
简介
什么是Redis
有哪些公司在使用Redis
GitHub, Twitter, Stackoverflow, Alibaba, 百度,微博,美团,搜狐
Redis的八大特性
- 速度快
- 支持持久化
- 存在多种数据结构
- 支持多种语言
- 功能丰富
- 简单(代码量小,使用方便)
- 主从复制
- 高可用,分布式
速度快
官方给的指标是10w OPS(每秒十万次读写)
这么快的原因:
数据存放在内存中
使用C语言编写(大约五万行代码),C语言离操作系统较近
线程模型为单线程
持久化
Redis所有数据保存在内存中,对数据的更新将异步的保存到磁盘上。
多种数据结构
五大数据结构:
- Strings
- Hash Tables
- Linked Lists
- Sets
- Sorted Sets
其他新结构:
- BitMaps: 位图(本质是字符串,可以实现类似布隆过滤器的功能)
- HyperLogLog:超小内存唯一值计数(本质是字符串)
- GEO:地理信息定位(本质是有序集合,Redis-3.2后提供)
支持多种客户端语言
Java,PHP,python,Ruby,Lua,nodejs
功能丰富
- 发布订阅模式
- Lua脚本
- 事务
- pipeline(提高客户端并发效率)
典型应用场景
- 缓存系统
- 计数器(微博的转发数,评论数以及视频网站的播放数等)
- 消息队列系统
- 排行榜
- 社交网络(粉丝数,关注数,共同关注数)
- 实时系统(垃圾邮件处理系统,布隆过滤器)
安装Redis
Redis安装
Linux系统下安装Redis
1 | 1. 下载 |
可执行文件说明
| 可执行文件 | 说明 |
|---|---|
| redis-server | Redis服务器 |
| redis-cli | Redis命令行客户端 |
| redis-benchmark | Redis性能测试工具 |
| redis-check-aof | AOF文件修复工具 |
| redis-check-dump | RDB文件修复工具 |
| redis-sentinel | Sentinel服务器(2.8以后) |
三种启动方法
最简启动
直接使用redis-server
动态参数启动
1 | redis-server --port 6380 # 默认端口是6379 |
配置文件启动
1 | redis-server configPath |
验证方法
1 | ps -ef|grep redis |
比较
- 生产环境推荐配置启动
- 单机多实例配置文件可以用端口区分开
简单的客户端连接
连接
1 | redis-cli -h 10.10.79.150 -p 6384 |
返回值
- 状态回复(如
ping返回PONG) - 错误回复(如
(error) WRONGTYPE Operation against) - 整数回复(如
incr hello回复(integer) 1) - 字符串回复(如
get hello回复"world") - 多行字符串回复(如
mget hello foo返回"world" "bar")
Redis常用配置
| 属性 | 说明 |
|---|---|
| daemonize | 是否是守护进程(no默认|yes推荐) |
| port | Redis对外端口号,默认为6379 7379对应手机按键上MERZ对应的号码,MERZ取自意大利歌女Alessia Merz的名字 |
| logfile | Redis系统日志 |
| dir | Redis工作目录 |
Redis API
通用命令
keys
eg:
keys *遍历所有的key怎么用:
热备从节点
scan
dbsize
计算key的总数
exists key
检查key是否存在,存在返回1,否则返回0
del key [key …]
删除指定key-value,成功返回1,否则返回0
expire key seconds
ttl key查看key剩余的过期时间persist key去掉key的过期时间type key
返回key的类型(string,hash,list,set,zset,none)
| 命令 | 时间复杂度 |
|---|---|
| keys | O(n) |
| dbsize | O(1) |
| del | O(1) |
| exists | O(1) |
| expire | O(1) |
| type | O(1) |
数据结构和内部编码
内部编码
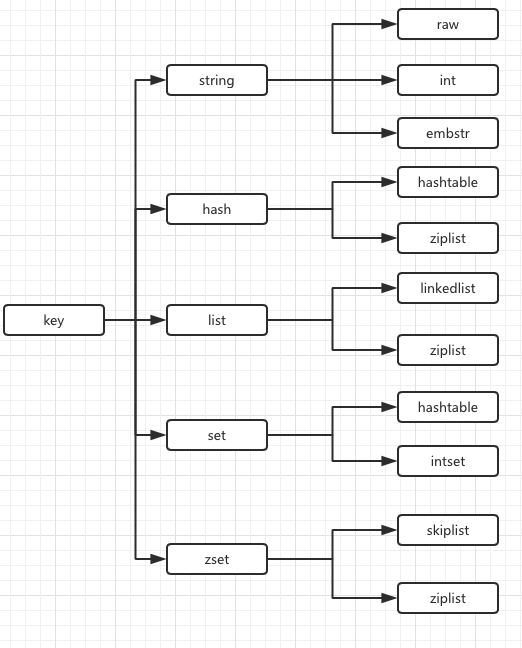
字符串键值结构
| key | value |
|---|---|
| hello | world |
| counter | 1 |
| bits | |1|0|1|1|1|0|1| |
| { “prodduct”:{ “id”: “3242” “name”: “test423” } } |
Value up to 512MB,up to 100k is recommended
场景
- 缓存
- 计数器
- 分布式锁
命令
1 | 1. 获取key对应的value O(1) |
1 | 1. key自增1,如果key不存在,自增后get(key)=1 O(1) |
1 | 1. 不管key是否存在,都设置 O(1) |
1 | 1. 批量获取key,原子操作 O(n) |
n次get = n次网络时间 + n次命令时间
1次mget = 1次网络时间 + n次命令时间
1 | 1. set key newvalue并返回旧的value O(1) |
1 | 1. 增加key对应的值3.5 O(1) |
复杂度总结
| 命令 | 含义 | 复杂度 |
|---|---|---|
| set key value | 是指key-value | O(1) |
| get key | 获取key-value | O(1) |
| del key | 删除key-value | O(1) |
| setnx setxx | 根据key是否存在设置key-value | O(1) |
| Incr decr | 计数 | O(1) |
| mget mset | 批量操作key-value | O(n) |
实战
记录网站每个用户个人主页的访问量?
1
incr userid:pageview
缓存视频的基本信息(数据源在MySQL中)伪代码
1
2
3
4
5
6
7
8
9
10
11
12public VideoInfo get(long id){
String redisKey = redisPrefix + id;
VideoInfo videoInfo = redis.get(redisKey);
if(videoInfo == null){
videoInfo = mysql.get(id);
if(videoInfo != null){
//序列化
redis.set(redisKey, serialize(videoInfo));
}
}
return videoInfo;
}分布式计数器
incr id (原子操作)
Hash键值结构
| key | field | value |
|---|---|---|
| user:1:info | name age Date |
Ronaldo 32 239 |
特点
是一个
value为Map的Mapfield不能相同,value可以相同
API
所有以哈希为结构的命令都是以H开头的。
1 | 1. 获取hash key对应的field的value O(1) |
1 | 1. 判断hash key是否有field O(1) |
1 | 1. 批量获取hash key的一批field对应的值 O(n) |
1 | 1. 返回hash key对应所有的field和value O(n) |
1 | 1. 设置hash key对应field的value(若field已存在,则失败) O(1) |
复杂度总结
| 命令 | 复杂度 |
|---|---|
| hget hset hdel | O(1) |
| hexists | O(1) |
| hincrby | O(1) |
| hgetall hvals hkeys | O(n) |
| hmget hmset | O(n) |
列表
特点
- 有序(根据插入顺序得到遍历顺序)
- 可以重复
- 左右两边都可以插入和弹出
API
列表的API都以L开头
增
1 | 1. 从列表右端插入值 O(1) |
删
1 | 1. 从列表左侧弹出一个item O(1) |
1 | 3. 根据count值,从列表中删除所有value相等的项 O(n) |
1 | 4. 按照索引范围修剪列表 O(n) |
查
1 | 1. 获取列表指定索引范围所有item O(n) |
1 | 2. 获取列表指定索引的item O(n) |
1 | 3. 获取列表长度 O(1) |
改
1 | 1. 设置列表指定索引值为newValue O(n) |
其他
1 | 1. lpop阻塞版本,timeout是阻塞超时时间,timeout=0为永远不阻塞 O(1) |
TIPS
- LPUSH + LPOP = Stack
- LPUSH + RPOP = Queue
- LPUSH + LTRIM = Capped Collection
- LPUSH + BRPOP = Message Queue
实战
- TimeLine
实战
记录网站每个用户个人主页的访问量
1
hincrby user:1:info pageview count
缓存视频的基本信息(数据源在mysql中)伪代码
1
2
3
4
5
6
7
8
9
10
11
12public VideoInfo get(long id){
String redisKey = redisPrefix + id;
Map<String, String> hashMap = redis.hgetAll(redisKey);
VideoInfo videoInfo = transferMapToVideo(hashMap);
if(videoInfo == null){
videoInfo = mysql.get(id);
if(videoInfo != null){
redis.hmset(redisKey, transferVideoToMap(videoInfo));
}
}
return videoInfo;
}
单线程架构
Redis在同一时刻只会执行一条命令
单线程为什么这么快
纯内存
非阻塞IO
避免线程切换和竞态消耗
拒绝长(慢)命令
keys, flushall, flushdb, slow lua script, mutil/exec, operate big value(collection)
其实不是单线程
fysnc file descriptor
close file descriptor
Redis客户端
Java客户端:Jedis
获取Jedis
- 添加
Maven依赖
1 | <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> |
Jedis直连(TCP连接)
1
2
3Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.set("hello","world");
String value = jedis.get("hello");Jedis(String host, int port, int connectionTimeout, int soTimeout)- host : Redis节点所在机器的IP
- port : Redis节点的端口
- connectionTimeout : 客户端连接超时时间(内部使用socket技术)
- soTimeout : 客户端读写超时时间
Jedis基本使用
Jedis连接池使用
简单使用
1 | // 初始化Jedis连接池,通常来讲JedisPool是单例的。 |
| 优点 | 缺点 | |
|---|---|---|
| 直连 | - 简单方便 - 适用于少量长期连接的场景 |
- 存在每次新建/关闭TCP开销 - 资源无法控制,存在连接泄露的可能 - Jedis对象线程不安全 |
| 连接池 | - Jedis预先生成,降低开销使用 - 连接池的形式保护和控制资源的使用 |
相对于直连,使用相对麻烦,尤其在资源的管理上需要很多参数来保证,一旦规划不合理也会出现问题。 |
python客户端:redis-py
源码安装
1 | wget https://github.com/andymccurdy/redis-py/archive/3.0.0.zip |
简单使用
1 | import redis |
Go客户端
1 | c,err := redis.Dial("tcp", "127.0.0.1:6379") |
瑞士军刀Redis
慢查询
生命周期
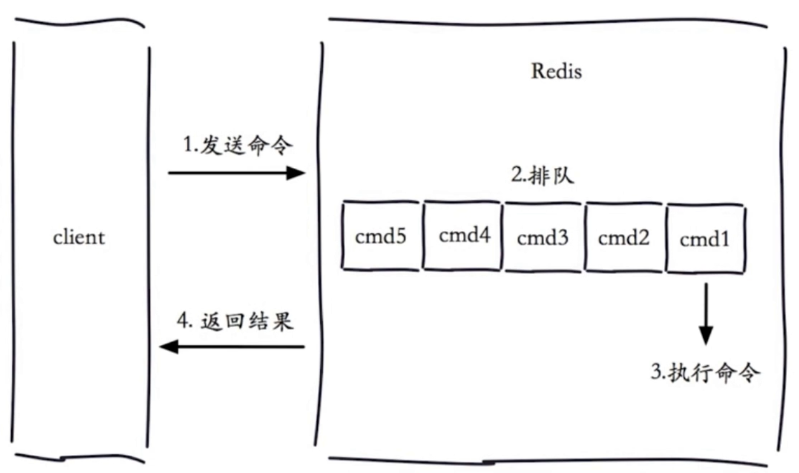
- 慢查询发生在第三阶段
- 客户端超时不一定是慢查询导致的,慢查询只是导致客户端超时的一个可能因素
两个配置
slowlog-max-len
- 先进先出队列
- 固定长度
- 保存在内存内
slowlog-log-slower-than
- 慢查询阈值(单位:微妙,1毫秒等于1000微秒)
- slowlog-log-slower-than=0,记录所有命令
- slowlog-log-slower-than<0,不记录任何命令
配置方法
- 默认值
- config get slowlog-max-len = 128
- config get slowlog-log-slower-than = 10000
- 修改配置文件后重启(适用于未启动时)
- 动态配置
- config set slowlog-max-len 1000
- config set slowlog-log-slower-than 1000
三个命令
- slowlog get [n] :获取慢查询队列
- slowlog len :获取慢查询队列长度
- slowlog reset :清空慢查询队列
运维经验
- slowlog-max-len不要是指过大,默认10ms,通常是指1ms
- slowlog-log-slower-than不要设置太小,通常设置1000左右
- 理解命令生命周期
- 定期持久化慢查询
pipeline
什么是流水线
流水线就是一次网络连接里传输一批命令,节省网络传输时间
| 命令 | N个命令操作 | 1次pipeline |
|---|---|---|
| 时间 | n次网络 + n次命令 | 1次网络 + n次命令 |
| 数据量 | 1条命令 | n条命令 |
注意:
- Redis的命令时间是微秒级别。
- pipeline每次条数要控制(网络)。
客户端实现 pipeline-Jedis
1 | // before pipeline |
1 | // after pipeline |
与原生M操作做对比
M操作是原子操作,pipeline是非原子操作。
使用建议
- 注意每次pipeline携带数据量
- pipeline每次只能作用在一个Redis节点上
- M操作与pipeline区别
发布订阅
角色
- 发布者(publisher)
- 订阅者(subscriber)
- 频道(channel)
模型
Redis server中有各个频道。
发布者向频道中发布消息
订阅者收到其所订阅频道的消息,只能收到订阅时刻之后的消息,之前的收不到。

需要注意的是,redis没有消息堆积的能力。
API
publish
1 | publish channel message |
eg:
1 | publish sohu:tv "hello world" |
subscribe
1 | subscribe [channel] # 一个或多个 |
unsubscribe
1 | unsubcribe [channle] # 一个或多个 |
其他
1 | 1. 订阅模式 |
发布订阅与消息队列
发布订阅是所有订阅者可以收到所有的消息
消息队列是订阅者要进行消息抢夺,一条消息只有一个订阅者能够抢到。
Bitmap
位图
| b | i | g |
|---|---|---|
| 01100010 | 01101001 | 01100111 |
相关命令
1 | 1. 给位图指定索引设置值 |
独立用户统计
- 使用set和Bitmap
- 总共1亿用户,每日5千万独立访问。
| 数据类型 | 每个userid只用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| set | 32位 (假设userid用的是整型, 实际很多网站用的是长整型) |
50,000,000 | 32位*50,000,000=100MB |
| Bitmap | 1位 | 100,000,000 | 12.5MB |
| 一天 | 一个月 | 一年 | |
|---|---|---|---|
| set | 200M | 6G | 72G |
| Bitmap | 12.5M | 375M | 4.5G |
如果只有10万对立用户:
| 数据类型 | 每个userid占用空间 | 需要存储的用户量 | 全部内存量 |
| ——– | —————— | —————- | ———————- |
| set | 32位 | 1,000,000 | 32位1,000,000=4MB |
| Bitmap | 1位 | 100,000,000 | 1位100,000,000=12.5MB |
使用经验
- type=string,最大512MB
- 注意setbit时的偏移量,可能有较大耗时
- 位图不是绝对好。
HyperLogLog
是否是新的数据结构
- 基于 HyperLogLog 算法:极小空间完成独立数量统计。
- 本质还是字符串
三个命令
向 hyperloglog 添加元素
1
pfadd key element [element ...]
计算 hyperloglog 的独立总数
1
pfcount key [key ...]
合并多个 hyperloglog
1
pfmerge destkey sourcekey [sourcekey ...]
内存消耗
使用经验
- 存在错误率(0.81%)
- 无法取出单条数据
GEO
GEO是什么
GEO(地理信息定位):存储经纬度,计算两地距离,范围计算等。
5个城市经纬度
| 城市 | 经度 | 纬度 |
|---|---|---|
| 北京 | 116.28 | 39.55 |
| 天津 | 117.12 | 39.08 |
| 石家庄 | 114.29 | 38.02 |
| 唐山 | 118.01 | 39.38 |
| 保定 | 115.29 | 38.51 |
相关命令
1 | 1. 添加地理位置信息 |
相关说明
- since 3.2+
- type geoKey = zset
- 没有删除 API:zrem key member
持久化
持久化的作用
(1)什么是持久化
redis 所有数据保存在内存中,对数据的更新将异步的保存到磁盘上。
(2)持久化的实现方式
- 快照
- MySQL Dump
- Redis RDB
- 写日志
- MySQL Binlog
- Hbase Hlog
- Redis AOF
RDB
(1)什么是RDB
redis 通过命令创建 RDB 文件(二进制)保存在硬盘中。当 redis 重启时通过命令将 RDB 文件载入到内存。实质是一个复制媒介。
(2)触发机制-主要三种方式
save(同步)
- 新文件将会替换老文件
- 复杂度位 O(n)
bgsave(异步)
利用 Linux fork() 异步执行
文件策略及复杂度与 save 相同
命令 save bgsave IO类型 同步 异步 阻塞 是 是(阻塞发生在fork) 复杂度 O(n) O(n) 优点 不会消耗额外内存 不阻塞客户端命令 缺点 阻塞客户端命令 需要fork,消耗内存
自动
redis 提供了 save 配置
配置 seconds changes save 900 1 save 300 10 save 60 10000 满足任意一个条件,redis 会自动创建(bgsave)RDB 文件
默认配置:
1
2
3
4
5
6
7
8save 900 1
save 300 10
save 60 10000
dbfiename dump.rdb
dir ./
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbcheksum yes最佳配置:
1
2
3
4
5dbfilename dump-${port}.rdb
dir /bigdiskpath
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbcheksum yes
(3)触发机制-不容忽视方式
1. 全量复制
2. debug reload
3. shutdown (4)总结
1. RDB是 Redis 内存到硬盘的快照,用于持久化。
2. save 通常会阻塞 Redis
3. bgsave 不会阻塞 Redis,但是会 fork 新进程。
4. save 自动配置满足任意一个条件就会被执行。AOF
RDB 现存问题
耗时,耗性能
O(n): 耗时
fork(): 消耗内存,copy-on-write 策略
Disk I/O: IO 性能
不可控,丢失数据
什么是 AOF
每执行一条命令,就将该命令写入到 AOF 日志文件中。
AOF 三种策略
(1)always
每条写命令都会出发刷新,将缓冲区的命令日志刷新到 AOF 文件中。
(2)everysec
每秒(默认值)刷新一次
(3)no
由操作系统决定什么时候刷新。
| 命令 | always | everysec | no |
|---|---|---|---|
| 优点 | 不丢失数据 | 每秒一次 fsync 丢失一秒数据 |
不用管 |
| 缺点 | IO 开销较大,一般的 sata 盘只有几百 TPS | 丢失1秒数据 | 不可控 |
AOF 重写
| 原生 AOF | AOF 重写 |
|---|---|
| set hello world set hello java set hello hehe incr counter incr counter rpush mylist a rpush mylist b rpush mylist c 过期数据 |
set hello hehe set counter 2 rpush mylist a b c |
AOF 重写的作用:
- 减少磁盘占用量
- 加速恢复速度
AOF 重写的两种实现方式
berewriteaof
AOF 重写配置
配置名 含义 autoaof-rewrite-min-size AOF 文件重写需要的尺寸 auto-aof-rewrite-percentage AOF 文件增长率 统计名 含义 aof_current_size AOF 当前尺寸(单位:字节) aof_base_size AOF 上次启动和重写的尺寸(单位:字节) 自动触发时机:
- aof_current_size > auto-aof-rewrite-min-size
- aof_current_size - aof_base_size / aof_base_size > auto-aof-rewrite-percentage
AOF 重写流程
![]()
常用配置:
1
2
3
4
5
6
7appendonly yes
appendfilename "appendonly-${port}.aof"
appendfsync everysec
dir /bigdiskpath
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb

RDB 和 AOF 的抉择
RDB 和 AOF 比较
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 丢数据 | 根据策略决定 |
| 轻重 | 重 | 轻 |
RDB 最佳策略
- “关”
- 集中管理
- 主从,从开
AOF 最佳策略
- ”开“:缓存和存储
- AOF 重写集中管理
- everysec
最佳策略
- 小分片
- 缓存或者存储
- 监控(硬盘、内存、负载、网络)
- 足够的内存
开发运维常见问题
fork 操作
- 同步操作
- 与内存量息息相关:内存越大,耗时越长(与机器类型有关)
- info: latest_fork_usec 查询上一次 fork 的时间
如何改善fork
- 优先使用物理机或者高效支持 fork 操作的虚拟化技术
- 控制 Redis 实例最大可用内存:maxmemory
- 合理配置 Linux 内存分配策略:vm.overcommit_memory = 1
- 降低 fork 频率:例如放宽 AOF 重写自动触发时机,不必要的全量复制
进程外开销
子进程开销和优化
- CPU:
- 开销:RDB 和 AOF 文件生成,属于 CPU 密集型
- 优化:不做 CPU 绑定,不和 CPU 密集型部署
- 内存:
- 开销:fork 内存开销,copy-on-write。
- 优化:echo never > /sys/kernel/mm/transparent_hugepage/enabled
- 硬盘
- 开销:AOF 和 RDB 文件写入,可以结合 iostat,iotop 分析
- 优化:
- 不要和高硬盘负责服务部署在一起:存储服务、消息队列等
- no-appendfsync-on-rewrite = yes
- 根据写入量决定磁盘类型:例如 ssd
- 单机多实例持久化文件目录可以考虑分盘
AOF追加阻塞

AOF 阻塞定位
Reids 日志:
Asynchronous AOF fsync is taking too long (disk is busy?).
Writing the AOF buffer without waiting for fsync to complete,this may slow down Redis.
info Persistence:
…
aof_delayed_fsync: 100
…
单机多实例部署
Redis 复制的原理与优化
什么是主从复制
(1)单机有什么问题?
机器故障
容量瓶颈
QPS 瓶颈
(2)作用
数据副本
扩展读性能
复制的配置
两种实现方式
slaveof 命令
配置
1
2slaveof ip port
slave-read-only yes
全量复制和部分复制
查看 run_id
1 | redis-cli -p 6379 info server | grep run |
查看偏移量
1 | redis-cli -p 6379 info replication |
全量复制开销:
- bgsave 时间
- RDB文件网络传输时间
- 从节点清空数据时间
- 从节点加载 RDB 的时间
- 可能的 AOF 重写时间
故障处理
开发运维常见问题
读写分离
将读流量分摊到从节点
可能遇到的问题:
- 复制数据延迟
- 读到过期数据
- 从节点故障
主从配置不一致
规避全量复制
- 第一次不可避免
- 系欸但运行 ID 不匹配
- 主节点重启
- 故障转移
- 复制积压缓冲区不足
- 网络中断,部分复制无法满足
- 增大复制缓冲区配置 rel_backlog_size,网络“增强”。
规避复制风暴
- 单主节点复制风暴
- 问题:主节点重启,多从节点复制
- 解决:更换复制拓扑
- 单机器复制风暴
- 机器宕机后,大量全量复制
- 主节点分散多机器
- 单主节点复制风暴
Redis Sentinel
主从复制高可用存在的问题
- 手动故障转移
- 写能力和存储能力受限
架构说明
客户端不直接访问 redis,而是通过 sentinel 来访问。由 sentinel 来负责主从节点的管理。
安装配置
sentinel 的默认端口为 26379
- 配置开启主从节点
- 配置开启 sentinel 监控主节点(sentinel 是特殊的 redis)
客户端连接
请求相应流程
jedis
1 | JedisSentinelPool sentinelPool = new JedisSentinelPool(masterName, sentinelSet, poolConfig, timeout); |
redis-py
实现原理
常见开发运维问题
Redis Cluster
呼唤集群
- 超高并发量需求
- 超大数据量需求
数据分布
顺序分布
哈希分布
- 节点取余
- 使用多倍扩容降低迁移率
- 一致性哈希
- 顺时针取余
- 只影响邻近节点
- 扩容后会存在负载不均衡的情况
- 虚拟槽
- 每个槽映射一个数据子集
- 良好的哈希函数:例如 CRC16
- 服务端管理节点、槽、数据:例如 Redis Cluster
| 分布方式 | 特点 | 典型产品 |
|---|---|---|
| 哈希分布 | 数据分散度高 键值分布业务无关 无法顺序访问 支持批量操作 |
一致性哈希 Memcache Redis Cluster |
| 顺序分布 | 数据分散度易倾斜 键值业务相关 可顺序访问 不支持批量操作 |
BigTable HBase |
搭建集群
集群伸缩
客户端路由
集群原理
开发运维常见问题
Redis Cluster 架构
- 节点
- meet
- 指派槽
- 复制
Redis Cluster 特性
- 复制
- 高可用
- 分片
两种安装方式
原生命令安装
配置开启节点
1
2
3
4
5
6
7port ${port}
daemonize yes
dir "/opt/redis/data"
dbfilename "dump-${port}.rdb"
logfile "${port}.log"
cluster-enabled yes
cluster-config-file nodes-${port}.confmeet
1
cluster meet ip port
指派槽
1
cluster addslots slot [slot ...]
分配主从关系
1
cluster replicate node-id