗带宽进行数据同步 |
无内存消耗 无带宽消耗 耗费CPU计算资源 |
由于HTTP 协议是无状态的,要保存用户状态需要额外的机制。一般有两种方式,Session和JWT,session是有状态的,jwt是无状态的。
Session 原理
最传统的用户认证方式。用户首次访问应用服务器后建立会话,服务器可以使用 Set-Cookie 这个 HTTP Header,将会话的 SessionID 写入在用户端保存的 Cookie 中。下次用户再次向这个域名发请求时会携带所有 Cookie 信息,包括这个 SessionID。
Session 信息保存在服务器端,而用于唯一标识这个 Session 的 SessionID 则保存在对应客户端的 Cookie 中。SessionID 这个会话标识符本质上是一个随机字符串,每个用户的 SessionID 都不一样。
Session 中可以保存很多信息。例如设置一个 IsLogin 字段,用户通过账号密码登录后,将这个字段设置为 TRUE。这样,在 Session 的有效期内(比如 2 小时),即使用户关闭网页,再次打开后仍会保持登录状态(除非用户清理了 Cookie,导致其访问服务器时没有携带 SessionID 字段)。对于其他的常用字段(如 userID、userName等)也可以添加到 Session 中,以减少数据库的访问压力,但注意不要太大,因为所有用户的会话信息都是保存在服务器的内存中的。
JWT 原理
JWT(JSON web token)是一种认证协议,可以发布接入令牌(Access Token,保持在客户端)并对发布的签名接入令牌进行验证。令牌(Token)本身包含一系列声明,应用程序可以根据这些声明限制用户对资源的访问。
JWT 由三段信息构成的:header、payload、signature
JWT 工作流程
用户通过账号密码发起登录请求服务器验证通过后,设置 header 和 payload,并得到加密后的签名,然后将这三部分作为 Token 发送给用户,客户端保存 Token,并在每个请求中附加这个 Token。如果请求携带了 Token,服务器会验证这个 Token 并根据验证结果进行不同处理。
发送请求时,Token 放在请求的 HTTP Header 中。另外,如果发生跨域,例如 www.xx.com 下发出到 api.xx.com 的请求,需要在服务端开启 CORS(Cross-Origin Resource Sharing 跨域资源共享),只需要在controller类上添加注解@CrossOrigin 即可!
基于JWT的Token认证机制
什么是JWT
JSON Web Token(JWT)是一个非常轻巧的规范。这个规范允许我们使用JWT在用户和服务器之间传递安全可靠的信息。
JWT组成
一个JWT实际上就是一个字符串,它由三部分组成,头部、载荷与签名。
头部(Header)
头部用于描述关于该JWT的最基本的信息,例如其类型以及签名所用的算法等。这也可以被表示成一个JSON对象。
1 | {"typ":"JWT","alg":"HS256"} |
在头部指明了签名算法是HS256算法。 我们进行BASE64编码http://base64.xpcha.com/,编码后的字符串如下:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
小知识:Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。JDK 中提供了非常方便的 BASE64Encoder 和 BASE64Decoder,用它们可以非常方便的完成基于 BASE64 的编码和解码.
载荷(playload)
载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些有效信息包含三个部分
(1)标准中注册的声明(建议但不强制使用)
1 | iss: jwt签发者 |
(2)公共的声明
公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密.
(3)私有的声明
私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。这个指的就是自定义的claim。比如前面那个结构举例中的admin和name都属于自定的claim。这些claim跟JWT标准规定的claim区别在于:JWT规定的claim,JWT的接收方在拿到JWT之后,都知道怎么对这些标准的claim进行验证(还不知道是否能够验证);而private claims不会验证,除非明确告诉接收方要对这些claim进行验证以及规则才行。
定义一个payload:
1 | {"sub":"1234567890","name":"John Doe","admin":true} |
然后将其进行base64编码,得到Jwt的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
签证(signature)
jwt的第三部分是一个签证信息,这个签证信息由三部分组成:
- header (base64后的)
- payload (base64后的)
- secret
这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。
TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
Java的JJWT实现JWT
什么是JJWT
JJWT是一个提供端到端的JWT创建和验证的Java库。永远免费和开源(Apache License,版本2.0),JJWT很容易使用和理解。它被设计成一个以建筑为中心的流畅界面,隐藏了它的大部分复杂性。
JJWT快速入门
token的创建
(1)创建maven工程,引入依赖
1 | <dependency> |
(2)创建类CreateJwtTest,用于生成token
1 | public class CreateJwtTest { |
setIssuedAt用于设置签发时间, signWith用于设置签名秘钥
(3)测试运行,输出如下:
eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiI4ODgiLCJzdWIiOiLlsI_nmb0iLCJpYXQiOjE1MjM0MTM0NTh9.gq0J‐cOM_qCNqU_s‐d_IrRytaNenesPmqAIhQpYXHZk
再次运行,会发现每次运行的结果是不一样的,因为我们的载荷中包含了时间。
token的解析
我们刚才已经创建了token ,在web应用中这个操作是由服务端进行然后发给客户端,客户端在下次向服务端发送请求时需要携带这个token(这就好像是拿着一张门票一样),那服务端接到这个token 应该解析出token中的信息(例如用户id),根据这些信息查询数据库返回相应的结果。
创建ParseJwtTest
1 | public class ParseJwtTest { |
试着将token或签名秘钥篡改一下,会发现运行时就会报错,所以解析token也就是验证token
token过期校验
有很多时候,我们并不希望签发的token是永久生效的,所以我们可以为token添加一个过期时间。
创建CreateJwtTest2
1 | public class CreateJwtTest2 { |
setExpiration 方法用于设置过期时间
修改ParseJwtTest
1 | public class ParseJwtTest { |
测试运行,当未过期时可以正常读取,当过期时会引发io.jsonwebtoken.ExpiredJwtException异常。
自定义claims
我们刚才的例子只是存储了id和subject两个信息,如果你想存储更多的信息(例如角色)可以定义自定义claims
创建CreateJwtTest3
1 | public class CreateJwtTest3 { |
修改ParseJwtTest
1 | public class ParseJwtTest { |
MongoDB
吐槽和评论两项功能存在以下特点:
(1)数据量大
(2)写入操作频繁
(3)价值较低
对于这样的数据,我们更适合使用MongoDB来实现数据的存储
什么是MongoDB
MongoDB 是一个跨平台的,面向文档的数据库,它介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的产品。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。
MongoDB 最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它是一个面向集合的,模式自由的文档型数据库。
MongoDB 的逻辑结构是一种层次结构。主要由:
文档(document)、集合(collection)、数据库(database)这三部分组成的。
(1)MongoDB 的文档(document),相当于关系数据库中的一行记录。
(2)多个文档组成一个集合(collection),相当于关系数据库的表。
(3)多个集合(collection),逻辑上组织在一起,就是数据库(database)。
(4)一个 MongoDB 实例支持多个数据库(database)
基本数据类型
- null:用于表示空值或者不存在的字段,{“x”:null}
- 布尔型:布尔类型有两个值true和false,{“x”:true}
- 数值:shell默认使用64为浮点型数值。{“x”:3.14}或{“x”:3}。对于整型值,可以使用 NumberInt(4字节符号整数)或NumberLong(8字节符号整数),{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
- 字符串:UTF-8字符串都可以表示为字符串类型的数据,{“x”:“呵呵”}
- 日期:日期被存储为自新纪元依赖经过的毫秒数,不存储时区,{“x”:new Date()}
- 正则表达式:查询时,使用正则表达式作为限定条件,语法与JavaScript的正则表达式相同,{“x”:/[abc]/}
- 数组:数据列表或数据集可以表示为数组,{“x”: [“a“,“b”,”c”]}
- 内嵌文档:文档可以嵌套其他文档,被嵌套的文档作为值来处理,{“x”:{“y”:3 }}
- 对象Id:对象id是一个12字节的字符串,是文档的唯一标识,{“x”: objectId() }
- 二进制数据:二进制数据是一个任意字节的字符串。它不能直接在shell中使用。如果要将非utf-字符保存到数据库中,二进制数据是唯一的方式。
- 代码:查询和文档中可以包括任何JavaScript代码,{“x”:function(){/…/}}
Java操作MongoDB
mongodb-driver是mongo官方推出的java连接mongoDB的驱动包,相当于JDBC驱动。
SpringDataMongoDB是SpringData家族成员之一,用于操作MongoDb的持久层框架,封装了底层的mongodb-
driver
1 | /** |
1 |
|
Redis
文章模块将文章放在缓存中
1 |
|
Spring Cache的使用
活动详情的缓存采用Spring Cache实现
使用Spring Cache只需要记住三个主机即可:
- @EnableCaching:加在启动类上开启缓存支持。
- @Cacheable:使用这个注解的方法在执行后会缓存其返回结果。
- @CacheEvict:使用这个注解的方法在其执行前或执行后移除Spring Cache中的某些元素。
1 | /** |
RabbitMQ
ActiveMQ没有交换机的概念,直接将消息发送到队列中。
交换器(Exchange)连接队列(Queue)的方式常用的有三种:直接模式、分列模式、主题模式。
直连模式就是通过默认的交换器(默认的交换器名字为一个空字符串
"")将消息转发到队列中。分列模式通过交换器与队列的绑定(Binding),交换器会将消息转发到所有绑定的队列中。
主题模式也需要绑定交换器与队列,但每个队列都只关心部分消息,即交换器只会将队列关心的消息转发到对应的队列中。
项目中的短信验证码用到了RabbitMQ和Redis来实现。
用户注册后将手机号作为key,验证码作为value,存放在缓存中,设置过期时间为五分钟。
将手机号和验证码放到map中,然后发送到以“sms”为名字的队列中(使用的是直连模式)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
private RedisTemplate redisTemplate;
private RabbitTemplate rabbitTemplate;
/**
* 发送短信验证码
* @param mobile 手机号
*/
public void sendSms(String mobile){
//1.生成6位短信验证码
Random random=new Random();
int max=999999;//最大数
int min=100000;//最小数
int code = random.nextInt(max);//随机生成
if(code<min){
code=code+min;
}
System.out.println("给"+mobile+"发送的验证码是:"+code);
//2.将验证码放入redis
redisTemplate.opsForValue().set("smscode_"+mobile, code+"" ,5,
TimeUnit.MINUTES );//五分钟过期
//3.将验证码和手机号发动到rabbitMQ中
Map<String,String> map=new HashMap();
map.put("mobile",mobile);
map.put("code",code+"");
rabbitTemplate.convertAndSend("sms",map);
}短信模块中添加消息监听器处理消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* 短信监听类
*/
(queues = "sms")
public class SmsListener {
private SmsUtil smsUtil;
("${aliyun.sms.template_code}")
private String template_code;//模板编号
("${aliyun.sms.sign_name}")
private String sign_name;//签名
public void sendSms(Map<String,String> map){
System.out.println("手机号:"+map.get("mobile"));
System.out.println("验证码:"+map.get("code"));
try {
smsUtil.sendSms(map.get("mobile"),template_code,sign_name,"{\"number\":\""+ map.get("code") +"\"}");
} catch (ClientException e) {
e.printStackTrace();
}
}
}
Elasticsearch
什么是ElasticSearch
Elasticsearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch体系结构
| Elasticsearch | 关系型数据库Mysql |
|---|---|
| 索引(index) | 数据库(databases) |
| 类型(type) | 表(table) |
| 文档(document) | 行(row) |
默认情况下,Elastic 只允许本机访问,不允许跨域调用,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,增加以下两句命令:
1 | http.cors.enabled: true |
基本概念
Node 与 Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
1
2
3
4
5{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
Type
Document 可以分组,比如
weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。不同的 Type 应该有相似的结构(schema),举例来说,
id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
Head插件
一般使用图形化界面来实现Elasticsearch的日常管理,最常用的就是Head插件。
IK分词器
ES默认的中文分词是将每个字看成一个词,这显然是不符合要求的,所以我们需要安装中文分词器来解决这个问题。
IK分词是一款国人开发的相对简单的中文分词器。虽然开发者自2012年之后就不在维护了,但在工程应用中IK算是比较流行的一款!
搜索模块的开发
加依赖写配置
1
2
3
4spring:
data:
elasticsearch:
cluster‐nodes: 127.0.0.1:9300创建文章实体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/**
* 文章实体类
*/
(indexName="tensquare",type="article")
public class Article implements Serializable{
private String id;//ID
(index= true,analyzer="ik_max_word",searchAnalyzer="ik_max_word")
private String title;//标题
(index= true,analyzer="ik_max_word",searchAnalyzer="ik_max_word")
private String content;//文章正文
private String state;//审核状态
}创建数据访问接口(DAO)
1
2
3
4
5
6
7
8
9
10
11
12
13/**
* 文章数据访问层接口
*/
public interface ArticleSearchDao extends ElasticsearchRepository<Article,String> {
/**
* 检索
* @param
* @return
*/
public Page<Article> findByTitleOrContentLike(String title, String content, Pageable pageable);
}
elasticsearch与MySQL数据同步
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
MySQL数据导入Elasticsearch
在logstash-5.6.8安装目录下创建文件夹mysqletc (名称随意)
文件夹下创建mysql.conf (名称随意) ,内容如下:
1 | input { |
- 将mysql驱动包mysql-connector-java-5.1.46.jar拷贝至D:/logstash-5.6.8/mysqletc/ 下 。D:/logstash-5.6.8是你的安装目录
- 每间隔1分钟就执行一次sql查询。